|
We would like to create a boolean condition in order to define a certain variable. Keeping track of this will be the programmer's responsibility, therefore we need to think of when the variable is allowed to be changed, and by what process. We need a blocking mutex to protect the condition. Only processes that own the mutex can change the condition. This will prevent any race conditions. Here is an example of how to implement a blocking mutex.
1. typedef struct{
2. splinlock_t l;
3. proc_t *blocked_list;
4. bool acquired;
5. } bmutex_t;
6.
7. typedef struct{
8. proc_t *next_blocked;
9. } proc_t;
10.
11. void acquire(bmutex_t *b){
12. for(;;) {
13. lock(&b->l);
14. current_process->blocked; //current_process is a global variable that points to the current process
15. current_process->next_blocked = p->blocked_list;
16. p->blocked_list = current_process;
17. if(!b->acquired) break;
18. unlock(&b->l);
19. schedule();
20. }
21. b->acquired = 1;
22.
23.
24.
25. void release(bmutex_b *b){
26. lock(&b->l);
27. for(proc=b->blocked_list;*proc; proc=proc->next_blocked){
28. proc->blocked=0;
29. }
30. b->acquired=0;
31. unlock(&b->l);
32. }
Below is the API: 1. wait(condvar_t *c, bmutex_t *b) 2. //precondition: b is acquired 3. //releases b 4. // - asks until some other process notifies that condition may be true 5. // - reacquires b 6. 7. notify(condvar_t *c) 8. //wakes up a thread waiting for condition to be true 9. 10. notifyALL(. . . ) 11. broadcast(. . . ) 12. //notifies all threads 13. Semaphores: A semaphore is like a mutex, except it protects N instances of a resource, not just one. It is locked when int == 0, and unlocked when int > 0. Implementation Example:
1. struct pipe{
2. char buf[N];
3. unsigned r,w;
4. bmutex_t b;
5. }
6.
7. char readc(struct pipe *p){
8. acquire(&p->b);
9. release(&p->b);
10. return c;
11. }
Deadlock: A deadlock occurs when two competing processes wait for each other to finish, therefore neither does. Deadlocks cannot always be anticipated Example: Implementing a fast cat a | cat | b 1. while((n=read(0,buf,sizeof buf))>0) 2. write(1,buf,n); 3. while(xfer(0,1,n)>0) 4. continue; 5. return c; 6. } 7. 8. // The first pipe is waiting on the second pipe. Also the second pipe is waiting on the first pipe. 9. // This cycle of dependency is known as a deadlock.How we can avoid deadlocks entirely
Problem: computers have a storage hierarchy in which the fastest storage mediums are limited by space. Storage Hierarchy (by speed) ALU (a few nanoseconds, ~1 cycle ) How can we design a file system to be as efficient with storage as possible? We will mostly focus on the flash and hard drive portions, since these are infinity slower compared to the other memory modules. A hard disk is made up of one or many magnetic platters. Each platter has a magnetic head mounted on an arm that is able to move across the platter in order to read and write data. By the nature of the physical form of the platter, data is written in circular patterns. A platter can be divided up into a number of tracks, concentric circles around the disk. A track can be further divided up into a number of sectors, segments within each circle. A cylinder is formed by several overlapping tracks from multiple platters. 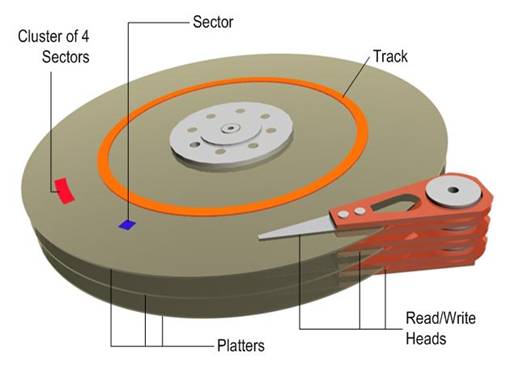
Things to consider: Here is what actions a hard drive must undergo when grabbing a random sector off the disk:
Typical Hard Disk Performance Specifications
The write time is slower than the read time because reads can be sloppy and in approximately the right area to get the correct data. Writes must be exactly on target so that all tracks and sectors have uniform spacing. typically burst speeds are close to this rate since the read head does not have to move as much initially. This is slower than the max internal transfer rate as the head may need to grab data from anywhere on the disk Often the advertised speed of hard drives. (this can be reconfigured to 520, 524, or 528 bytes per sector) For a comparison, below are some specifications for a solid state drive.
Typical SSD Performance Specifications
Immediately one can notice that SSDs have much faster read and write speeds, particularly they excel at random reads and writes.
It is important to note that the main drawback for SSDs are their limited read/write cycles Here is an example of reading from a hard disk.
a | cat | b
1. for(;;){
2. char c;
3. if(read(0,&c,1)!=1)
4. break;
5. process (c);
6. }
Each read will take on average: 8.5ms (seek latency)+ 4.16ms (write latency) +0.005ms (time from cache to registers) Naturally, the worst read condition is reading 1 byte from random locations. Batching: Batching requires reading data in large batches so that control overheard is less per byte. Instead of reading just one byte we read entire sectors.Prefetching: Prefetching has the OS guess future reads and saves them in cache.Dallying: Dallying delays writes to allow programs to possibly schedule more things to be written. It tries to fill a sector in one write cycle. |