CS 111 Lecture 4 Scribe Notes (Fall 2013)
Prepared by Shuang Yang, Xinyou Yu and Guangyu Li
Table of Contents
- The class-based organization
- Goals for OS
- The layer-based organization
- System call
- Micro-kernel approach
- Resource management
- Switching processes
- Process model
- Manage processes using opaque identifier approach
The class-based organization
One way to organize our OS modules is by using classes:
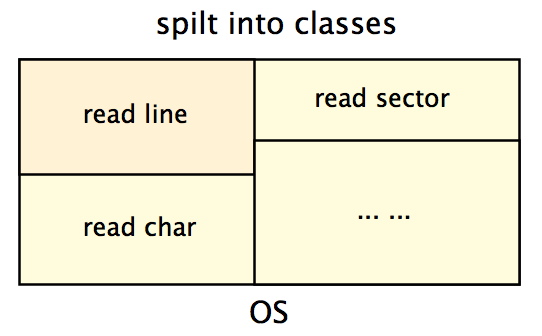
Different modules do different work.
This is how Apple's first OS is organized. However, they later got into trouble with it. What’s the problem?
To understand this organization’s weakness, we need to know what are the goals only for OS but not for applications.
Goals for OS
An ideal operating system must have the following features:
- Protection - If one module crushes, it won't crash the whole OS.
- Utilization - All parts of the OS should be busy working, instead of waiting for other modules.
- Flexibility - When we change part of our modules, we do not need to compile and relink the whole OS.
Unfortunately, the class-based organization cannot achieve these goals, so we need a new method.
The layer-based organization
Instead of splitting the OS into classes, we divide it into layers:
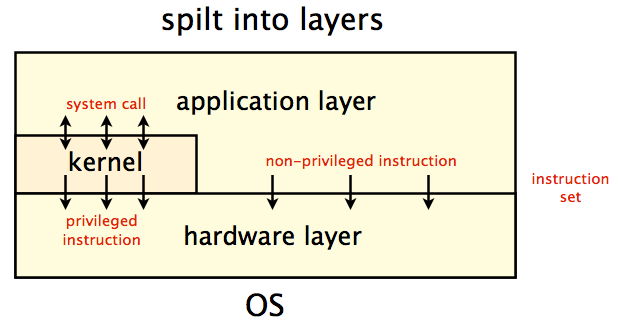
The whole computer system is divided into two parts: hardware and software
Software uses instruction set to communicate with hardware.
Instructions set can be divided into two groups:
- Privileged instructions
- Non-priviliged instructions
Example: HALT, INB, INT
These are dangerous instructions which may do something harmful for our OS if used by untrusted software.
Example: SUB, ADD, MUL
These are normal instructions.
Based on what kind of instruction software can run, software is divided into two layers:
- Kernel
- Application
Can run both privileged instructions and non-priviliged instructions directly.
Can only run non-priviliged instructions directly, and need to use system call with kernel to run privileged instructions.
In this way, only the trusted layer, kernel can run privileged instruction and applications cannot crush our system.
System call
When a program requests a service from an operating system's kernel, it uses system calls. A typical way to implement this is to use a software interrupt or trap. A trap is an exception in a user process caused by division by zero, or invalid memory access (by using privileged instructions). It does a protected control transfer to the kernel and the kernel then goes to the ISV (interrupt service vector) to check what should be done.
Here we use an example of instruction “INT (x)” to show how system call works.
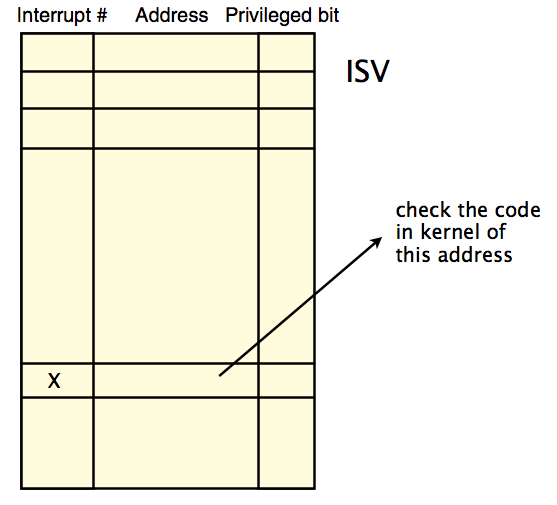
What does a protected control transfer do?
- Push 6 words on stack
- ss - stack segment
- esp - stack pointer
- eflags - privileged flag
- cs - code segment
- eip - instruction pointer
- error code - why we trap
- Set eip = ISV[x]
- Go to ISV and check(execute) the code in ISV[x]
- Call RTI (return from interrupt)
RTI basically restores the register from the stack, and return back to the instruction after INT in the process.
Step 1 is to store the registers in the caller. Then the eflags will be changed to kernel mode in order to run the privileged instruction
After INT and before RTI, the kernel has the full power to do anything like change from one process to another (change the value to restore), kill a process (do not return at all). This allow us to do some cool staffs, but if the kernel gets hacked, our system will be in danger. In order to solve this, we can do it once more.
Micro-kernel approach
Instead of having one single kernel, we can have multiple kernels, which improves the security.
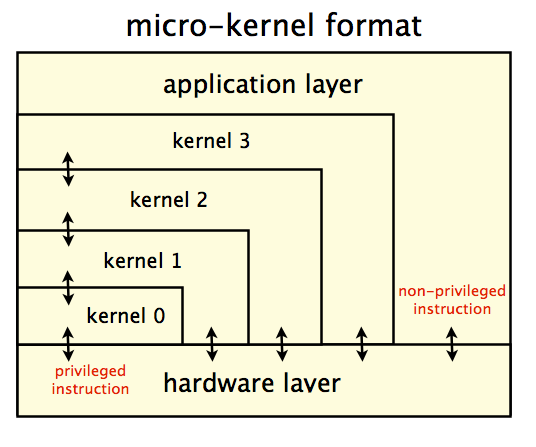
The eflag register in a x86 system indicates which layer(among the 4 levels) is currently in.
Only the lowest layer (kernel 0) can have full power to run privileged instruction. The higher layer can only run part of them, so if it gets hacked, it cannot mess up our system.
Comparing to monolithic-kernel approach, this approach has more security but will hurt performance.
Mac OS-X uses Micro-kernel approach while GNU/Linux uses monolithic-kernel approach.
Resource management
All the resources on the system has a priority to indicate whether they can be accessed by user code or only the kernel.
Here are the common resources:
- Full access for user code:
- No access for user code (only kernel have access):
- “Gray Area”:
ALU, Registers - frequent needs for application; should have full access in order to improve performance
I/O devices (such as keyboard) - used at very low frequency, and may hurt security if accessed by user code
Primary memory - has access to some memory, not to the rest, using approach of virtual memory
The kernel controls these resources and decides how to allot them to different processes. When a process runs, it has its own registers, but what happens when it switches to another process?
Switching processes
When several process are running, each of them consider itself as if it is the only process running and has access to all the system resources. However, this is not true in real machines, and the OS is in charge of switching between different processes.
In order to manage multiple processes, we use a process descriptor table to store those information.

When switch to another process (by a system call), the kernel stores registers needed for that system call in the table, and when return to this process, the kernel just goes to the table and restore them.
Process model
A process is a program in execution on a virtual machine. Since we can switch between processes, we can have multiple processes on one machine.
There are two main approaches to model process:
- Object-orient
- Opaque identifier
We can have a class Process, and map the processes into the process table.
This is a very common way used by many OS
Instead of a class, only use a unique number for a process. When we use that number to get that process, it will trap into kernel and look up the value on the process table.
This is a more secure way and it doesn't need to recompile when the processes are changed.
This is the way used by Linux.
Manage processes using opaque identifier approach
Create a process
In order to make our create_process method as simple as possible, by skipping all the arguments, the only way to create a process in linux is fork().
Fork() takes no arguments. When a process forks, it creates a copy of itself. The original process that calls fork() is the parent process, and the newly created process is the child process. The child process returns 0, and the parent process returns the id of the newly created child process from the system call. It returns -1 if it failed to create a new process.
Depending on the values fork() return, different parts of the code will be executed.
Destroy a process
After knowing how to create a process, we need to know how to destroy a process. The way to destroy a process is to call exit(int) in the process itself.
There are some different exit functions in linux
Noreturn VOID exit(int); // will clean the IO buffer NOreturn VOID _exit(int); // do nothing but exit NOreturn VOID _EXIT(int); // a more rude way than _exit.
Wait a process
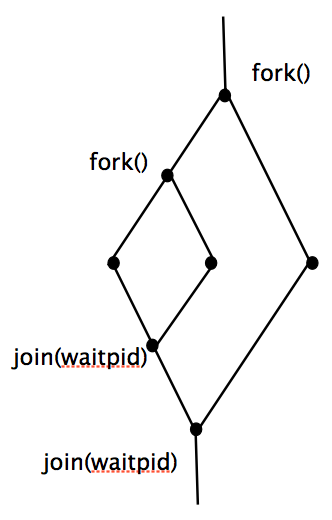
We also use waitpid() to manage the child processes
pid_t waitpid(pit_t process, int *status, int options)
Waitpid() waits the child process until it ends, and return the pid of the process that exited.
This is usually called “join” as it merges two process line.
Zombie process
When a child process has completed execution but its parent is doing other things before waiting, this process will still has an entry in the process table which is needed to allow its parent process to read its exit status. This is called a zombie process.
The zombie process will stay there until its parent call waitpid on it. If the parent process exited without making the call, the zombie process will stay in the process table forever and taking up system resources. To prevent this, linux has a root process, which is technically parent to all other processes. It waits for all the processes and cleans up zombies at runtime.