RAID
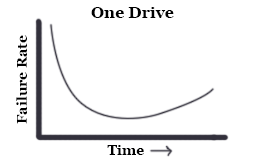
NFS servers have a lot of disks to increase storage space and parallelism. This comes at the cost of complexity and reliability. The graph on the left shows failure rate for a typical disk drive. The high probability of failure at the beginning is due to manufacture error. When multiple (say five) drives are combined in an NFS server, the probability of failure greatly increases because if one drive fails the whole system fails.

The solution to this reliability problem is RAID: Redundant Array of Inexpensive Independent Disks. It was originally developed to combine many cheap smaller drives into one big drive that's cheaper than buying an equivelently size large HD.
Types of RAID
RAID 0: Concatenation and Striping
Concatenation combines all the drives together into one big drive. Pros are that you get a cheap inexpensive drive. However, due to locality of reference, preformance isn't great. Since sequential blocks are normally located on the same disk, most of the time only one disk will be in use and the other ones will just be sitting there. This issue is solved with:
Striping maps consecutive RAID virtual blocks on to alternating physical drives. This increases parallelism, increasing drive preformance. The trade off made using striping alone is that if one drive goes down, you lose parts of all your data.
RAID 1: Mirroring
When mirroring, data is written identically to multiple (typically 2, possibly more) drives. This gives you a back up of your data in case one drive crashes. It also allows 2x read throughput, and because of different disk arm positions reducing average seek time, could possibly boost read performance even more. The trade off is that storage costs are 2x as much.
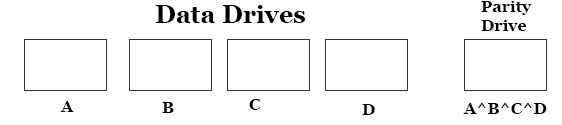
RAID 4: Parity Drive
RAID 4 provides added protection against data loss, but without the 2x cost of RAID 1. To gain this added protection you add one new drive after your data drives that stores an XOR of all the data drives. If any one drive fails, it's data can be computed by XORing all the other drives. For example if A crashes, you can recover it by computing B^C^D^(A^B^C^D). Exra cost is only 1/(N+1) compared to RAID 1. However, writes are expensive because you must write twice and read the other drives to compute the XOR. The parity drive also becomes a bottleneck, greatly reducing the amount of parallelism between drives.
RAID 5: Parity Drive With Striping
RAID 5 solves the parity drive bottleneck problem of RAID 4. The parity is spread out over all the drives, so that one parity drive doesn't have too much of a load. This increases parallelism, but makes it much more difficult to add an extra drive to the system.