Scribe Notes: Lecture 17
Table of Contents
The Problem: Calling a Foreign Function
Back to top ↑It is trivial for a program to call its own functions because the program has its own address space. The code for the function can be executed directly and any pointers or file descriptors passed to the function will be valid because they are part of the same address space and are run on the same machine.
However, what happens when we want to extend the idea of calling a function to apply to a separate process or on a separate machine? We cannot simply tell the processor to jump to the code of that function, because we do not even know what that code is. We need some way of communicating our needs to the foreign process, along with a way of reading the result...
The Solution: Remote Procedure Call
Back to top ↑In order to call a function in another address space (whether this function exists in another process on the same machine, or on a different machine altogether), we introduce the concept of Remote Procedure Calls. A remote procedure call is essentially any way of calling a function in a different address space. The definition of remote procedure calls does not say much about their implementation.They can be implemented on top of any protocol running over any communication medium.
Pros and Cons
Here are a few pros and cons of using remote procedure calls versus some other mechanism, such as having processes share an address space (if both processes live on the same machine):
Pros
- There is no way of corrupting the memory of another process.
- The caller and callee can have different architectures. For example the caller might be x86 whereas the callee might be SPARC.
Cons
- We must copy any necessary data back and forth.
Implementation
Back to top ↑How would we implement something along the lines of RPC?
Network Convention
At the very basic level, we would need to choose a network convention. We may choose one of three conventions:
- Little Endian
- Big Endian
- Flagged
These are a set of conventions which specify the ordering of data either at the bit level or more broadly at the byte level. For example, they may specify the ordering of bits in a one-byte integer, or they may specify the ordering of bytes in a four-byte integer.
In Little Endian, the least significant bits of a number or other data element
are presented first. For example, a binary number such as 11100001 would be
represented as 10000111. As a more complicated example, we may have
a Little Endian convention which only specifies at the byte level but not the bit level.
In that case a number like 11100001 11100010 might be represented as
11100010 11100001 in Little Endian, with only the bytes rotated, but not the bits.
In Big Endian, the most significant bits are stored earlier. For example
our binary number 11100001 would be stored in the same order that our
textual representation displays it: 11100001.
In a flagged system, the endianness is explicitly stated during the connection by a flag that is sent, and all further data is assumed to be under the flagged convention.
Glue Code
Imagine we have a caller who wants to call stat(int fd, struct stat* st);
This will not work over the wire because neither the file descriptor nor the pointer arguments will be valid in a foreign machine. We need some way of converting the arguments to a transferable form - we need some glue code.
If we had some kind of automatically run code that was called with every RPC call, then the programmer would be able to easily write code without worrying about the details of RPC. This is "glue" code or "stub" code.
Glue code must be able to pack the arguments and return values. This "packing" is also known as marshalling, serializing, or pickling.
On the caller's side, the glue code will:- Pickle the arguments
- Ship them over the network
- Receive the pickled arguments over the network
- Unpickle the arguments
- Call the function
- Store its results
- Pickle the results
- Ship those over the network
- Receive the pickled results
- Unpickle the results
- Return the unpickled results to the caller
The only problem is that someone must actually write this glue code. Who is going to do it? It's a very tedious process.
Thankfully, glue code generation is typically automated. Unix has a tool called rpcgen which will automatically
generate glue code from a protocol specification.
RPC Failure Modes
Back to top ↑Many things could go wrong with RPC.
- Messages can get lost - the buffer might be overloaded or there be a transmission error on one of the wires.
- Even worse - messages can get corrupted
- The network might go down, or it might be slow
- The server might go down
Error Detection
We can detect corruption in messages by passing a checksum of the message along with the message itself. This is done at the protocol level, end-to-end. If the message is deemed corrupted, we will re-send it. This approach is not perfect - if the network is so bad that every message is corrupted then this will fail miserably.
Message loss can be detected through timeouts: if we do not receive a response within a reasonable amount of time, we should timeout the connection. We have no clue whether or not the server actually received the message. We have three classes of RPC which deal with timeouts in different ways:
-
At-least-once RPC
- Here we keep trying to send the message
- This is suitable for requests that are idempotent, i.e. that repeated executions have the same result as one execution and are therefore harmless
- An example would be a function to zero out a bank account. Once the account is zeroed out once, repeated applications will be harmless
-
At-most-once RPC
- Here we fail immediately after the first timeout (errno == ETIMEOUT)
- This is more suitable for non-idempotent requests
- An example would be a function to pay someone a set amount of money. Repeated applications of this would cause the caller to lose more and more money
-
Exactly-once RPC
- This is the most ideal case
- We would like to implement this for all RPC mechanisms but often the implementation is too complicated and expensive for the use case
RPC Optimization
Back to top ↑Take the Linux windowing system, X. How would we allow a windowing system like the X Window System to work across a remote machine?
We could send the data pixel by pixel, coordinate by coordinate. We could send the x coordinate, then send the y coordinate, then send the color of the pixel. The server would then read x, read y, and read the color all in sequence. It would respond to the client with a confirmation message which the client would subsequently read. This entire process would happen for every pixel on the screen that needed to be changed.
What's wrong with this? It is extremely inefficient.
Bad Solution
One solution is to avoid RPC altogether since the overhead for each function call is drastically increased.
Batching Calls
But this is extremely drastic. Why don't we just batch calls? We could send vector information for a shape to be drawn, or we could send a large number of pixels stored in memory and transfer them all at once. The only problem with this is that we are modifying the entire API solely for performance reasons. However, the performance benefits are necessary and worth it.
Parallel Calls
Another independent but not mutually exclusive solution is by doing the calls in parallel. Rather than waiting for the server's response before sending the next pixel, we can send all the pixel information out at once with separate calls that do not block. The sever will then receive all the requests, possibly out of order, and draws the appropriate pixels, sending the responses as it goes. This will only work, however, if the calls do not rely on the order of their execution. If the pixels are independent this is fine. However, if we are drawing shapes on top of shapes this could drastically change the output.
Caching Results
We may also want to locally cache results of a query. If we already asked the color of a pixel, there is no point in asking again as long as we know it has not changed. Since we ourselves are the ones who change the pixels, we would know if the pixel has changed and so this method is very reliable.
Prefetching Results
As a form of "future-caching," we may want to prefetch the results of possible queries. When we are idle, we could go out of our way and request other pixel values that we have not read yet, and then store these in the cache. Web browsers apply the same optimization to links on a page.
NFS: Example of RPC
Back to top ↑Network File System, or NFS is a way of accessing files on a remote machine. It is like a Unix system call for files - on wheels. A functioning implementation of NFS will have support for operations like read, write, rename, and mkdir - things that change the state of a file or directly. We do not care about operations such as dup or pipe which do not actually change the state of anything on the physical drive.
In the kernel, we have a table of each process's file descriptors. If we make a call like
read(4, buf, 1000), the kernel looks at the file descriptor table and determines
that the file descriptor points to an NFS-mounted filesystem, so it calls the NFS read function.
The NFS function properly transmits the read request over the network and eventually fills
the client's buffer with the results from the server.
Interface
The NFS protocol has a few interface functions:LOOKUP(directory file handle, string file name)- This returns the file's file handle and attributes.
- A file handle is a large integer which uniquely identifies a file on the file server
- It generally uses a form of the inode number of the file on the remote machine
- This requires help from the kernel, which leads to overdependence on the kernel for NFS
CREATE(dirfh, name, attr)MKDIR(dirfh, name, attr)REMOVE(dirfh, name)RMDIR(dirfh, name)READ(fh, ...)WRITE(fh, ...)
Statelessness
A naïve implementation of NFS requires the server to keep track of the client's state. This would require it to know which clients have which files open, which is a large inconvenience for the server. In the NFS model, the server doesn't care about the client's state - it is stateless. If the NFS server crashes and reboots, the client will barely notice and will not be affected except for performance.
Interesting Use Cases
Imagine that we run the following two commands inside an NFS-mounted directory:
(cat a & mv b c) > b- This works; we expect this because the file descriptor is independent
of the name of the file, so if the move (
mv b c) occurs after the output file is opened by the shell (> b), the file descriptor will still be valid in the shell's output code and the write will still work.
- This works; we expect this because the file descriptor is independent
of the name of the file, so if the move (
(cat a & rm b) > b- Against common intuition, this works too.
- Knowledge of the stateless nature
of NFS would make us believe that the file
bwould be deleted from the server while we are writing to it, since the NFS server does not know or care that we have the file open. - However, in reality the local kernel implementation actually knows that we have "opened" the file locally and so when it sees that the file has been deleted, it creates a temporary file with a jumbled name in order for the data to be placed somewhere.
Synchronization Issues
Imagine we have two processes. Process 1 calls read(fd, buf, 1024)
and Process 2 calls write(fd, buf, 1024). We cannot guarantee the order
that these calls are run on the remote server. We also have latency with local caching.
When we call write(...), it does not send the command to the server immediately.
It might cache the write locally. Then if we try to read the file from another client, it
will not have the expected contents because the write has not been flushed yet. As such,
the only time a file is guaranteed to have the expected contents is when close(...)
is called, because this is when writes are guaranteed to be completed.
The idea that writes can only be reliably read after the file is closed is called open-after-close consistency. The NFS design model supports open-after-close consistency but not read-after-write consistency.
Because NFS is unreliable when a file is kept open for a long time, it is a bad idea for databases, which make a lot of small writes to one big file. On the other hand, NFS works well things like small shell scripts which run on a file by file basis.
Realtime Benchmarks
It is often useful to measure the speed of an NFS system and implementation. The website www.spec.org does benchmarks of many protocols on many systems. In particular, they run a test called SPECsfs2008_nfs.v3 on a wide range of server models.
One model in particular has quite impressive results: The Hitachi Unified Storage File, Model 4100. This is a 4-node cluster (with 4 interconnected processors). It has 64 flash modules at 1 TB each. The team measured the response time in seconds of the system for various throughput values in number of IO operations per second. Essentially, when the system is executing x IO operations (such as read and write) per second, it has a certain response time y. The following graph was prepared by the team as a result of their measurements:
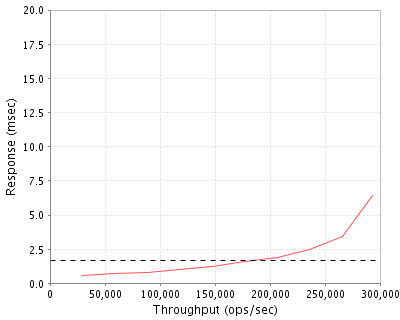
As seen in the graph, the response time is nearly linear up to a certain point. At this point, the response time shoots up and starts to look somewhat exponential. As such, there is a kind of "sweet spot" of performance, right around where the drawn line intersects with the graph. This point (seemingly around 200,000 ops/sec) is primarily where we want to be.