CS 111
Lecture 14, 11/12/09
File System Robustness (cont.) and Virtual Memory
by Gordon Lin and Alfonso Roman
File System Robustness (cont.)
Problem Case: Power Failure
Our file system needs to be robust - even when the power gets pulled.
Simple case:
Suppose we are editing a file with a text editor. This text editor has a [save] button which will write the changes to the file to disk. Suppose we made some changes to the file, and we hit the save button. As the disk is writing the changes to the disk, we lose power to our machine. As we reboot the machine, we want to find the file in either its old state before the changes were made, or in its new sate, after the changes were applied. What we don't want to find is a garbage file that is halfway in between the the transition from the old version to the new version. In other words, we want to design a file system such that the saves are atomic.
One possible solution one might think of would be to have two copies of the file. One copy would represent the current state of the file, and one temporary file used to implement atomic saves. When we save the file, we first write our changes to the temporary file. Once the changes have been successfully written to the temporary file, we then write the same changes to the current file. If we have a power failure during the save, we can reboot the machine, peek at the current file and temporary file, and decide which file to recover from. If we lost power while writing to the temporary file, we can recover the old file from the current copy. If we lost power while writing the changes to the current file, we can recover using the temporary copy.
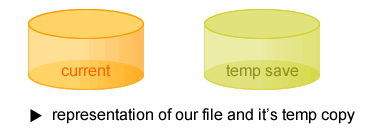
There is a problem with this solution because now we don't know which file to choose after we reboot from a power failure. We need additional metadata to help us pick.
Idea 1: Commit Record
One possible solution would be to add a commit record to the temporary copy of the file. This commit record is a one bit flag that will act as a record of intent, and will be written atomically. The commit record is set after the disk finishes writing to the temporary file, and before the disk begins writing to the current file. The commit record is then cleared once the disk finishes writing to the current file.

Here is the general pattern for use of the commit record.
Begin
-Precommit Phase
-Commit (atomic)
-Post-commit Phase (clean up/performance/clear commit record)
End
Notice how you can build large atomic instructions from smaller atomic (all or nothing) operations. We could nest this a few levels up.
Although simple, there's a catch: the commit record is quite SLOW, since we have to worry about two copies of the same file. We might be able to do better.
Idea 2: Use a Journal
In a based system journal, we split the file system into two pieces. The first piece would be data blocks that would represent the state of the file system, and the second piece would be a journal. The journal would consist of (mostly) append only entries, each entry would detail the changes made to the data blocks and a commit record to keep track of whether the change has been made. If you want to make changes to the file system, you must log it in the journal before changing the actual data blocks.

Here are the basics steps of how a journal would work.
-When we want to make changes to the data blocks, we write changes to be made to the journal.
-Then we set the commit record.
-On reboot, we rescan the journal from oldest to newest.
-We install any changes detailed by the journal, changes which have the commit record set.
-Lastly, we clear the commit records.
Should the reboot fail (say, by a power outage) again, recovery of the journal idempotent, that is repeated recoveries have the same effect as one.
When designing a journal based system, it is important to pick a good journal size. This is an engineering trade-off. If the journal is too small, it will fill up quickly and will cause stalling. If the journal is too big, it will waste disk space. However, if you do design a journal well, it does have certain performance advantages. First, writes to the journal are sequential. Second, the journal tail can be caches for faster access. Third, the journal itself can be stored in a different disk drive separate from the data blocks.
An extreme case of of journal usage is using a disk journal and ram disk to hold our data blocks. This allows us to write data quickly as we clear commits from the journal. While this approach is good for performance, it's not ideal for all systems, especially real-time systems (think of a black-box data recorder on an airplane).
Two Types of Journals
Write-Ahead Log : Write new values to the log, then commit. Requires post commit phase in order to copy new data into cell data.
Write-Behind Log : Write old values to the log first, then write new values to the log. Then commit. No post commit phase. The advantage of this method is that when doing recovery, we can go back through the log (a cheaper operation).
Aside on the ext4 file system
The man page for ext4 lists in its notes (bugs) section that potential data loss may occur in this file system. This happens because the designers of ext4 wanted to get the most possible performance from the file system. One way they achieved this was by using extents which allocate a big file very quickly, but trades off atomicity. From wiki: An extent is a range of contiguous physical blocks, improving large file performance and reducing fragmentation. You can read more about ext4 here [link to wiki page: http://en.wikipedia.org/wiki/Ext4 ] .
As an example of how ext4 might loose your data: say our system is doing an operation:
write("...", 8192)
-> and we crash!
when we try to read our file after reboot we read in 0's!
BUG: We've taken an atomic operation and split it into two parts:
(atomic) 1a. Allocate space
(atomic for small files) 1b. Copy data into new space
But this whole operation is not atomic. We're satisfying file system invariants, but there is a trade-off for performance over durability.
Virtual Memory
Problem Case: Unreliable processes with bad memory references. Big Problem!
Solution 1: Fire your programmers. Get better ones...
-This works, but better programmers also cost more money
-Expensive
Solution 2: Runtime checking to programs
We could routinely check the subscripts of arrays to see if we are accessing within bounds (subscript checking like you were taught in CS31). We also could keep checking null pointers, and make sure we are not accessing invalid memory. However, we would need many conditional branches in order to perform these checks, and it would impact our performance. We would also have to trust applications to do the checking. This would be possible if all our applications were compiled under a single trusted compiler which would add all the checks for us, but this is still slow.
Solution 3: Base + Bound registers
In this solution, process will now use two privileged registers, a base register and a bound register, in order to prevent access to invalid memory. The base and bound registers will point to two memory addresses, and the hardware supporting base and bounds would be modified so that all memory access R will be between "BASE address" ≤ R ≤ "BOUND address". In essence, process will now live within their memory jail. However, this does pose several problems.
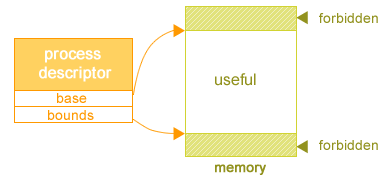
Problems
-Processes may be bounded with inflexible memory sizes - and we can't easily add memory.
-Processes are not able to share memory among themselves.
-Cannot run same program with the use of absolute memory addresses in multiple processes.
-IO must be done through kernel.
Solution 4: Multiple Base-Bounds registers
We can solve the inflexibility of memory, and the inability to share memory if we use multiple base bound registers. However, this approach still have problems.
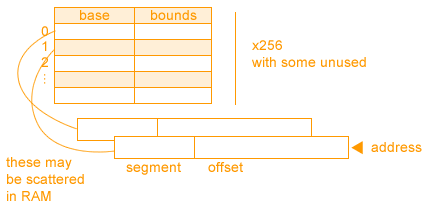
Problems:
-Because segments are different sizes, we'll get external fragmentation.
-Not easy to change the size of a single segment.
Page-Based System
A Page-Based system attempts to solve the problems found in the previous solution examples. We chop up the RAM into small fixed memory sizes call pages. We use a page table to store each piece of RAM as a page table entry. Each page table entry will consist of the page # the entry refers to, and an offset within the page.
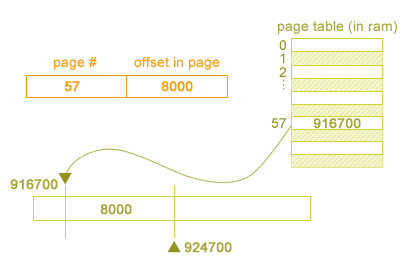
Lets look at an x86 machine, and see how a page table works.
Suppose we use 32 bit addresses. The first 20 bits of the address will contain the page number, and the bottom 12 bits will hold the offset. Given a page table entry, we can map it to its memory location.
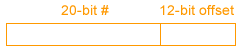
size_t pmap( void *a ) {
size_t vpn = ((intprt_t) *a) >> 12;
return PAGE_TABLE[vpn]; //The pointer to PAGE_TABLE is store in the %cr3 register
}
Although a page based system solves the issue of external fragmentation, and memory sharing, it still has problems of its own. Suppose we are using a 4K page table. If each page table entry is 4 bytes large, the total size of the page table would be the size of entries multiplied by the total number of entries, which will be 2^20. Then the page table size will equal 4 * 2^20, or 4MiB per process! This will not scale well. 1000 processes would require 4GB of RAM.
2-Level Page Table
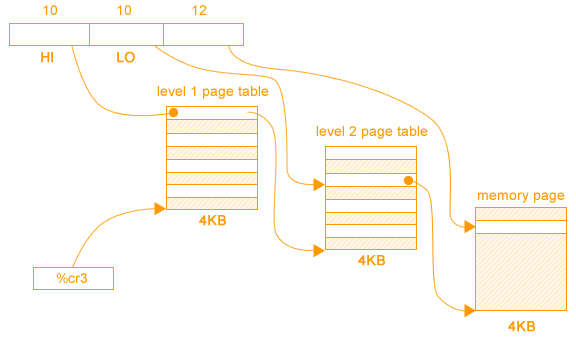
In order to address the scaling issues with the previous page table system example, we will now explore the concept of the 2-level page table system. Instead keeping a page table with entries for every memory location in RAM, we only need to keep entries that need to mapped. Instead of using the first 20 bits to keep the page number, the virtual address will now be split into three parts, which will consist of a HI, LO, and an OFFSET segments. The HI and LO segments will utilize 10 bits each, and the offset will use the last 12 bits. Using the %cr3 register, we can access the Level 1 page table, called the page directory. Then we will access the HI segment of the virtual address and find the proper entry within page directory. This entry in the page directory will lead us into a second, level 2 page table. Using the LO segment of the virtual address, we can now access the correct entry within the in the level 2 page table, which will now direct us to the right memory page. The last 12 bit OFFSET will point us to the location within the memory page. The following function is an example of how this may work.
size_t pmap( void *a ) {
intptr_t A = (intptr_t)a;
int hi = A >> 22;
int lo = (A >> 12) & (( 1 << 10 ) - 1 );
size_t *p = PAGE_TABLE[hi];
if (!p)
return FAULT;
else
return p[lo];
}
Page Faulting
Page faulting is when the page table says 'no page there' or is not accessible for instruction. If this happens we trap and enter the kernel (which is told the bad address and PC, etc..). The Kernel can then decide to terminate the process if it's suspicious or send a SIGSEV signal (which the process needs to know how to handle, or it will die).
Or the kernel can fix the page table entry to make it work and re-start the instruction. The motivation for this is that a program that needs 4GB of RAM can now run on 1GB physical RAM.
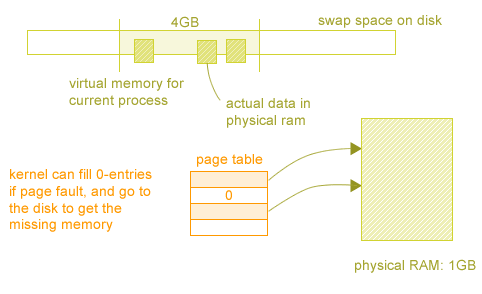
Problems:
-This is very slow since we're going to the disk to get data.
-Page thrashing also kills this idea.
Can we cheat this approach?
-We can try write to the %cr3 register -- but kernel already makes this a privileged register.
-We can also try to write to the page table itself -- the kernel doesn't let the application see its own page table.
So we can't cheat this approach so long as the kernel does its job.