CS 111 Lecture 7Scribe Notes for October 15, 2009by Michael Robertson and James Wendt PROCESSES VS. THREADSBoth Processes and Threads execute instructions, however the realms in which they operate differ slightly. Processes are considered the heavyweight of the two, while Threads are considered the lightweight. Processes are allocated their own memory, their own file descriptors, their own ids, and can be in charge of multiple Threads running. Threads on the other hand do not have their own memory, but instead share with other Threads in the Process they are running under. Threads get access to the CPU, they have their own program counters, registers and stack, but they are not considered their own program. Because Threads share memory with other Threads in the process, they are not necessarily protected from each other, since one Thread could overwrite data another Thread requires. Processes on the other hand are in control of their own memory and are the only instances that can alter that memory. Thus while this memory protection exists between Processes, communication between processes is made somewhat difficult. In a pure Process World that contains only processes and no threads, communication between processes must be done via pipes and signals (which as we have seen in practice labs can be a difficult task). In the Thread World applications must be written in such a way as to be thread-safe and thread-aware so that Threads do not accidentally overwrite other Threads important data, since they all have access to the same heap. The Event Driven World differs from both the Process World and the Thread World by taking control of the CPU until its task is complete. It is best understood by investigating the following examples:
BASIC SCHEDULINGThe basic scheduling problem is that there is too much work to do and too little CPU to do it with. The idea is that we will use what little CPU we have to eventually complete the work and "catch up" with the scheduler. In order to do this, we must first define the scheduler's policy (how to decide what task to do next) and the scheduler's mechanism (how to get this to work). MechanismTwo types of mechanisms were discussed in class, cooperative and preemptive. Both are defined below: cooperative processes/threads/jobsIn a cooperative system, processes are "polite" to one another. They voluntarily give up their control of the CPU to the Operating System thus allowing the kernel to call its scheduler and run another process if it deems appropriate. In this way, the CPU is shared across all processes. There are a number of ways in which an application can be cooperative and give control back to the system:
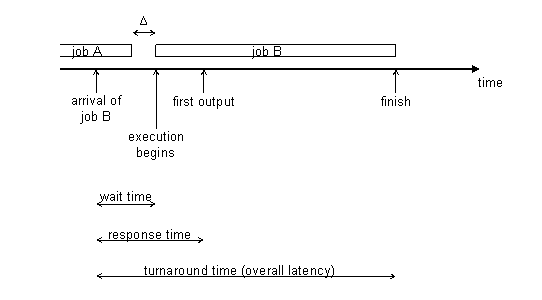
Q: How does the Operating System implement yield()? The yield() system call essentially returns control to the kernel which then runs its scheduler. The kernel code for a scheduler can be very complex, but in its simplest form it will look through its process descriptor table for a process p that is marked as runnable. It will load p's state from the process descriptor into memory, including the instruction pointer, and then runs p and waits for a return value before saving p's registers back into p's descriptor. Q: How does one implement blocking? Blocking is more complicated than yield() and requires extra information. In the process descriptor, for every device/pipe/child process, the kernel keeps track of which processes are waiting for that device/pipe/child, this way when a device is no longer busy or a child process terminates the kernel knows what process to wake up. This in turn requires that each process keep track of its state, either blocked or runnable. Thus device drivers and system calls such as read() and write() have built in wakeup calls that take the first waiting process in the queue, pop it off and unblock it. preemptive schedulingIn a preemptive scheduler, processes might not necessarily be "polite" to one another as they were in the cooperative system. Thus processes could potentially hog as much CPU time as they choose, and could hang up the entire system. In this case, the operating system arranges to call a yield() every 10ms by means of a timer interrupt. The motherboard has a clock on it that sends an actual electrical signal to the CPU which triggers the CPU to trap with the clock interrupt signal and regain control of the CPU back to the kernel. This value of 10ms is different for all systems and can be changed. However if the value becomes too small, then our system ends up wasting a lot of time on context switching. If the value is too large, then the system tends to get sluggish in its response to user calls. PolicyThe policy of a scheduler defines which process should run next. This decision could be as simple as iterating through the list of process descriptors looking for the next runnable process, or it could be as complicated as that of an airline scheduler at the JFK airport (utilizing many algorithms which take a while to run). It is obvious to see that in the framework of our operating system, we want our scheduler to run as fast as possible so as to minimize the context switching time (the time spent changing one process to another). The graphic below denotes the timeline of a job. The delta Δ represents the context switching time (the time it takes to finish process A and switch over to process B).
Below we outline a few cooperative and preemptive scheduling implementations on the following job table: Cooperative Scheduling ImplementationsFirst Come First Served (FCFS) Assuming that the scheduler does no preemptive scheduling, this scheduling implementation simply performs each job to completion in the order that it arrived.
The processes run by the CPU will be in the following order (where one letter represents one clock cycle): AAAAABBCCCCCCCCCDDDD The average wait time is 5.5 and the average turnaround time is 10.5 Immediately one can see that problems arise if one of the earlier jobs has a long runtime and ties up the CPU for a long period of time before allowing later processes to perform. In the specific example given above, the average wait time could have been decreased if we had scheduled D before C. Shortest Job First (SJF) In a cooperative environment this implementation, upon completion of a process, always looks to run the next shortest job. Thus the order in which the processes will be run is: AAAAABBDDDDCCCCCCCCC
Thus using this implementation the average wait time drops to 4.25 and the average turnaround time drops by the same difference to 9.25. However this implementation is not always best suited for Desktop applications because many processes have unknown runtimes. Another option and slight alteration to this implementation is to schedule the most important job first instead of the shortest one by integrating a priority scheme into the process descriptors. Preemptive Scheduling ImplementationIn a preemptive scheduling system we break up time into quanta. In most Desktop systems, a quanta is about 10ms, and is the time spent on each process before context switching. For the purposes of the following exercises we assume that each quanta Q=1. The simplest policy we can implement in a preemptive scheduling implementation is Round Robin (RR). This implementation is a First Come First Served scheduling system, but upon completion of one quanta, the current process gives up control to the kernel, and is placed at the back of the line. In such an implementation, the jobs A, B, C, and D will be scheduled as such: ABCDABCDACDACDACCCCC
This new implementation decreases our average wait time to 0 but increases our average turnaround time to 12.25. These times are valid so long as the context switching time between processes Δ<<Q. A strong advantage to the Round Robin scheduling implementation is that it is very fair. Unfortunately however, this implementation can fail and end up starving a processes of CPU time. This is best illuminated by the following example: Say we have a list of 26 processes A,B,C,...,Z. Each arrives two seconds after the its predecessor, A arrives at time 0, B at time 2, C at time 4, etc. And every process has a runtime of 2 except for process A whose runtime is 3. We also assume that our quanta Q is now 2 seconds long. Using the Round Robin implementation, the CPU will run process A for two clock cycles before determining it has reached its quanta quota, and then moves on. The scheduler sees that process B has arrived, so it gives B its fair share of CPU time, upon finishing process B in the allotted time Q, the scheduler sees that process C has arrived, and so on. All this while, process A has only had 2 seconds of CPU time, and only needs 1 more second to complete its operation. Following the Round Robin implementation starves A of CPU time until finally all the processes B,C,...,Z have completed, then it gets to terminate. This starvation problem can be fixed by simply ordering the processes such that any new processes that arrive will be placed at the end of the queue instead of at the beginning. In this manner, the CPU will run the same processes as depicted before as such: AAABBCCDDEEFF... While we have solved the problem for this simple case with the introduction of priority scheduling, we have also introduced a whole new set of issues dealing with the added complexity. How does one actually decide on the priorities of processes? And just like Shortest Job First, priority scheduling can still lead to starvation of some processes. Real World ImplementationThe implementations outlined above were those discussed in class. A list of more implementations including short descriptions of their policies can be found here. I also recommend checking out the Wikipedia article on Scheduling as it has some good short descriptions of the basic scheduling implementations and compares their utilization and turnaround time side-by-side. Most real world scheduling implementations maintain multiple queues using different algorithms within different queues and even between queues. For example, the typical UNIX scheduler runs processes with the highest priority first, those with the same priority are then put into a Round Robin scheduler. The UNIX scheduler also implements an interesting reward scheme which increases the priority of processes if they block themselves before using their allotted CPU quota quanta and decreases a processes' priority if it uses up all of its allotted CPU quota quanta. A general description of the Linux, Windows, and Mac OS schedulers can be found on the same Wikipedia article above. If you would like more detail regarding the Linux scheduler, information can be found here. Further Reading: |