CS111 FALL 09Scribe Notes for October 29, 2009Table of ContentsDeadlockConsider a situation in politics when one party wants to add certain clauses in new legislation while another seeks other modifications. The two parties are unable to reach a compromise and no agreement is made. Similarly, in operating systems, when two processes fight over resources and no progress is made, we have a deadlock. Deadlock is typically a type of race condition during which the sequencing of acquired and released locks leads to blocked processes waiting on one another. Introductory ExampleBelow is a partial command executed on a shell like bash:
Here, the first pipe allows the sed command to take input from another program. This sed command first discards the first line of input, and then copies the remaining input to its output stream. Here, that output stream will be redirected to another program. Here is a typical method of implementing this double pipe:
Is it possible to turn these operations into a single system call? One possible function prototype for a read and write combination system call is as follows:
Here is one way to implement
The above code would make for an easier implementation for programs that simply redirect input to output and would have a faster running time than the standard approach of using read and write system calls. What, then, is the problem with this system call? There is a potential deadlock if the operating system chooses a certain scheduling pattern. If we have two processes, Process A and Process B, and two resources, Resource 1 and Resource 2, and the scheduler interrupts both processes between the two calls to acquire (lines 1 and 2), then the following will occur:
At this point, both processes will wait forever because they are in a blocked state while holding resources that the other is waiting for. This is quite rare and requires a specific schedule, but this is precisely why such a scenario must be kept in mind. Traditional debugging techniques will not work well on deadlock scenarios such as this because the code may work 99 percent of the time, but still has the potential for failure. Conditions for DeadlockA deadlock has a number of well-defined characteristics. In order for a deadlock to occur, the following four conditions must be simultaneously satisfied:
To fix deadlock, it is sufficient to break one of these four conditions. Fixing DeadlocksThough a break in any of the four deadlock conditions would be sufficient to fix all deadlocks, it does not make sense to stop mutual exclusion since that essentially defeats the purpose of acquiring locks in the first place.
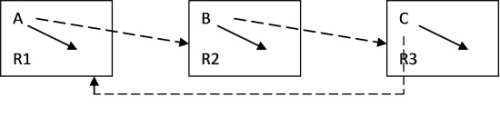
One way to prevent deadlock is to prevent circular wait. A possible way to accomplish this is to have
a Note that whenever a process attempts to acquire a lock, a graph must be constructed and a cycle check for directed acyclic graphs must be run. In Linux, there exists a chain of nodes containing pairs of processes and locked resources, so the implementation is certainly possible. How is the performance of this algorithm? The runtime of a DAG cycle check is O(n2), which could prove to be quite inefficient for large sets of data. In practice, the chain of locks is quite small, so this approach is safe to use and is commonly put to use. The same assumption for reasonable performance of graph traversal cannot be made for realtime systems, however. A major requirement for any realtime system is that there is a known upper bound for the running time of any operation and that information cannot be provided in this case. For most machines, however, this is not a major issue. Another approach, lock ordering, attacks the idea of hold-and-wait. Lock ordering requires that there exists some order on locks that all processes can agree on such as memory address or lock ID. Here is one possible algorithm:
This approach will successfully prevent deadlocks, but it is more CPU-intensive and will cause lower overall throughput if there are many processes that are willing to wait. However, from the perspective of the kernel, this approach allows for avoiding the construction of the graph from the first approach. Problem: Priority Inversion
Priority inversion is an issue that arises only when locks are used in a priority scheduling system.
Consider the following workflow that is illustrated by the diagram below. Let 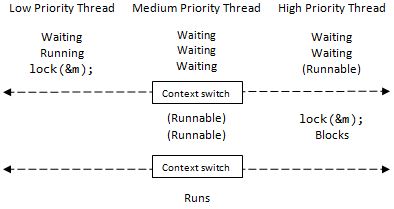
At this point, a high priority task arrives, so an immediate context switch occurs so that the high priority
thread can execute. However, the first thing that the high priority tasks attempts to do is acquire a lock on
The typical solution for this situation is to temporarily give the lock holder highest priority until it releases the lock that the high priority thread is waiting on. The assumption made by this approach is that the low priority task will finish its computation and release the lock quickly, and this is almost always the case. This problem caused the failure of the Mars Pathfinder in 1997. For more information, visit this link. Problem: Livelock
Consider a piece of code typically found in software to regulate systems like web servers. That software will
typically have a worker thread that executes operations on data and an interrupt service routine which
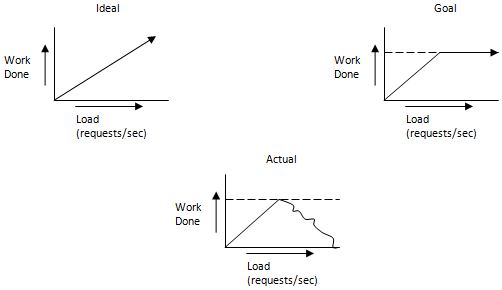
obtains requests for operations that the worker thread must execute. Now see the three graphs below, which
represent the ideal amount of work done, the realistic goal amount of work done, and the actual work done in
many real-world situations. Why does this occur? The problem arises because the interrupt service routine takes precedence over the application. If this were not the case, the application would lose packs because there is a limited buffer for holding data queued for processing. If we have a situation in which the worker is considerably slower than the ISR (say 10 GB/s versus 100 GB/s), then because the ISR takes precedence, it gobbles up the CPU and the worker is too slow to catch up. This problem is typically referred to as a receive livelock and occurs when there is not a sufficient amount of useful work done even though the CPU utilization is excellent. A way to solve this problem is to lower ISR precedence when the system is at capacity to allow the worker to catch up. Here, there will be packet loss, but the amount of work done will be closer to the realistic goal for work completed. File SystemsFilesystem GoalsWe want support for the useful functions which we studied previously: open(), read(), write(), close(), rename(), mkdir(). In addition, these functions should perform the action they advertise. For example, it's not acceptable to implement them with no-ops!
We want the filesystem to be reliable.
We want a filesystem to use space effectively.
We want a filesystem to be reasonably fast.
The filesystem should be secure. Note: Some of the features are simultaneously advantageous in different categories. Notice that to use space effectively, we might want to compress files, and we might want support multiple disks. These same features may be used to make the system faster. For the purpose of this lecture, we will focus on performance. It is easier to study and understand key design issues by doing so. Hardware ReviewHere's a quick review of hardware. Specifically, we will look at the performance of CPU versus hard disk. 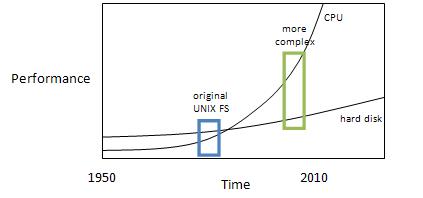 In the past, there was a range in time where the CPU was slower than the hard disk, meaning operations like compressing cost more time than storing the uncompressed data onto the disk. The original UNIX filesystem was developed around this time, it is shown in the blue rectangle. Even though modern CPUs are much faster than hard disks, we will study the original UNIX filesystem because the newer ones can be much too complicated. 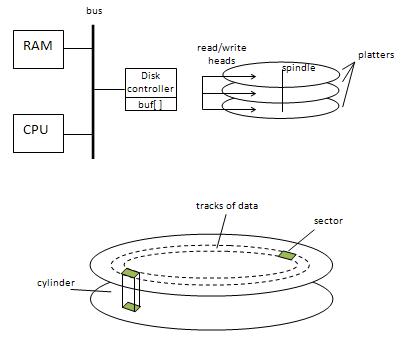 Typically, hard drives contain 1 to 5 platters. The platter is the circular disk with a smooth magnetic surface on which data is stored. Hard Disk PerformanceIn order to read data, the following steps must be taken:
Note: We cannot assume that assume that rotational latency and seek latency can be accounted for in parallel. This is because, essentially, if we miss the sector which we want to read, we must wait for the platter to complete another rotation. Here are statistics for a typical modern hard drive: 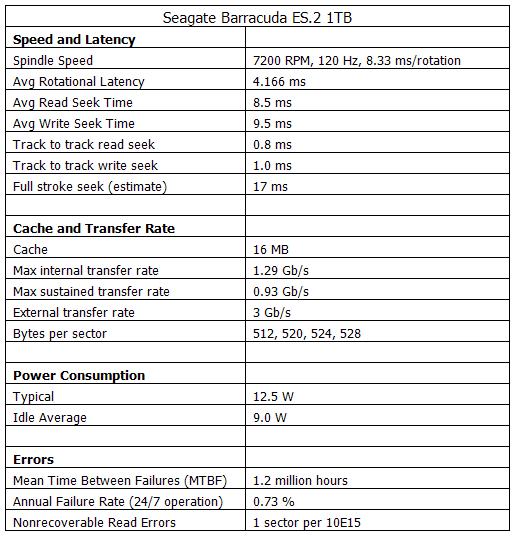 Note the following: In the disk drive, cache is used to smooth out variance in case of a busy CPU. The max internal transfer rate refers to transferring data from the platter to the cache. The max sustained transfer rate refers to sequential disk reads. The external transfer rate is the speed at which the cache can communicate with the bus. Track to track write seeks are slower than read seeks, because if data is being written, the write head must wait until it is exactly in the correct spot. However, when reading, the read head can start reading as soon as it is near the correct track. This accounts for about a 1 ms difference. Bytes per sector can be varied for error checking purposes. Hard drives have built in error checking, however, they should not always be trusted. In high reliability storage applications, the programmer may want to ensure that data stored and retrieved is correct by storing a checksum in the additional storage area. The mean time between failures should not always be trusted. It is an estimated value from simulated tests, since drives cannot be run for 137 years continuously. Buffered vs. UnbufferedBelow are some calculations and analysis on performance of hard drives.
Here is an example of unbuffered disk access:
An operating system can buffer, meaning the most recently read data can be used to satisfy the next request. In this example, with no buffering (and assuming no processing time), it takes 12.7 ms per loop iteration. With buffering, it takes 12.7 / 8192 = 0.0015 ms (for reading 8192 bytes). Below is an example of code that uses buffering.
In this example, with buffering, it takes 12.7 ms per loop iteration. There is an additional 1.0 ms of CPU processing time. The total time is 13.7 ms. However, this is a pessimistic estimate, because after block 1, it will only take 7.75 ms per loop iteration, plus the 1.0 processing time, totaling to only 8.75 ms. 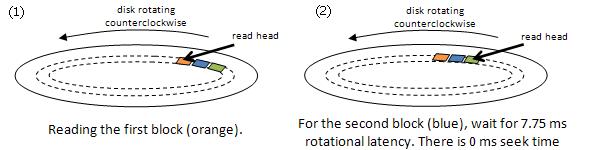 Is there any way to bring this time even lower? Yes, this can be achieved by reading the whole track into RAM. There are 1000 tracks, and each track is about 1 MB. Seeking will take 8.5 ms, and there will be 0 ms rotational latency. To transfer a track, it will take 8.33 ms. Per buffer, (8.5 + 8.33)/128 = 0.125 ms for I/O, and an additional 1.0 ms for processing by the CPU brings the total to 1.125 ms. To make this even lower, essentially to 1 ms, one could use double buffering. Common TechniquesIn order to improve read performance, we consider the following: Locality of reference means that we assume that an application wants a large number of sequential accesses, so that we can create a buffer and take advantage of it. Speculation means that we guess that the application will be sequential; if it is not, then we will actually worsen performance. Prefetching is a special case of speculation. In it, we retrieve data ahead of time because we assume the application will use it later. In batching, we want to issue as few system calls as possible but still get all the required data. We essentially attempt to lessens control overhead. We also want cache coherence to work. This means that the cache accurately reflects the state of the disk. This can become a hassle if there are multiple CPUs and RAM. What about write performance? For writes, speculation and prefetching does not make sense, because you cannot easily guess what the application will want to write. Batching makes sense, however. In addition, what does work for write is dallying, meaning we wait until the buffer is full before performing the write on the disk. |