October 9 Scribe notes by
Drew Wilder-Goodwin
Karthik Ravi Shankar
Swaminathan Balasubramanian
Matthew Harriman
The interface lives between the OS and applications. We want to find good (orthogonal) operating system interfaces. If the interface is orthogonal, choices should be able to be made independent of other choices (i.e. choice of X will not break Y and Z). You can picture these decisions as living on a three dimensional axis (X,Y,Z).
Of course, other engineering constraints also still apply:
$ date 2008-10-09 14:08:00 -0700
How does this and other standard unix programs implemented? There are two parts to this question:
date.c:
int main (int argc, char **argv) {
clock_gettime(....); // these calls could potentially fail.
localtime(....); // if they do, will print an error
printf(....); // and return 1 (the exit status).
return 0; // 0 is exit status for success.
// Exit status is up to 8 bits.
}
In our example above, argc is 1 and argv is a vector containing a string of the command being executed (["date"]). Now with an argument:
$ date -u # (universal time) 2008-10-09 21:08:00 -0000
argc is 2 and argv contains ["date","-u"].
The operating systems job is to make the main() function in date.c run when the date program is executed. To create the executable in the first place, you must have previous run something like:
gcc date.c -o date
So now you can simply run the executable, but how does the operating system know how to get from $ date and into the main() function in date.c?
Inside the compiled date executable file is a bunch of binary data, and inside that binary data is machine code that implements the instructions of the program, including the main() function. At the top of the file there is a magic header that says 'I am executable, and to execute me start here', with a pointer to main(). When you run a file in unix, the OS dumps this file into RAM and sets the program counter (PC) to the appropriate place. When you get to main(), the process is already running. At the end, it returns the exit status. The operating system is ACTUALLY doing a subroutine call:
char **buf = {"date", "-u", NULL};
exit(main(2,buf));
It arranges for there to be a return address on the top of the stack. Exit's with mains return value. Exit is a syscall defined this way:
void exit(int);
Exit does cleanup (flush buffers, other internal cleanup, etc), tells the OS to nuke this process, and informs other interested processes of the exit status. There are multiple flavors of exit(). Here is another:
void _exit(int); // nukes current process without cleanup
The convention in unix is that stuff that starts with underscore is 'dangerous,' more direct. In this case, for example, _exit() does the same thing as exit() but skips the cleanup.
From the point of view another application using date: If we just execute the main() function in date.c directly, it will print out the date and return 0 and the process will die. So, we can't invoke directly. Instead we must create a delegate (a child process), so our process will not die when date finished and will be insulated from 'mistakes' (errors) that might be made by date.
Here is a short c function that calls date (equivalent to what the shell executes when calling date):
void printdate(void) {
pid_t p = fork(); // create a new process (clone current process)
// you can only tell who you are by looking at p
// pid > 0 means you're the parent
// pid == 0 means you're the child
// pid < -1 error
if (p < 0)
error(); // does the right thing to handle the error,
// assumption is that error does NOT return
// we can now assume p is non-negative
if (p == 0) { // in child
// in the real world, more stuff happens here before the call to
// execvp(). for example, you may want child to have a different
// environment e.g. opening a different file, changing values of
// pointers/variables ... this lends to orthogonality
char **args[3] = {"/usr/bin/date", "-u", 0} // 0 == NULL
execvp("/usr/bin/date",args);
// if we get here, execvp() must have failed for whatever reason
error();
}
// we now know this is the parent
// we want to know if our child process succeeded
int status;
if (waitpid(p, &status, 0) < 0)
error();
// status is now set to exit status
// WIFEXITED macro succeeds if exit status is good
// WEXITSTATUS is non zero if exit status is non zero
// WIFEXITED macro should be executed before WEXITSTATUS
if (!WIFEXITED(status) || WEXITSTATUS(status))
error();
}
To some extent we are insulated from bugs in date program: if there is an error, we won't crash, instead we will call error function. However, we have not insulated ourselves from every problem. Suppose date goes into infinite loop, what will happen? Our call to waitpid will hang.
Some function definitions:
void exit(int);
void _exit(int);
int main(int, char**);
pid_t fork(void);
int execvp(char const *, char *const*); // if it returns success,
// your program does not exist any more
pid_t waitpid(pid_t, int *, int); // returns process id of process you've
// successfully waited for
// (or -1 for something bad happened)
The unix way of handling forking seems like a lot of work, are there other ways? In Windows, there is a single function that does both the fork() and execvp(). This function is posix_spawnvp():
int posix_spawnvp(
pid_t *restrict pid, // restrict says buffer for pid
// does not overlap
// (see restrict sidebar)
posix_spawn_file_actions const *acts, // acts is pointer to data structure that
// tells the operating system everything
// it should do between the fork and exec
posix_spawn_attr_t_const* restrict,
char *const* restrict argv, // arguments
char *const* restrict envp // specifies environment of process
);
As we can see, it's a bit complicated so it fails our 'simple' test under orthogonality.
Instead of the previously discussed methods, we could do the following:
system("date -u")
This is like the printdate() function above, but it evokes the shell and passes argument "date -u" to the shell. This is a convenience function, and we should not use this for our purposes in this class.
Pipes are bounded IO buffer, intended for interprocess communication (IPC). Here is an example of a pipe being used in the shell:
$ du | sort -n # see a sorted list
# of subdirectories
# and number of blocks
# used by each
3939949493 ./junk
....
The concept of pipes is central to unix. The du program is sending it's STDOUT to the STDIN of sort, while the two programs are running "at the same time" (especially if on a multi core machine, in which case they may literally be running at the same time). This leads to a lot of efficiencies because sort can start to process while du is still working (i.e. sort does does not have to wait for du to finish in order to start it's own work).
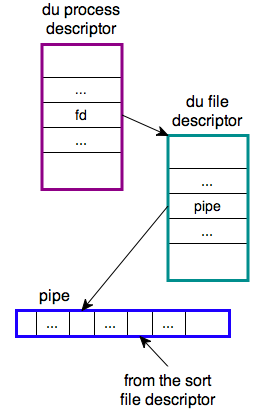
Inside the kernel there is a process descriptor for du with a pointer to the file descriptor table for du. One of the entries in the file descriptor will point to the "write" end of the pipe.
The pipe is like a buffer, and has a read end and a write end. The write pointer is always a little "ahead" of the read pointer (the read pointer chases the write pointer around the buffer in a circular fashion). As the sort process reads, the read pointer is advanced ahead. As the du process writes, the write pointer is advanced ahead.
Consider another example, which prints the du entries as before except excluding entries containing the word 'junk':
$ du | sed /junk/d # everything but junk
Here are some possible things that can go wrong with pipes and the way that these situations are handled:
$ du | less, user quits less before finished): There are two ways to handle this:
write() returns -1 and sets errno = ESPIPE (or something like that). The problem with this approach is that some commands ignore the exit status. For example, printf("Hello world\n"); or cout << "Hello world\n";, are often not checked for errors, but what if you are writing to a pipe with no reader? Most programs DO NOT CHECK.
lseek() on a stream, it will fail.
The pipe system call has the following definition:
int pipe (int[2]);
The argument to pipe is a pointer to an array of 2 integers. The 2 integers are file descriptors that get pointed to the pipe being created. For example:
int fds[2];
if (pipe(fds) < 0)
error();
The preceding will fill in the array with file descriptors. The first entry will point to 'read end' of pipe, the second to the 'write end:'
fds[0]; // the read end fds[1]; // the write end
Part of the homework assignment.
Suppose you want to implement du | sort -rn in c. THREE processes are involved: du, sort, and the shell itself. You have to do two forks&emdash;one for du, one for sort. Before you do those two forks, you must call pipe(fds);. That way, after you fork, both child processes can have access to the same pipe.
The forked process for 'du' now has two file descriptors (for the read and write end of the pipe) but only needs one (the write end of the pipe). This process should be nice about this by closing the 'read' end of the pipe. Code to handle this goes in section of code that's right before the execvp() call. The forked process for sort is the same except it will close the 'write' end. The shell, which is the parent process for both children, should close both ends after it has already passed them onto the children (it should not be reading or writing to the pipe). You will now have a pipe object with a single reader (sort) and a single writer (du). If you fail to do any of the closes, it will hang because the OS still thinks there is a writer/reader.
You can have many processes writing into the same pipe. For example:
(a & b & c &) | sed /junk/d
Process a, b, and c can write to the same pipe.
When a process exits, all the file descriptors that it has open are closed automatically.
When you call pipe(), it has to put some actual number in fds[0] and fds[1]. Lets say:
fds[0] = 15 fds[1] = 20
We are assuming that descriptors 1 - 14 are in use, and 16 - 19 are also in use. However, the problem is that du is going to be writing to STDOUT, but we want it to write to fd 15. There is another system call to handle this: dup2(), which is defined as follows:
int dup2(int oldfd, int newfd);
To modify file descriptor 1 to point to the same thing that file descriptor 19 points to:
dup2(19,1);
In our 'pipe dancing' code, we must also call a dup2() in order to use the pipe descriptors.
Previously our list was
Our updated list is
How do create a file? Another system call called create():
fd = ("/abc/", 0660); // creates file /abc/ with permissions 0660.
We will discuss why create is not orthogonal.