CS 111: Lecture 18 - December 2, 2013
Kenneth Shi and Daniel Duan
Disk Failure:
NFS servers are often comprised of many disks:
|
Pros:
- Lots of space
- Able to abuse parallelism
|
Cons:
- Complexity issues
- Reliability of disks
|
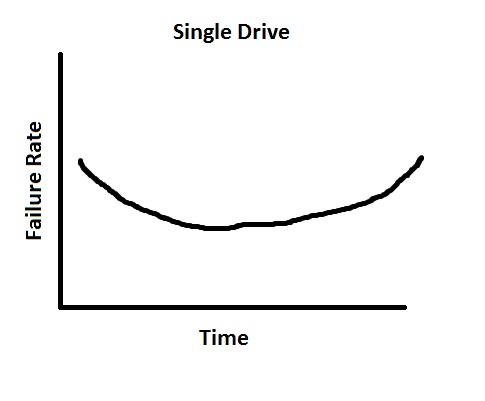
Let's suppose we have a single disk. This is what the "bathtub" curve for reliability looks like:
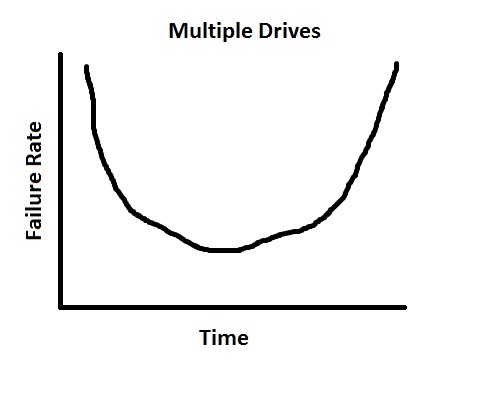
The failure rate for a file server with multiple drives (let's say 5) would look similar, except that the slope would be 5 times steeper:
RAID Storage Technology:
A standard technique developed to combat these disk failures is with redundancy. A technology used to implement this was developed by Professor David Patterson of UC Berkeley called RAID. RAID stands for Redundant Array of Inexpensive/Independent Disks, and is a storage scheme for dividing and replicating data among multiple drives. The reasoning for the "inexpensive" disks is due to the fact that if you can buy a large drive for X dollars, you can buy multiple smaller drives for a fraction of the cost and still have the same amount of data. For example, a 10 TB drive costs $2000 while a 1 TB drive only costs $100. Instead of getting the 10 TB drive, you can save money by buying ten 1 TB drives and pretending it's 10 TB drive. Redundancy in this case helps in preventing drive crashes since you can lose a small drive with minimal issues, as opposed to losing the entire 10 TB drive.
Here are the different types of RAID technologies:
There are many standard schemes that have evolved from RAID, each of which are called levels. Here, we'll go over RAID 0, RAID 1, RAID 4, and RAID 5 to see the differences between the different levels. Keep in mind that these levels can be mixed and matched, and that a NFS can incorporate more than one type of RAID.
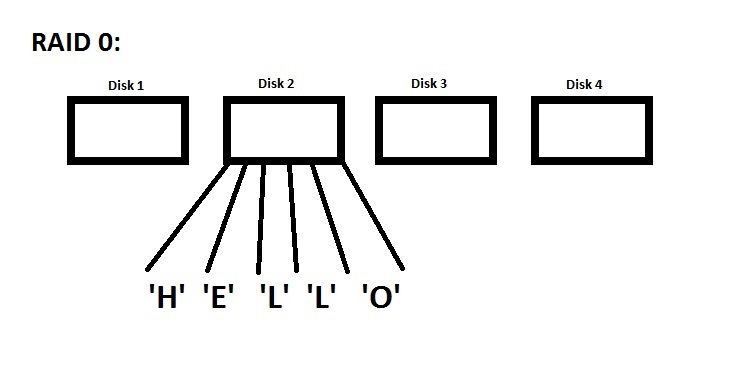
RAID 0: Concatenation and Striping
Concatenation is the simple of idea of taking multiple drives and pretending that they are concatenated with one another. Below is a diagram showing how data is stored on concatenated drives. Notice that since all the drives are concatenated and considered a single "large" drive, continuous blocks of data in virtual memory are also stored on the same drive.
Another way to do RAID 0 is Striping. If you have to do a lot of consecutive I/O and your virtual disk are just physical disks concatenated, then you have a performance bottleneck because all your data is on the same physical drive. Striping puts data on different physical drives to split up the reading of consecutive blocks, as the image below demonstrates.
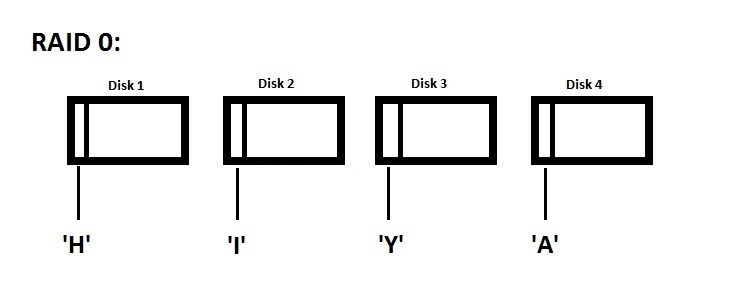
A downside to striping is reliability - if one disk crashes, there's a good chance that you can lose all your data (or at least lose blocks from all your files).
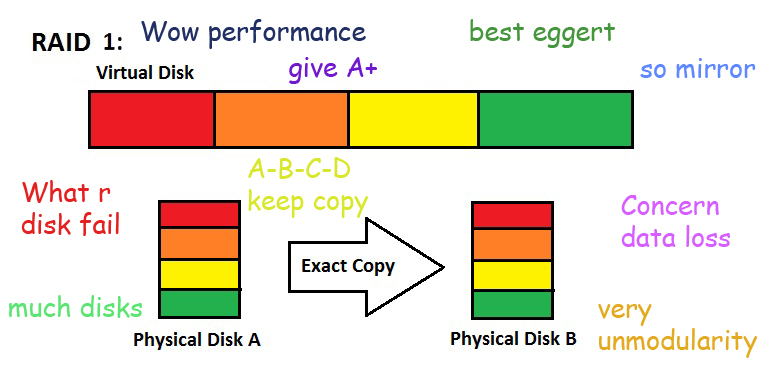
RAID 1: Mirroring
Mirroring is taking two drives, and copying the data from one drive to the other. This attempts to solve the reliability problem, because if one drive crashes you still have the other drive to read from.
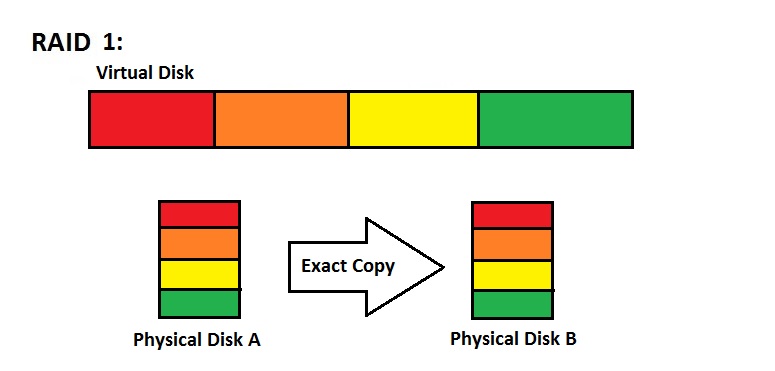
There could also be twice the read throughput, since you could read from the two identical drives in parallel. In some cases, you can even improve the reading by more than a factor of two. The downside to this is that writing is a little slower since you need to set up two writes, and you also take up more space since you're making a copy of an entire drive.
Now that we've been introduced to both mirroring and striping, is it better to mirror two stripes or stripe two mirrors?
The best way to answer this is to imagine if you have a system of size Z and you run out of space so you want to add to it. At the top level, what implementation would make it easier to expand? Concatenation!
RAID 4: Concatenation with Parity Disk
The basic idea of RAID 4 is that you have disks that contain your data (let's assume that this data is concatenated), then you have an extra disk that services as a parity disk. This disk holds data from all the other drives XOR'd with one another. Thanks to the laws of boolean algebra, if one drive crashes, you can figure out what was on the disk by XOR'ing all the remaining disks and the parity disk.
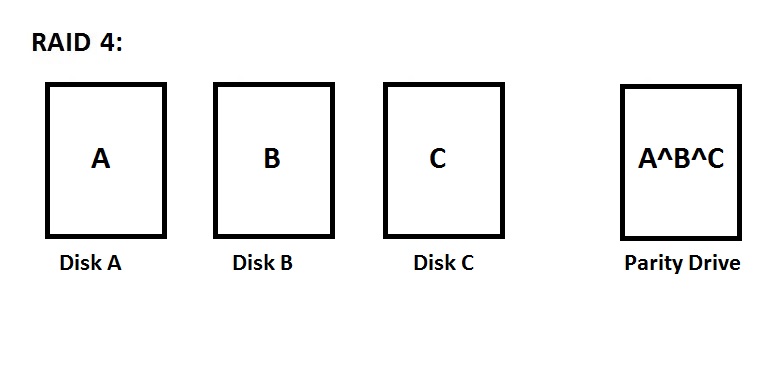
This is also cheaper than RAID 1, the cost is 1/(N-1) compared to having no parity drive, and the total cost is 1 + 1/(N-1). It's also easier to add drives to this configuration, since the blank drive wouldn't change the parity drive until data has been added. On the downside, this is complicated to set up, writes are more expensive because of the extra reads, and the parity drive becomes an I/O bottleneck, since you need to write to the parity drive any time you make changes.
RAID 5: Striping Parity Disk
Very similar to RAID 4, this implementation has a strip of parity data on all the drives. As a result, each drive has its own section of a parity drive.
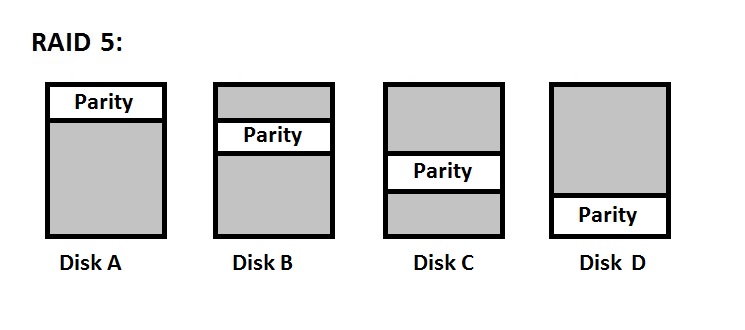
However, this setup makes it difficult to add a new drive (since the new drive doesn't have a parity strip).
Introduction to Security:
Imagine you're a student who's currently struggling in CS111. You decide hop on MyUCLA and somehow come up with a way to trick the website into thinking that you're actually Professor Eggert instead of a student sitting in his/her dorm. MyUCLA lets you in, and viola! You're able to change your own grades! Without any form of network security, it would be very simple for a client to spoof their data and trick a file system into thinking they are someone else. You could have the power to change everyone's grades!
As you can imagine, NFS security is a big issue that programmers need to worry about. Here are a few examples of security issues that we need to be aware of:
- Client spoofing: Like the example above, client spoofing is when an attacker tricks the system into thinking they're somebody else
- Server spoofing: An attacker makes us access another server (instead of the one we think we're accessing)
- DDoS Attacks: Denial of service attacks overload the server with so much information that it's unable to function properly
- Man in the middle attacks: An attacker sits between the client and the receiver and is able to read all the data transmitted between the two
Many security problems are like this. Another example is the Supreme Council of Virtual Space, who control all network access on the Iranian internet. This council reports to the Supreme Leader, and controls all information flow in Iran. They've been known to play "defense" and "offense", so not only do they protect Iranian internet from outside attacks, they've also launched DDoS attacks on the BBC as well as jamming two satellite feeds.
We need a good model for security so we create a checklist and not forget something trivial that the bad guys can exploit. Here's one model of security:
There are 3 kinds of attacks (in order of importance):
- Against integrity: The goal of the attack is to "mess with someone's brain" and tamper with the victim's data
- Against privacy: Tries to cause an unauthorized release of information to the attacker
- Against service: Tries to deny service
What kind of checklist do we need in order to defend ourselves from these kinds of attacks?
In defense, our general goals are:
- Deny unauthorized access (not natural to test for)
- Allow authorized access (natural to test for)
- Be able to handle lots of bogus requests
Thread modeling and classifications:
Here are some common threats that can occur in a system.
- Insider goes bad: Someone from the inside decides to leak data to others
- Social Engineering: An attacker social engineers information from someone on the inside
- Network attacks: Includes buffer overruns, SQL injections, and drive by downloads
- Device attacks: Viruses on portable devices like USBs
To help with figuring out a way to design a secure system, we have Kerchkoff's Design Principle for Cryptographic Systems, which basically says that you should minimize what needs to be kept a secret, and always have the assumption that bad guys will learn your designs. This is a good way to prevent the design of faulty systems where everything is based off a single private key, because as a designer, you want to assume that somebody will make the key private.
Here are some general functions that are needed for almost any security machanism:
- Authentication (check if a user is authenticated): e.g. a password
- Integrity (check if data has been tampered with): e.g. checksums
- Authorization (what the user have access to): e.g. access control list, .htaccess
- Auditing (keep track of what happens in a system): e.g. logging
- Efficiency: We want system to be efficient so that users don't need to wait 5 minutes to be authenticated
- Correctness: While security is important, we also want to make sure that we don't lose features from the original system we're trying to make secure
Authentication:
There are two types of authentication checks, external and internal.
- External (an outsider wants to get in): Ways to authenticate externally is with a password, a physical key, or possibly a biological confirmation tool. External authentication has been improved by two factor authentication and cryptographic authentication (where passwords are cryptographic checksums of passwords using a hash like the SHA1).
- Internal (an insider wants to access certain components): An example is the User ID in a process table.