CS111 Fall 2008
File System Organization (Nov 4)
By Xiao Lei
What is a File System?
- an on disk data structure that provides an abstraction of a collection of files
We look at some file system examples below:
RT-11 (Real Time) Contiguous Allocation
Disk

Each directory entry stores the file name, the file header, and the size of the file
Pros:
Simple to implement
Predictable
Fast read/write/seek times
Cons:
Directory fills up if there are lots of tiny files
External fragmentation
Disk defragmentation is required after a period of time
Files cannot easily grow (Serious Drawback!)
How do we fix the file growth problem?
Use a Block Structured File System
- Fixed sized blocks
- Whenever we need to grow a file we simple allocate a new block
FAT (File Allocation Table) File System (late 1970’s)
Disk
![]()
The first block is the boot sector (we typically do not touch this block)
The second block is the superblock, which stores information about the disk like
- Version number
- Size of the file system
- Free space remaining
- The location of root
The FAT section stores an array of block numbers:
- -1 means a free block
- 0 means the last block in the containing file (EOF marker)
- Any value greater than 0 represents the block number of the next block of this file
The Data section is consisted of 4kb blocks
For example a file that takes up 4 blocks of data is represented in the FAT file system in the following way:
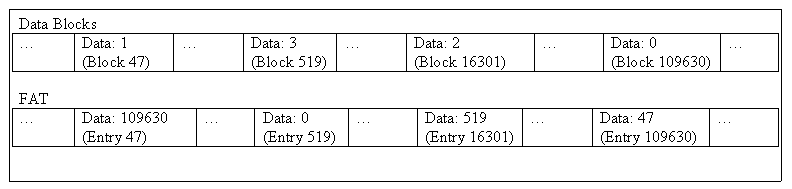
How do we know where the first block of the file starts?
We use a Directory – A file that contains directory entries with the following structure for each entry:
![]()
Pros:
Files can now grow
No external fragmentation
Cons:
Internal fragmentation
Slow and unpredictable performance (Especially if the FAT is not cached)
Taking a look at the Abstraction Layers of a Unix File System
Software Level
- Symbolic Links
- File Name
- File Name Components
- Inode
- File System
Hardware Level
- Partition (Each FS lives in a partition)
- Blocks (Typically 8192 bytes)
- We assume a disk is an array of blocks
- Disk Sectors (512 bytes)
What are some problems with these abstractions?
We look at some security issues:
$rm file – does not actually remove the file (file info is still stored on disk)
We can have a new instruction “$shred file” that overwrites the file’s contents with random data an X number of times, then remove it.
(The reason for multiple writes is that writing on magnetic disks is inaccurate and old information can still be deciphered if the new info does not completely overlap the old info)
- A problem with this approach is that if the file is cached, the writes are only done in RAM, and the file is only overwritten once
- We can fix this by having a special system call to make sure each write is done to the disk
However we are assuming we are always overwriting the old files
Some File Systems allocations new blocks on the fly while writing to optimize performance, but this means the old info still remains on disk!
(We can always shred the entire partition as the safest method to protect our data…)
Another way to protect data is to using an Encrypting File System
All the bytes on disk are encrypted with a secret key, which is kept in RAM only
Pros:
Shredding is trivial – Simply lose the key!
Cons:
Slow
If the key is accidently lost, its too much hassle to retrieve the data
Other Problems to Consider:
If the disk fries, we lose all the data!
We want a File System that can cross partition/disk boundaries!
Why?
- Reliability (RAID – write data to multiple disks)
- A Big File System (If we want to manage say a 1PB File System, we cannot just buy a 1PB hard drive as current technology stands)
- More speed and throughput!
BSD Fast File System (FFS) (~1980)
Disk

The book sector block and superblocks are as before
(Some systems have multiple copies of superblocks scattered across the disk to obtain redundancy)
The block bitmap is an array of bits that tells you which blocks are free
- Each bitmap block tells you about 8192*8 number of blocks, since the free status is represented using only 1 bit
- This is more compact than the FAT system since it uses bit comparisons instead of word comparisons.
The Inode Table contains an array of fixed sized Inodes, each of which describes a file
Big Inode Approach:
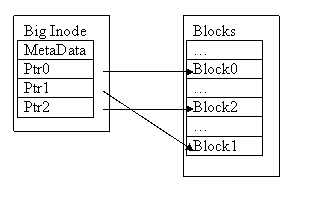
This method is inefficient, as it takes up too much space, and the space will be unused for small files.
Extensible Inode Approach:
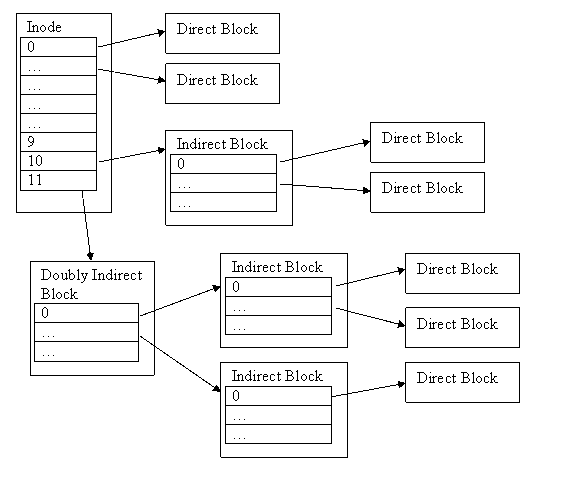
The first 10 pointers directly points to data blocks (direct data blocks)
If the file is bigger than 10 blocks, the 11th pointer points to a indirect data block, which is consisted of pointers to the rest of the blocks
Unix File Systems have doubly indirect data blocks (for even bigger files)
The 12th pointer points to a block of pointers, each of which points to another block of pointers, which then points to the actual data blocks.
We can grow this system of representing files to include triply indirect data blocks!
Pros:
No external fragmentation
Cons:
Internal fragmentation
Directory entries for 1977 Unix:
Files whose contents are Tables

Linux ext3 v2 Directory entry:

Say we call the command “mkdir(“d”)” in our working directory
We allocate an Inode (say #1059)
Our working directory will now contain a directory entry where
Filename = “d”
Filetype = directory
InodeNum = 1059
Hardlinks
Inside each inode metadata there is also a LINK COUNT entry, which counts the number of directory entries pointing to this inode.
For example:
$ cat > a
$ ln a b
$ echo foo > a
$ cat b
OUTPUT: foo
At this point there are two directory entries, with filenames “a” and “b” both having the same inode number, which effectively points to the same file.
(Hardlinks can point from different directories!)
Why have hardlinks?
- Clone directory structures quickly
- Original Unix kernel did not support the rename system call! Instead we use hardlinks to implement the same effect:
- Link(“d/a”, “e/b”)
- Unlink(“d/a”)
- (An advantage to this is to not having to worry about deadlocks)