CS 111 Lecture 11: File System Design 11/6/2013
Scribe Notes Prepared by: Jared Brown, Sean Grant and Vishal Yadav
In order to choose an optimal file system, one must have a way to measure file system performance. For this measurement, there are certain metrics for performance to consider: utilization, throughput, and latency.
Utilization: The percentage of the system that is doing useful work.
Throughput: Requests/second.
Latency: The delay between request and response time.
Under these definitions, an optimal file system would have high utilization, high throughput, and low latency. Generally, however, tradeoffs between the three must be made in most file systems. For example, if one was a system operations administrator, one would put a higher emphasis on throughput so that all users can make more requests per second. Latency, then, would suffer a bit.
Assume that we have a hypothetical router with Programmed I/O (PIO) with the following hardware specs:
Below is a comparison table of various methods to improve throughput and latency:
|
Method |
latency(µs) |
throughput(KB/s) |
CPU utilization (%) |
Comments |
|
Polling |
100 |
10 |
5 |
Simplest, 1 byte at a time |
|
Batching |
1000 |
21 |
10.5 |
(21 buffers * 40 blocks) This method gets rid of the overhead of having to send a command to the device multiple times. These times assume there are multiple tasks. |
|
Batching, Interrupt and Context Switching |
106 |
18 |
8.9 |
This method has the overhead of context switching and assumes there are multiple tasks |
|
DMA, Batching, Interrupt and Context Switching |
61 |
91 |
45 |
This assumes there are multiple tasks. DMA is direct memory access |
|
DMA and Polling |
56 |
167 |
84 |
This assumes there are multiple tasks. DMA is direct memory access |
In the context of the embedded world, threading is bad, context switches kill you. Once we've started using batching, interruption, and context switching, the assumption is that we have multiple tasks being executed.
This approach is not trying to minimize power usage.
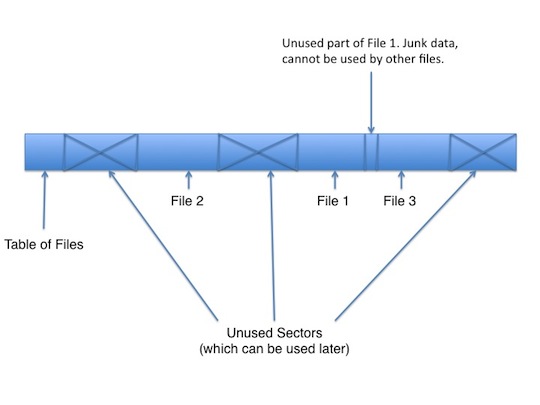
Instead of learning how to design a file system, we'll start by learning how not to design a file system. In 1974, Professor Eggert was told to design one by an anonymous former professor of his. He had a disk (with a 1.5 foot diameter) that would sit in a cartridge. It carried 1MB. Eggert decided to treat the disk as a linear array of sectors. Each file would begin on a sector boundary so that the files would be easy to find. The size of each file would not have to be a multiple of sector size, which means that some portion of each sector is likely to be junk. Unused sectors may be useful later.
There is one main issue with this approach: how is the program going to know where the files are? The location of each file could be hardwired into the system, but that limits its flexibility. To solve this problem, Professor Eggert took the initial part of the file system and put a table of files there. Each entry in the table includes the location of the file (the sector number) and the size (in number of bytes). Because the location is just a sector number, it's possible to cheat and store it in a smaller sized integer. If you had to report the specific location on disk, it would require more bytes. Professor Eggert wrote this system in BCPL, which is a language very similar to C, but without the "char" variable type. He had to determine how big to make the file directory table, and chose 8 sectors, which can hold the entries for 256 files. A representation of the table can be seen below:
Pros and Cons of this file system:
Pros:
Cons:
This is essentially the RT11 file system. Many of its problems were fixed by the inventors of DOS in the FAT file system.
The FAT (File Allocation Table) file system addresses the 1974 file system and RT-11 file system's problem of external fragmentation.
A breakdown of a 4 KiB file system can be seen below:
|
Boot Sector |
Superblock |
FAT |
The actual data |
Boot Sector: Contains machine code that is loaded into RAM upon booting the computer.
Superblock: Contains a record of the file system characteristics including, but not limited to:
FAT: This is the actual file allocation table. The table is set up as a linked list, with each entry in the list indexed by sector number. Each entry tells you which sector is next in the linked list by storing that sector's sector number. For example, if sector 3 stored sector number 5, then sector 5 is the next sector after sector 3. Below is a visual representation of the table:
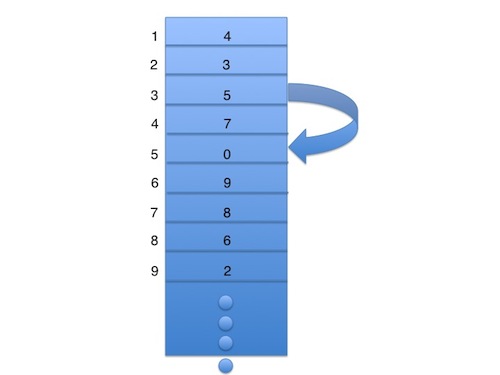
Two special values to note in the file allocation table: 0 and -1.
0: denotes EOF (end of file).
-1 (all bits turned on): denotes a free block, available for allocation to create a new file or grow an exiting one.
In FAT16, the table entries are 16 bit numbers (consequently, FAT12 and FAT32 have table entries of sizes 12 bits and 32 bits, respectively.) In this system, one could store 32 MiB, or equivalently 2^25 bytes of data.
The idea of a directory came about to solve the problem of the file system needing a way to get to the start of a file. A directory, then, is a file that maps file names to other files. Directories can also have other directories as files they map to, so the file system supports nested directories. The issue then arises of how to reach the start of the first directory. To address the issue, the super block is given a root directory sector number.
With this implementation of a file system, we still have an issue of internal fragmentation. That is, we have a potential of wasted space at the end of every file. Defragmenting was introduced to combat this issue, and became very important in space allocation optimization in file systems. What defragmenting did was put all free space at the end of the file system, and put all files in ascending order.
Consider trying to rename a file in the RT-11 file system and in FAT.
(1) $ mv d/f d/g (easy in RT-11 and FAT)
(2) $ mv d/f e/g (difficult in FAT, easy in RT-11)
RT-11: Easy to do, because all the machine has to do is go to the table at the start of the system and update it.
FAT: Only easy if you're trying to rename a file in the same directory. The problem is, in order to be able to execute (2), the system has to write 'd' and 'e'. It would seem like a good idea to write 'e' first and then 'd' second so that the original data isn't lost. However, there's a problem with this: even if you do write to e first, if the plug is pulled after this first write, there will be two different directories 'd' and 'e'. These two directories now have entries 'f' and 'g', respectively, which point to the same file. Later if, we decide to remove 'g' in 'e', we will mark that location as free, but 'f' still points to the same location, which is now a nonexistent file. This is a significant enough issue that FAT designers decided to ignore the problem, and not allow users to rename a file from one directory to another.
In order to fix this problem, the idea is to add a level of indirection to the file system. This is the basic idea of the Unix file system created in 1975.
The UNIX file system, ideally, has a layout consisting of all sectors in a row with the data at the end. There is also a table that contains information about the files. This table is called the inode table and is indexed by inode numbers. Inode is a data structure that contains all the information about a file that you see in “ls -l” including name, owner, group, permissions, and size. Towards the end of the inode table, there is an array of block numbers which will tell you where to look for the corresponding information. This data is in an 8KiB block, with block numbers being 32 bits wide. This represents a file system of the size 2^32 * 2^8 bytes. An inode entry is a fixed size, and each entry has no explicit file name either (it is stored elsewhere.)
A directory entry in an inode table is 16 bytes: the first 14 bytes are the name (if the name is less than 14 bytes, the remainder is 0’s) and the remaining 2 bytes are the inode number. For the UNIX file system, a directory simply maps file names to inode numbers.
One benefit of the UNIX system over FAT is the link count. The link count is the number of of directories or files that have a name/inode number mapping for a single file. This means that on Unix, a file can have many names across multiple directories. If the link count drops to 0, you can free the storage, otherwise you cannot free storage.
Another area, the block bit map, is just an array of bits that tells you which bits are free, it is one bit per block. This requires 1/65,536 overhead.
In UNIX, file cycles are not allowed, meaning renaming files is safer. When you try to rename a directory, the file system checks to make sure that the directory hierarchy has no cycle, but this makes renaming more expensive as it now requires a cycle check.
The original UNIX file system did not have a a rename system call, but instead had two different system calls: link() and unlink().
lseek(), which repositions the read/write file offset, is much faster in UNIX than in FAT if the FAT table doesn’t fit inside RAM. In UNIX, lseek() becomes order 1 from order N, and you can now have files with holes in them, which allows one to save disk space.
dd -> seek = 1000000000
bs = 1000000
echo x | dd seek=1bil bs=1mil > file
When this finishes, executing "ls -l" will reveal that the amount of space taken up by the file is around 16kb. Disk quotas are okay with this, but there's some backup software that copies all the files, and that backup software won't know about the holes, so it'll read nonexsistent null bytes and compress them. This process will take a long time, and system administrators will complain to you (or if you do it on SEASnet, they'll complain to Professor Eggert.) Using files with holes might be a good way to test file system code on big files without actually taking up space.
Notice that files no longer have one name or even any name necessarily; if you ask Unix the name of a specific file, there won't always be one name. Files can even have a link count of zero. The reason for this is that as long as a process has a file open, the file won't have its storage reclaimed, even if the link count is zero (all names have been removed.) While it's nice knowing the file won't disappear, the downside is df (which displays the amount of available disk space) might report that the file system is full because someone is linking to a big file, whereas du (which displays an estimate of file space usage) might say there's plenty of space.