A file system is the data structure designed to control how information is stored and retrieved. Without a file system, one would not be able to tell where one piece of information stops and the next begin in a storage area with a large body of information. The file system organizes the data blocks into files, directories, and file information. It can be thought of as an index or database containing the physical location of every piece of data on the hard drive.
Inode (index node) is a data structure that stores all the information about a files system object or directory such as file ownership, access mode (read, write, execute permission), and file type.
|
Symbolic Link |
Files that contain file names |
|
File Names |
e.g. "a/b", "foo.c", "/a///c/d" |
|
File Name Components |
Names of directory entries e.g. "foo.c" |
|
inodes |
ino_t |
|
File System |
Resides in each partition. Each file system contains a superblock, bitmap, inodes, and data blocks |
|
Partitions |
Contains all blocks. Includes a partition map in the beginning and several partitions follow. |
|
Blocks (8192 Bytes) on a disk |
Linear array |
|
Sectors (512 Bytes) on a disk |
Linear array |
Each file has its own inode number and you can use the ls -i command to find that number and more inode information. Unique files can have the same name due to this because files are not represented by their names but rather by their inode number. There are two types of links. The first is a symbolic link, also known as a soft link. The second is a hard link.
To see how inode numbers work, consider the following system call:
open("/usr/bin/sh", O_RDONLY);
The algorithm used to go through the system starting at the root is as follows:
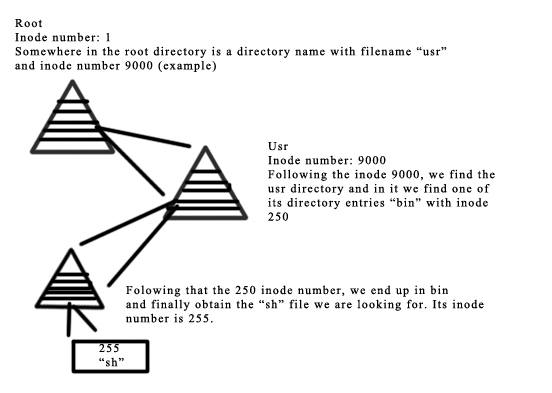
The mount table is an index of inode numbers and it is stored on a known location on the device. From the inode number, the file system driver portion of the kernel can access the contents of the inode, including the location of the file allowing access to the file.
The chroot system call on unix operating systems is an operation that changes the apparent root directory of the current running process and its children. Once a process calls chroot, it is no longer able to return to a previous directory because the previous directory of root is root. Thus, be careful when using this system call. Once chroot is called, the program cannot see or access files outside the designated directory tree. This root directory is referred to as the chroot jail.
A limit on the file name length of a symlink exists.
There are multiple ways to store a file name in a symlink:
Using directory entries to store file names of symlinks can cause removal of data to take a lot of time. The removal of a directory using this command,(e.g. rm -rf "/dir"), has a time complexity of O(n^2). This is because in order to delete a specific entry there is a linear search. However, using a hash map for organizing the directory entries can improve the complexity to O(n).
In terms of security, removing files using the "rm" command does not actually delete the data. The command actually just unlinks the entries from the inodes. The inodes and the data blocks are untouched on the disk and can be recovered. In order to completely wipe the data out, one can write randomly generated bits to the file ready for deletion and then removing it.
We can use this sequence of commands:
dd if = /dev/random of = file
rm file
The shred command can also be used to wipe out actual data on the disk. It uses its own random number generater and write multiple times to the file before unlinking:
$shred file
Data can still be recovered after shredding however. Solid state drive also known as SSD does its writes on random blocks instead of replacing original data. Thus the only way to remove the data is by shredding the whole disk. Data blocks in magnetic hard drives have bad blocks witch will cause a problem with shred.