CS111 FALL 09
Scribe Notes for October 13, 2009
by Vahab Pournaghshband and Johnny Yam
Table of Contents
- Review
- Temporary Files
- Pipes
- Signals
Recall from the previous lecture the open syscall function:
int open(const char *pathname, int flags, mode_t mode);
The open function takes a pathname to a file and returns a file descriptor to it. The flags specify the access mode,
while the mode is used to set permissions to the file. For a more indepth explanation of the open function,
see the notes from the previous lecture, which can be found at the
CS111 Fall 09 Syllabus or
see the manual page of the open function.
Sometimes we want a temporary file, from which we can use to read and write from. While Unix/Linux does not
have a system call to create one, we can perhaps write such a function that simply creates a temporary file for
us, similar to the following:
1 int opentemp()
2 {
3 do {
4
5
6 char * scrambled_random_name = random_name("/tmp");
7
8
9 int fd = open(random_name, O_RDWR | O_CREAT | O_EXCL, 0666);
10
11 if (0 <= fd)
12 unlink(fd);
13 }while (fd < 0 && errno == EEXIST);
14
15 return fd;
16 }
This particular implementation of the opentemp() function does not take any arguments; thus, all temporary files created
this way are essentially the same. In other words, they have the same access modes. The flag O_RDWR specifies the access of file as read and write.
O_CREAT specifies to create the file if it does not already exist, and O_EXCL ensures that the file is created in this call.
In other words, the call to open will fail (returns -1) if the file already exists (errno is set to EEXIST). Also,
using O_EXCL, without O_CREAT leads to undefined behavior, making the flag design non-orthogonal.
The function unlink() deletes the name linked to the file descriptor from the filesystem. Because the file descriptor still exists and hence
the file is still open, we can still read and write to the now nameless,
temporary file, until the descriptor is closed or until the process returns or exits. However, disk space is still used
but undocumented. In actuality, we can fill up all the space and memory in the hard drive through these temporary files, without the system
realizing it. Consequently, a user can unsuccessfully try to save a file to the disk because of lack of memory even though, for example,
there are 12GB (arbitrary number) of documented free space; the 12 GB are filled by the the temporary files!
Because this implementation is not a syscall, there is a possibility that we can actually create a file before deleting it.
Consider that we cause an interrupt ("ctrl-C'ed" in Linux terminal) and exited while the process is running
at the line if (0 <= fd), right after open successfully created a file and right before
unlink() is called. Because we never deleted the file, the file will remain in the tmp directory, forever, unless we delete it manually.
Pipes are bounded buffers used for interprocess communication, meaning that they have limited capacity (bounded),
live in RAM (buffered), and allow for communication between processes (IPC). The following is the general form
of the pipe syscall function:
int pipe(int fd[2]);
The function takes an integer array of two elements and sets fd[0] to a file descriptor refering to the
read end of the pipe, sets fd[1] to the write end of the pipe, and returns 0 on success or -1 on error, in which
errno is set accordingly on the later. For more information on pipe(), see to the
man page.
In the command line
Pipes are also used in the Unix/Linux command line. Consider the following command:
$ du | sort -n
The command du estimates the disk/resource usage of each file and prints all information to the console.
The pipe redirects the output of previous command
du into the input of the next command.
The sort command,
with option -n, numerically sorts all the output from du.
Shell Example
Now lets consider a high level model on how we would implement the previous command du | sort -n:
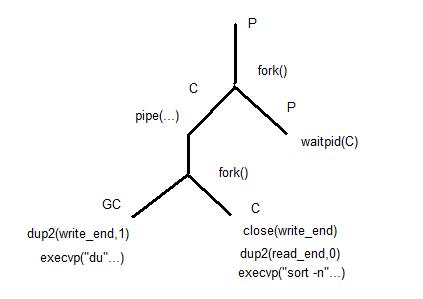
In the diagram, P refers to the parent process, C is child, and GC is grandchild.
First, you fork() to create a child process.
In the child process, you create your pipes and fork again to create a grandchild. In the parent process, you
wait for the child process to finish executing. In the grandchild process, you redirect standard
output to the write end of the pipe, while in the child process, you first close the write end of the pipe and
then redirected standout input to the read end of the pipe.
FAQ on Shell Example
Why don't we pipe() in the parent process?
Recall that when we call fork(), we create a child process that inherits its OWN copies of all open
file descriptors from the parent. Because the parent does not need to use the pipes, there is no need for the
parent process to have them and have to copy them each time you want to create a child process.
Why do we close() the write end of the pipe in the child process?
Consider if we do not close the write end in the child process. The rule is that as long as the a write end is open, the read end will
be reading, regardless if the write end is actually writing or not. Thus, if we do not close the write end in the child process, the child process
will hang and read forever. This is another reason why we would not want to create the pipe in the parent process. If we did, the child process
will see that there is another "writer" in the parent process and be waiting forever unless we also close the write end in the parent.
If that is the case, then why don't we close the read end in the grandchild process?
Technically, we can. However, there is no need to. We can have the read end of the pipe in the grandchild process just hang since we are not using it.
Race conditions?
- What if the child process starts reading from the pipe before the grandchild writes to it?
Not a problem because as long as a descriptor
to the write end is open, the child process will keep reading and thus will wait for the grandchild to write.
- What if the child and parent processes finish before the grandchild? Is no one waiting for the grandchild process?
If both the child and parent processes finish before the grandchild, the grandchild will be caught by
init, the parent of all processes. Let's consider the other possibilites.
- What if the parent process finishes before the child process?
This is not possible because the parent is waiting for the child process to finish.
- What if grandchild finishes before the child process?
Also not a problem. The grandchild will just return to the child process.
Pipes vs. Files
Some of the upsides of using pipes over files is that not only do we not have to worry about filenames, but we also do not have to worry about
the disk filling up (or unknowningly being filled up through temporary files). However, the downsides for pipes include the fact that read and
writes can hang and dancing pipe code is very tricky to implement.
Everything in One
Don't you wish that there was a function that forks, pipes, and executes commands for you? Wouldn't it be great if
that function also deals with all the file and pipe reads, writes, closes, and takes care of all that crazy dancing pipes
code for you? Well, here it is, the posix_spawnp function!
int posix_spawnp(pid_t *restrict pid, const char *restrict file,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp,
char *const argv[restrict], char * const envp[restrict]);
The keyword restrict is used on pointer declarations.
It says that the pointer is the only pointer that can point at that location
in storage. In other words, no other pointers can point to that address location. pid is the variable used to return the process
ID of the child process created. file indicates the name of the new process image file. file_actions indicates
the actions taken on the calling process's open file descriptors to create the child process's open file descriptors. attrp points
to the spawn attributes object. argv is the array of arguments for the function. Finally envp is an array of strings
that create the environment for the new process image.
Let's examine the case of power failure while a reliable process
is running. When the power cable is pulled out, the power
doesn't die out immediately. In fact, it takes a few milliseconds before
the power is completely gone. This reliable process may need to be notified
of such power failures to, for instance, save states before being forced to
exit. Let's examine the possible approaches to accomplish this:
-
A bit in the file "/dev/power" would indicate the power status.
In this approach, the reliable program periodically reads the file.
If it reads 1, then it means the power is still on and the program would
continue whatever it was doing. However, in case of reading 0, the process
realizes that the power is gone and it must exit within, say, 10ms. This
approach has two major disadvantages: (1) it requires all programs, that want
to be reliable, to poll, and, (2) to make this to work, the applications
have to incorporate this mechanism in their implementation.
-
Another approach would be reading from a pipe rather than a file. In this case, unlike the previous
approach that needed to check for a change of a bit at every time interval,
the process will hang until a character is written to the pipe, indicating a
power failure. Clearly, this solution suffers from major drawbacks, not to mention
the requirement for modification of all applications. In this approach the process
is blocked while waiting for a change of power state, so the application can not
execute any of its actual code. To fix this we need
multithreading. In other words,
a separate thread should be delegated to reading the file for a signal of power
failure, to ensure that the main thread is not blocked. But now the question is
that how would the waiting thread tell the main thread that there is a power failure?
-
As another approach, the kernel can save the entire RAM to the disk once it
realizes that the power failure has occurred. Then, later, when the system starts
again, the kernel would restore the RAM. This approach, however, is not practical,
since writing to disk is extremely slow, so it may take more time to save than the
system actually has left.
-
The winner approach is sending SIGPWR signal to all processes in case of power
failures. In this approach, the kernel signals the processes of such event, and it
leaves it up to the processes to do what they want to do with it.
Signal Menagerie
The following table enumerates some of the signals. All signals are defined in
signal.h.
| Events |
Corresponding Signals |
| Unusual Hardware Events |
SIGPWR: Power failure
|
| Uncooperative Processes |
SIGINT: Terminal interrupt signal
|
| Invalid Programs |
SIGILL: Illegal (bad) instruction
SIGFPE: Floating-point exception
SIGSEGV: Segmentation violation
SIGBUS: Bus error
|
| I/O Errors |
SIGIO: Device is ready
SIGPIPE: Broken pipe
|
| Child Process Died |
SIGCHLD: Child status has changed
|
| User Signals |
SIGKILL: Kill processes
SIGSTOP: Stop processes for later resumption
SIGTSTP: Suspended processes
SIGUSR1: User-defined signal 1
|
| User Went Away |
SIGHUP: Controlling terminal is closed
|
| Time Expiration |
SIGALRM: Alarm clock
|
How to Handle Signals?
Back to our power failure example, here is how the power failure signal is established and handled:
1 int main()
2 {
3 signal(SIGPWR, powerFailureHandler);
4 ...
5 }
6
7 void powerFailureHandler(int signum)
8 {
9
10 ...
11 }
The first line in main() establishes a handler for the SIGPWR
signals. The first argument to signal is an integer specifying what signal
is referring to, while the second argument is a function pointer type which points
to the signal handler.
In our example, the powerFailureHandler() is a signal handler.
A handler is a function that is executed asynchronously when a particular
signal arrives. Since it interrupts the normal flow of execution, it can be
called between any pair of instructions. If a handler is not defined for a
particular signal, a default handler is used. The only two signals for which
a handler cannot be defined are SIGKILL and SIGSTOP.
What is Safe to Do Inside a Signal Handler?
There are DO's and DON'T's when it comes to signal handlers. For instance,
calling certain functions, called non-reentrant,
could potentially lead
to havoc. An example of such functions is malloc() which allocates additional
memory on heap. Recall that signals are asynchronous function calls and could be
raised at any time. In the case of malloc, havoc can result for the process, if a
signal occurs in the middle of allocating additional memory using malloc(),
because malloc usually maintains a linked list of all its allocated area and
it may have been in the middle of changing this list. Another example of
non-reentrant function calls inside signal handlers is getchar() which
reads a byte from standard input. In that case, the process could lead
into an inconsistent state if it was in the middle of dealing with stdio
buffer when the signal arrived. On the other hand, reentrant functions like
close() are safe to use in signal handlers.
How to Block Signals?
Sometimes we would benefit more by not having signals at all usually to avoid race conditions.
Blocking a signal means telling the operating system to hold it and deliver it later. Generally,
a program does not block signals indefinitely, it might as well ignore them by setting their actions
to SIG_IGN. One way to block signals is to use sigprocmask which its format is:
sigprocmask(int how,
sigset_t const * restrict set,
sigset_t const * restrict oset)
Where how is either of three values: SIG_BLOCK, SIG_UNBLOCK, SIG_SETMASK. The
first two values specify whether the signals in the new signal mask should be blocked
or not, while the last specifies that the new mask should replace the old mask. set and
oset that hold new and original masks are both types of sigset_t which is a bitmap that
reserves one bit per signal, indicating which signal(s) are blocked. The following code is
an example of blocking SIGHUP signal while performing the string copy.
1 sigset_t newMask, oldMask;
2 sigemptyset(&newMask);
3 sigemptyset(&oldMask);
4
5
6 sigaddset(&newMask, SIGHUP);
7
8 sigprocmask(SIG_BLOCK, &newMask, &oldMask);
9 strcpy(tmp_file,"/tmp/foo");
10
11 sigprocmask(SIG_SETMASK, &oldMask, NULL);
The code segment between the two sigprocmask-s is called
critical section in the operating system context.
Go Volatile on Variables:
Let's examine the following code:
1 int x;
2
3 int main()
4 {
5 x=0
6 ...
7 x=1
8 ...
9 }
x is defined as a global variable. It is first set to 0 and later in main(),
its value is changed to 1 without involving x in any statement between these
two assignments. While the compiler is compiling this code, it replaces the
x=0 statement by x=1 and removes the x=1 in line 7, since it is smart enough
to realizes that there is no need for x=0, for it is never used. This seemingly
fine observation could lead to undesired behavior if the associated signal for
the following signalHandler occurs between line 5 and 7:
1 void signalHandler(...)
2 {
3 if (x)
4 unlink("f");
5 }
In this case, an entirely different action would be taken by the process
if the compiler does the optimization at the compilation stage. This
problem is fixed by telling the compiler to avoid such optimization using
the volatile keyword. volatile is widely used in codes involving signals,
and can be seen as a warning for potential race conditions. The code is
then revised as follows:
1 int volatile x;
2
3 int main()
4 {
5 x=0
6 ...
7 x=1
8 ...
9 }

CS111 Operating Systems Principles, UCLA. Paul Eggert. October 13, 2009.
|