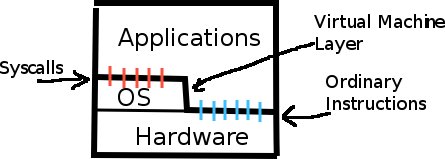
To implement hard modularity, part of the CPU's instruction set is restricted—only executable when a supervision bit is turned on—for example, HALT or INB. This is because these instructions can be misused. To prevent applications and users (who we don't trust) from doing any damage, applications are run with the supervision bit turned off. The operating system (which we trust) on the other hand, has control of the computer and runs with full priviledges. When applcations need something done that requires executing restricted instructions, they have to do so through a system call.
To do a system call, the application executes the INT (interrupt) instruction. The INT instruction takes an operand that tells the OS what system call it is asking for. The INT instruction causes a trap: the application loses control of the Program Counter, the Program Counter jumps to an address determined by the INT operand and the Interrupt Address Table, the supervision bit in turned on, and the OS in now in control. The OS saves the registers before it does anything so it can restore them laterbefore returning control to the application. It pushes the following (among other things) onto the Kernel Stack:
The result of the system call (if any) will be put into a pre-agreed-upon register. Other registers are restored to the way they were before the interrupt. In a sense, from the application's point of view, system calls extend the instruction set of the machine.
The rings represent a hierarchy of priviledges, labelled in ascending order starting from 0 (the most trusted) to 3 (least trusted).
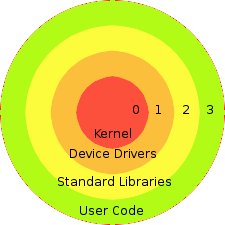
Typically, the kernel of an operating system runs in level 0. Because of this, the kernel should be bug-free; to reduce the complexity of the kernel (and the number of bugs), the kernel typically only manages memory and threading. Device drivers run at level 1. Standard Libraries run at level 2. User code runs at level 3.
The level is part of the Interrupt Address Table, which tells the processor what priviledges the code should be run at.
This many level of protection offers fault tolerance and security, but Unix uses only two levels. Level 0 includes kernel code and device drivers, while level 3 includes libraries and user code. The reason for this model is mostly performance. Everytime when an application needs to access certain resources outside of ring, it has to do an interrupt, which pushes all sorts of registers onto main memory, then it is loaded back to the CPU. Less levels mean more cost-effectiveness.
In the typical model, when code running at a level fails (e.g. throws an exeption) it affects the levels above, but not below. But another reason for the Unix model is that any major faults, no matter if they are recoverable or not, will result in a much-degraded system for the user.
How may an unreliable program break systems?
|
Two ways to implement system calls
|
OS organization using virtualization
|
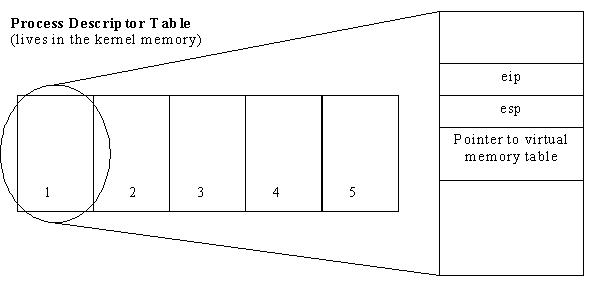
The process descriptor table is an array stored in the kernel memory that essentially holds the virtual registers of all processes not currently running. This data includes the stack pointer (%esp), the instruction pointer (%eip) and the pointer to the virtual memory table. Seen below is a diagram showing how the process descriptors are stored. Each process is stored in order based on its process id (pid_t).
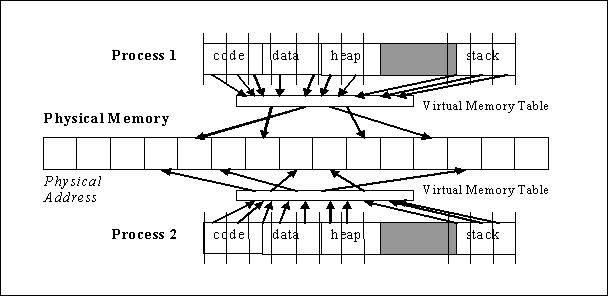
The virtual memory allows a process to see a contiguous segment of memory that is actually spread out around the physical memory. Each process owns its own virtual memory table (whose pointer is stored in the process descriptor table) that maps a virtual address to an actual physical address. The operating system segments each processes' code, data, heap, and stack into smaller segments called "pages", which are then stored separately into the physical memory. In this way, multiple processes can be stored throughout the physical memory without having to actually be stored continuously. Seen below is a diagram showing the layout of processes in relation to its physical memory.
Claim 1: Use syscalls for all input/output
Counterexample: Graphics need to access display without having to constantly use system calls. So: use syscalls to set up access.
Claim 2: Single interface works well for all devices because "they're all alike" at some level
Counterexample:

One of the most fundamental functions of an operating system (OS) must perform is to give applications access to the resources of the computer. However, different computers can have quite different hardware, so it becomes a challenging engineering problem to give applications access to these resources in a uniform fashion. Unix's big idea is to provide access to all hardware devices using the same interface it does for files: file descriptors.
Unix uses file descriptors as an abstraction for doing I/O operations on files. When a file is created or opened Unix returns a file descriptor associated with that file. While the file remains open manipulating this file descriptor become equivalent to manipulating the file itself. File descriptors provide a simple interface for reading data from files, writing data to them, or moving about within them. The Unix application interface protocol (API) provides 3 main functions to perform these tasks:
ssize_t read(int fd, char *buffer, size_t sizeBuf)
This function reads data from the file descriptor fd and
places it in the memory pointed to by buffer. The
sizeBuf argument specifies the maximum amount of data which
can be written to memory at buffer. If the function executes
correctly the number of bytes read will be returned.
ssize_t write(int fd, const char *buffer, size_t sizeBuf)
write() writes data to the file descriptor fd. The
function reads sizeBuf bytes from the memory pointed to by
buffer and writes that data to fd. If no error
occurred the function returns the number of bytes written.
off_t lseek(int fd, off_t offset, int flags)
This function changes the file descriptor fd's "position"
in the file. Both the read() and write() require a position within the
file to work. If the file is longer than sizeBuf bytes the read()
function must know which sizeBuf bytes to read. Similarly the write()
function must know where in the file to write data to. This function
allows one to shift the current position in the file by
offset bytes. The flag argument specifies the
starting point of the shift. There are 3 possible values:
SEEK_CUR causes the shift to occur relative to the
current position in the fileSEEK_SET causes the shift to occur relative to the
beginning of the fileSEEK_END causes the shift to occur relative to the end
of the file. Using argument with non-zero offset value
basically writes offset bytes of zeros to the end of the
file.If no errors occur the function returns the number of bytes the
position in the file was advanced. This can be less than
offset if the end of the file was encountered and
flags was not SEEK_END.
All 3 of these functions return -1 and modify the value of
errno if an error occurred during execution. The
errno value indicates the nature of the error and the values it
takes are standardized in the Unix API.
Most hardware devices exist to read or write data in a more human-friendly format, so extending the file descriptor API to cover hardware as well seems like a logical and elegant solution to the problem of give applications standardized access to operating system resources. Using the file descriptor abstraction one can now simply think of the keyboard, mouse, CD-ROM drive, monitor, etc. as special files. However there is still a question of how much of an abstraction file descriptors should be. A file descriptor could simply be a memory address: an application writes to that address and something happens. Such a low-level access would have very little overhead for Unix and be extremely simple, so much so the above file descriptor API might not even be needed. However, this would also give little security cause race conditions if multiple applications where using the same file descriptor. A better solution is to make file descriptors opaque handlers. Another object, a file object, does all the actual work of manipulating the file. But all an application sees is an opaque reference to the file object: a file descriptor. An application is constrained to use the Unix API with the file descriptor and it always separated from the file object itself. While this requires more overhead, it gives greater security and guards against low-level race conditions if multiple applications use the same file or device. For these reasons Unix uses the opaque file descriptor model.
File descriptors can be implemented in many ways. This section covers the way that Unix choose to implement it's file descriptors. It first provides an overview of how Unix keeps track of file descriptors internally and then moves on to outline several important Unix conventions regarding file descriptors.
Unix file descriptors have type int. This int
that Unix uses as a file descriptor is an index into the file descriptor
table. By convention initially index 0 is always stdin, 1 is always stdout,
and 2 is always stderr in the table. The file descriptor table itself
contains pointers to the file objects which do all the resource handling.
Each process (a process being an instance of an application) has it's own
file descriptor table which is pointed to by an entry in it's process
description table. If a process calls fork() it's file
descriptor table is copied from the parent's file descriptor table with the
exception of the first 3 indexes (stdin, stdout, stderr). If a process call
execvp() the process retains it's file descriptor table.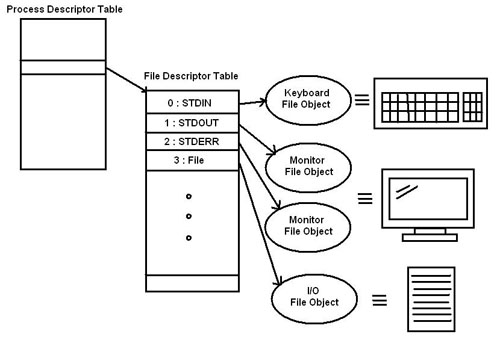
File descriptors where initially designed to work with files, which are
non-streaming. However, many hardware devices such as keyboards, trackballs,
and network connections are streaming. Data comes in at a constant rate and
it is impractical to save more than a small piece of it (that data which just
came in) at a time. For such devices the lseek() function makes
little sense. By convention Unix does not prevent an application from calling
lseek() on such devices, but the call will always return -1. A
good test to see if a file descriptor is associated with a streaming device
is to call lseek() on it and see if it fails for no apparent
reason.
In Unix several processes can access the same file object at once or in
sequence using different file descriptors. If all those processes wish to do
reads and writes in a synchronized manner a coonvention must be chosen:
either the file descriptor can keep track of the process's position in the
file or the file object can keep track of the process's position in a file.
Both ways have their advantages. If the file descriptor keeps track of the
process's position in the file, then several processes can read from
different places in the file at once (ignore the race condition of several
processes writing at once). However, once a process has finished and it's
file descriptors are freed the position information is lost. If the file
object keeps the current position in a file then all the processes have to
share that position, but the position stays the same if any one process
exits. Unix goes with the latter convention because functions like
fork() and execvp() make more sense if they begin
reading or writing information where the parent process left off.