A mutex or lock is simply an object used by multiple threads to keep track of whether a resource can be accessed or not. This allows us to guarantee mutual exclusion when different threads attempt to access the same resource. Mutexes come in two flavors:
Let's attempt to use a blocking mutex in our pipe implementation. More specifically, when writing characters to a pipe, we want to lock the pipe to make sure that nobody else can write or read while we're filling the buffer with data, and we want to use a blocking mutex to lower the overhead of locking.
// Here is our pipe struct, with a blocking mutex
struct pipe {
bmutex_t b;
char buf[N];
size_t r,w;
}
// Before writing to the pipe, we enter a loop and acquire a lock on the
// pipe. If the pipe is not full (p>w - p>r != N) we break from the
// loop; otherwise, we unlock and keep looping until this condition becomes
// true.
void writec(struct pipe *p, char c) {
// We loop until the pipe is not full.
for(;;) {
acquire(&p->b); // Here, the process might block!
if(p->w - p->r != N)
break;
release(&p->b);
}
// Now that we have a lock and the pipe is not full, we copy a character
// into the buffer.
p->buf[p->w++%N] = c;
// Finally, we release the lock.
release(&p->b);
}
We're still polling the pipe for a condition even though we have a blocking mutex! But we're using a blocking mutex precisely because we want to avoid polling.
We'd ideally want a variable that is only true when the condition
p->w - p->r != N is true.
In functional languages, this might be expressed as (lambda() p->w
- p-> r != N).
We'd also want some sort of "ideal system call" that would put the current process to sleep until this variable becomes true.
For example, one nice system call might be waitfor("p->w - p->r != N").
Unfortunately, without hardware support these features are impossible to implement. However, we can come up with a good approximation...
While there's no way we can have a variable that becomes magically true when a certain condition is satisfied, we can still have some variable that is set to true when we satisfy this condition. This forms the basis of using condition variables:
A condition variable stands for a boolean expression of interest. We want a condition variable to have the following properties:
Sounds like exactly what we need. But what's the catch? It's the caller's responsibility to guarantee that this intended property actually works on the machine level. That is, when the boolean expression changes, we need to manually set the condition variable to true or false.
In order for a condition variable to work correctly, we need:
What should the API surrounding our condition variable look like? We need a function that blocks the thread while the condition is false, and a function that wakes up waiting processes when the condition becomes true.
wait(contvar_t *c, bmutex_t *b);
// PRECONDITION: We have acquired b.
// ACTION:
// Releases b, then blocks until some other thread notifies us
// that condition MIGHT have changed. <-- Race condition occurs here.
// Reacquires b
// Returns
notify(condvar_t *c);
// ACTION: Notifies one waiting thread that condition MIGHT have become true.
broadcast(condvar_t *c); (OR notify_all(condvar_t *c);)
// ACTION: Notifies ALL threads that condition MIGHT have become true.
Condition variables are easy in Java, as these functions are already implemented in the Condition class
(use lock.newCondition() to declare one!).
Now that we know better, let's rewrite write!
struct pipe {
// New conditional variables to use in conjunction with blocking mutex
condvar_t nonfull;
condvar_t nonempty;
bmutex_t b;
char buf[N];
size_t r,w;
}
void writec(struct pipe *p, char c) {
for(;;) {
acquire(&p->b);
// This releases b, waits until notify() is called on it,
// then reacquires b
wait(&p->b, &p->nonfull);
if(p->w - p->r != N)
break;
release(&p->b);
}
p->buf[p->w++%N] =c;
// We now need to notify the read end that there's data in the buffer!
notify(&p->nonempty);
release(&p->b);
}
Some important observations to keep in mind:
notify() AFTER release() we would get
a performance bug (not a fatal one) since we would wake up people we shouldn't.
(This is due to a race condition: a different reader might acquire and read the
data before we notify our intended reader, and as a result, the reader that we
do eventually notify will need to go back to sleep and wait.)for(;;) loop around the
wait() call because of the fact that returning from this call
indicates that there MIGHT be a nonfull buffer--it's a notice, not a
guarantee.Even with perfect mutual exclusion, we can still run into some very hairy problems when two threads or processes need to share the same resource. In fact, these problems arise as a result of using mutual exclusion, and are known as deadlocks:
Deadlock can occur in any number of places where multiple threads need access
to the same resource. For example, consider this implementation of cat:
... | cat | ...
Here, this implementation uses one read(0,...); call to read from
standard input and uses one write(1,...); call to write to standard
output. Is there any way to combine the two system calls into one to improve
performance? The newly combined system call might look like xfer(0,1,nbytes);
We need to lock the two data structures in order to initiate transfer, which introduces the problem of deadlock. For example:
PROCESS 1: xfer(0,1,nbytes); // Grab a lock on 0, then grab a lock on 1
PROCESS 2: xfer(1,0,nbytes); // Grab a lock on 1, then grab a lock on 0
// ......deadlock!
Deadlock comes up in overly complicated systems, and is typically a race condition. There are FOUR PRECONDITIONS for deadlock:
How do we detect circular wait? Use a Resource Allocation Graph (RAG), also known as a Dependency Graph.
Any cycle on the graph corresponds to a cycle of dependencies. Assuming the other three conditions are satisfied, this creates deadlock.
Thus, one solution to preventing deadlocks is to manage a dynamic RAG of currently running threads and active resources, and refuse lock requests that would create a cycle in the RAG.
-EDEADLK.In an ordered-lock system, every process must obtain the locks it needs in some arbitrary numeric order. If for some reason a process can't obtain all the locks at once (because some lock is taken by a different process), it must give up all locks and try again later.
In this case, we implement ONLY the correct pattern of locking in our threads. If you know the pattern will never generate a cycle, then we don't have to worry about checking for deadlock.
For example, we might want to manually manage locking of pipes between a parent and a child process:
parent
| ^
V |
child
To avoid deadlocks, we must guarantee that the parent process reads only after writing all data, and the child process writes only after reading all data.
In general, this approach does NOT work since finding a pattern that never deadlocks is much harder than simply detecting deadlock when it occurs.
We could preempt processes that hold locks if they take too long to complete, but this isn't a particularly nice option. In some sense it defeats the purpose of having locks in the first place, since we now can no longer guarantee a particular process that it has full control of a resource after grabbing a lock on it, and we might run into nasty race conditions.
We could also break hold-and-wait by simply denying requests made by a single process for multiple locks. While this still allows us to guarantee to a process holding a lock that it has exclusive control of the associated resource, it severely limits what threads can do since no thread can have more than one resource open at a time.
This is a non-obvious bug that arises from two seemingly unrelated features: locks and priority scheduling.
Assume we have a blocking mutex and three threads running: one with low priority, one with high priority, and one with medium priority. They each need to acquire the blocking mutex at some point.
| Tlow | Tmed | Thigh |
| Runnable | Waiting | Waiting |
| acquire(&m); (some short block of code) | ||
| ------- context switch ------> | ||
| Waiting | Waiting | Runnable acquire(&m) |
| <-- context switch -- | ||
| Waiting | Runnable (some long block of code) | Waiting |
A low priority process might grab a lock and execute a little bit of code before a context switch is made by the scheduler to a high priority process in need of attention. This process requires the same lock as the low priority process, so it sleeps until the low priority job releases the lock. Then a context switch is made to a medium-priority process, which takes a long time to perform some menial task.
Why is this bad? A medium priority thread is running while a high priority thread wants to run! There will never be a context switch from the medium priority thread to the low priority thread that holds the lock, so the high priority thread hangs.
One high-profile example of this is a system failure of the Mars Pathfinder in 1997. The low-priority task in this case was an atmospheric measurement suite which acquired a lock on a shared resource, also needed by a high-priority task which managed information between different components of the robot.
If a low-priority thread has a lock needed by the high-priority thread, be sure to temporarily increase the locking thread's priority so it has a chance to complete its code even in the case of a context switch.
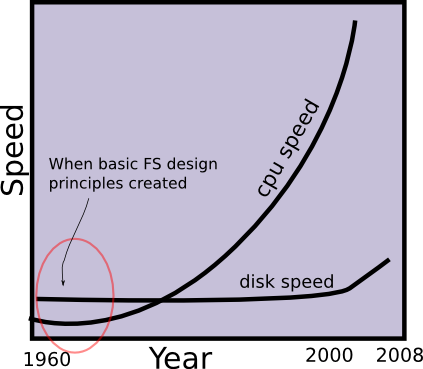
Back in the 1960s, CPUs were very, very slow! One of the fastest computers of the time, the Cray Supercomputer, had a speed of about 80 MFlops. There wasn't a need to worry about disk scheduling as much: the disk was fast enough for the CPU at the time.
Over the next few decades, however, the CPU speed has gone up astronomically, following Moore's law quite reliably; on the other hand, disk speed has stayed relatively constant. As a result, disk scheduling now is a much more important problem than it was back then.
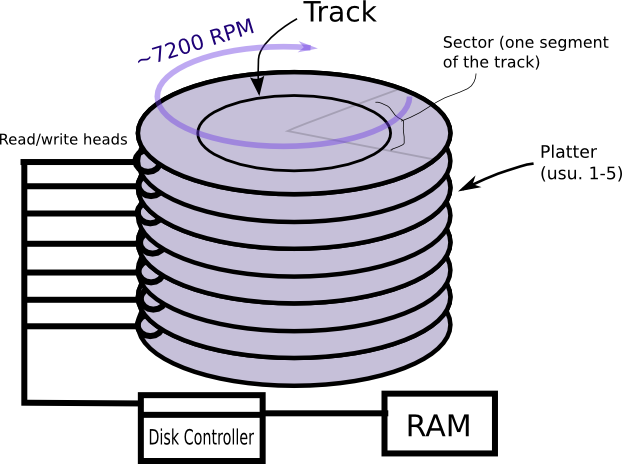
First, let's go over some useful terminology:
The reason behind unimpressive disk speeds lies in the steps that need to be performed in order to retrieve data from disk. There are three main sources of disk latency:
All of these steps tend to be painfully slow compared to CPU speed, since the components of a hard drive tend to be much larger than those of a comparable CPU. Unlike newer technologies like flash memory, hard drives contain moving parts; as a result, there are physical limitations to how fast one can change the momentum of the disk and the read/write head, and these limitations translate into unavoidable latencies.
This drive is typically used for nearline storage, a "bread-and-butter drive" that is used to store secondary data in a data center. This drive is thus better than consumer-grade hard drives, but not fast enough to handle the most frequently accessed stuff in an enterprise cluster. The Barracuda has the following specs:
How much time will it take to read one sector of data from this disk?