Use modules! (or "classes" in C++ terminology)
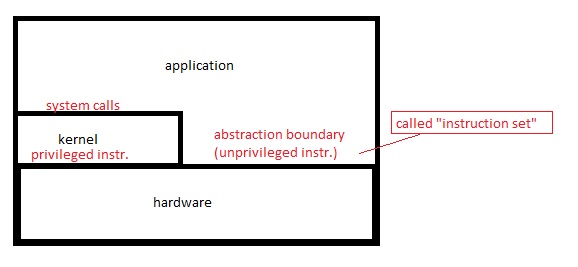
Applications can use the instruction
INT x
(protected transfer of control to location specified by the x word in the Interrupt Service Vector (ISV)) to transfer control to the kernel.
This is also equal to:push ss (stack segment) esp (stack pointer) eflags (privilege flags) cs (code segment) eip (instruction pointer) error code set eip = ISV[x]The instruction RTI (called by the kernel) undoes INT.
During the time which kernel has control, it can do whatever it likes to the stack-- including jumping to another segment of code! This can be used to resume some other process.
The kernel in this case is thus very powerful. So bad things can happen if the kernel is hacked. So we may want a smaller, less powerful kernel:
eg. OSX
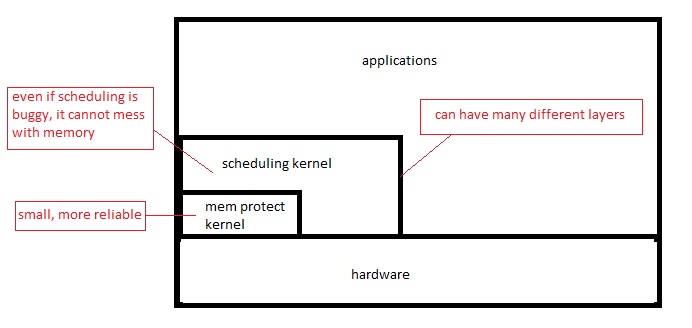
Disadvantage:
As number of layers increase, performance decreases.
This is not a problem if there is only one bigger kernel ("Monolithic" kernel, eg. GNU Linux)
What resources are the kernel managing?
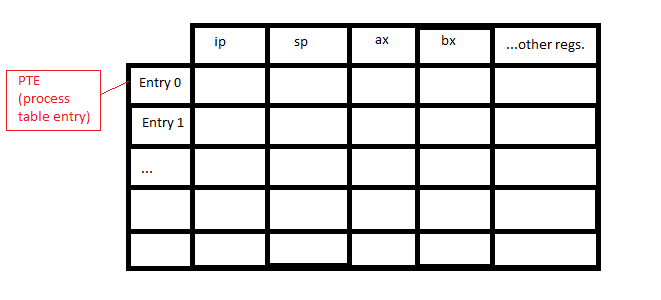
A process table contains general information about each process (one process per row). That includes the process id, its parent, registers and so on. One important element is the state of the process. This table is an organizational tool used by the OS to handle all started processes.
struct process {
//declaration of variables and functions
}
Method B: Using opaque identifiers ("handles")int ip = get_process_id(30);When the above instruction is executed, the kernel will try and find a match for "30" in the entries of the process table and will return correspondingly.
Which method should we pick?
Even though method A seems more natural and is a lot more straightforward, it lacks security and flexibility. Method B is more secure in the sense that it prevents programs from finding out information about the processes. If we were to make changes to our system, method B would still be able to run completely fine whereas for A, recompilation is needed. Therefore, the answer is B.
pid_t p = fork();The fork() function creates a new process through cloning. However, it is not an exact clone. The child process gets its own stack/memory that it works with. The return value is one of the following:
If an error has occurred, errno will be set to either EAGAIN or ENOMEM. In the case of EAGAIN, it indicates a lack of necessary resources and ask to try again later. For ENOMEM, the error occurs due to insufficient memory.
Examples:while(fork()) //parent will keep forking if it acts faster than the child continue; //if child is faster, exit. exit(0);Destroying a process
_Noretrun void exit(int);Polite version; Will try to flush out I/O but may not actually exit
_Noretrun void _exit(int);Never returns and destroys process that is currently running
_Noreturn void _Exit(int);Harsh version
pid_t waitpid(pid_t process, int *status, int options)The function returns the pid of the process that has exited or -1 if an error has occurred. The exit status is stored into *status.
In the case where a child has exited and its parent is still running but has not invoked waitpid, the child becomes a zombie. This means that the child process itself has ended but there is still an entry for it in the process table. If the parent then decides to exit and has still not called waitpid, the zombie child gets reassigned to process 1 which is created by the kernel. Process 1 has a loop which "reaps the zombies":
while(waitpid(-1, &i, 0) continue;This loop waits for any process and thus cleans up zombie processes.