Strategies to Tackle the Problem
- Message getting corrupted (Say, there's a byte error)
Checksum the message (at least 32 bit):
This would be done at the protocol level (end-to-end) since it increases the chance of detecting corruption. If the message is corrupted, the client should resend it. - Response Timeout (No sequence number when following TCP)
*The client has no idea whether the server got the message. Do you keep trying ? Do you wait for the server to return an eror message ?*This problem has several differnet solutions:
- At least once RPC: You Keep trying. This is suitable where doing something twice doesnt hurt you. In other words, the requests are idempotent.
- At most once RPC: Return an error
(err = ETIMEOUT). This is not suitable for idempotent requests. The drawback here is that the application must know about the error - Exactly once RPC: What we want. You can never really fully build this completely, there will always be some source of error.
X Window System Protocol
Theoretical Implementation
The system was developed 30 years ago and is still in use in netwoking functions.
Working of the protocol in theory -
Client: Send X Send "blue" Read reply |
Server: Read Y |
The client sends request in queue and waits for the server to respond. The above theoretical implemetation of the protocol is really slow and the following are some ways to speed up the process.
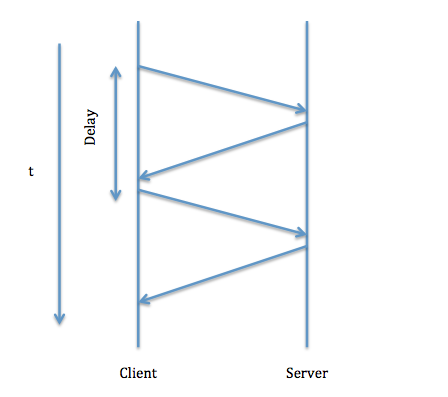
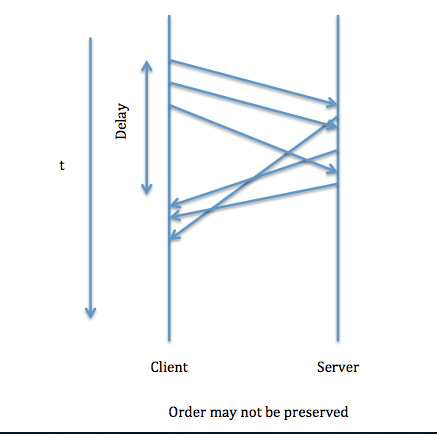
Images taken from http://www.cs.ucla.edu/classes/spring12/cs111/scribe/16c/
Protocols to Improve:
- Give up the idea of using RPCs since they take too long.
- Use Batch calls: Doing a bunch of calls at once to improve performance. The only problem is that the API would have to be changed.
- Make calls in parallel
- The requests may collide with each other
- More load on server, net, client
- Requests should not assume earlier request worked
- Requests can be served out of order
- HTTP pipelining: Lets you issue several requests simultaneously and get reponses at once
- Cache results of inquiries
- Prefetching: Look at old answers and predict answers to future requests.
Network File Systems
Network File System is a file system protocol designed to let clients access files and data shared on a server. The client accesses these files via the NFS protocol which is a form of RPC. The protocol syntax resembles the UNIX system calls to a large extent.
NFS Protocol
CREATE (dirfh, name, attr) -
Return file Handle and attributes
MKDIR (dirfh, name, attr)
REMOVE (dirfh, name)
RMDIR (dirfh, name)
LOOKUP (dirfh, name) -Return file Handle and attributes for the requested file
READ
(fh, data)
WRITE (fh, data)
So what is a 'file handle' ?
Essentially, it is a large integer (much like an inode number) that uniquely identifies a file on a server. The server has root priveleges since it needs to access file names by their inode number and needs access to the kernel.
A naive implementation requires NFS servers to keep track of client state. this is troublesome since the server would now be at the mercy of the client. However, according to NFS model, the server doesnt care about the client state. In other words, the NFS server is stateless, if it crashes or reboots the client wouldn't notice or care (except for performance).
NFS Synchronization
However, the NFS client does guarantee close to open consistency. This means that if client 1 issues a close command for a certain file and client 2 issues an open command for the same file, client 2 will open the a correctly updated version of the file. This is due to the overhead induced when closing a file as mentioned above in the Parallel Issues section: when a file is closed, all pending writes are finished first before the file is finally closed (remember closes are "slow"). Thus, when client 2 opens the same file, it will have the correct updates to the file.
NFS faces synchronization issues.
For example:
Process 1:
Gettimeofday()
Read (fd, buf, 1024)
Process 2:
Write (fd, buf, 1024)
Gettimeofday()
If both requests start at the same time then the read request will return a cached value. Thus, it does not have read after write consistency.
However, the client does have open after close consistency. If client 1 issues a close command for a file and client 2 issues an open command for the same file, client 2 will open the correct updated version of the file. This is because when the file is closed, all pending writes MUST BE finished before the file is opened again.
Hitachi Uniform Storage file mode 4100:
This is a network file system whose specifications were examined in class. The file system is a four node cluster storage subsystem with an overall response time of 1.25 ms. http://www.spec.org/sfs2008/results/res2013q4/sfs2008-20130905-00229.txt
Specifications and test result of such filesystems can be measured from specbench.org which follows the SPECsfs2008 benchmark.