Organizing Operating Systems
Lecturer: Paul Eggert
Scribes: Sony Nguyen, Clinton Tran, Alvin Ho
Lecture 4
In organizing operating systems, we want to utilize insulated pieces to divide up the work. A possible method that one may think is to utilize modules.
* Perhaps utilizing object-oriented programming like using classes in C++ with function calls may be helpful
What issues would we encounter?
- Complex: Complicated intermodular relationships.
- Inefficient: Due to complexity and numerous pointer handling.
- Inflexible: When we change one module, it might effect all of them!
- Uninsulated: Objects may alter or destroy each other unnecessarily!
Hence, modularity by classes is not the option we want to take.
OS Goals:
There are certain features that we would like to have to build an awesome OS:
- Robustness - The ability to respond to abnormal situations or handle errors
- Insulation - Prevents unauthorized memory access from certain processes
- Utilization - Keep multiple/all parts in frequent use, inhibited by modularity
- Flexibility - Portability across multiple machines
- Protection - User security
Basic Approach: Layering as opposed to Class Modulation
What we want to do is to create layers where each layer has some access to hardware functionality, but requires calls to other layers for the rest of the hardware functionality.
An application that would want to access a privileged instruction would need to do the following:
1) Application calls for an interrupt (INT)
2) Execute privileged instructions through the different layers
3) Hardware receives the commands and executes them.
4) The application is then returned to (RTI) and continues.
Similar to the instructions, CALL and RET of regular function calls, INT and RTI are instructions that allow the application to switch to kernel mode and let certain privileged instructions be executed before returning back to the application.
- Observing this, we can see that the kernel almost has total power. Process layering away from the kernel limits complete power to the kernel.
There are multiple layering schemes, but in general more layers provide more security but makes performance suffer.
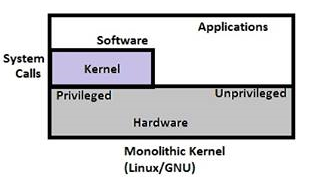

The examples above show two types, monolithic kernel and micro kernel. The micro kernel has an additional 'scheduler'
layer in this case, which allocate threads and helps alleviate tasks going through the kernel. Some privileged commands
do not require interacting with the kernel memories (such as IO commands), and thus can go directly between the scheduler
and hardware.
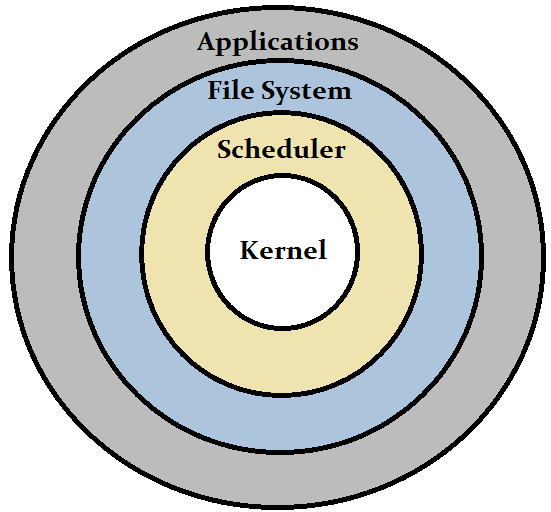
Alternatively, these layers may be nested on top of each other, such as on x86 machines!
So, exactly What resources are we managing?
- ALU (computation) - full access to user code: for performance and practicality
- Registers (e.g. %eax, %esp) - full access to user code: for performance and practicality
- Primary memory - full access to some, no access to others
- I/O Devices (keyboard, etc.) - kernel only: to prevent keylogging and not used frequently enough to justify full user access.
(NOTE: The distribution of access to certain memories is done by the use of Virtual Memory. Sometimes simple OS's don't have it.)
* An issue arises: say we store whatever we need into the kernel stack and then RTI. It looks as if we can just pop something
off the stack and resume some other process. However, stacks do NOT allow for continuous/parallel processing!
To solve this, we can introduce the process table.
| | ip | sp | ax | bx | ... | ... | ... |
| Entry 1 | | | | | | | |
| Entry 2 | | | | | | | |
| Entry 3 | | | | | | | |
| Entry 4 | | | | | | | |
| ... | | | | | | | |
The Process Table: stores processes with their ID's and register values in a lookup table. The processes can be loaded by
simply loading the data in their table entries.
Constructing a Virtualizable Processor and OS
In order to achieve layering, we will rely on managing processes.
* Process: a program in execution in a virtual machine.
How do we model processes in application programs?
A) Model it as an object:
class Process{...};/struct Process{...};
-> Can map into a process table entry
-> Can use pointers to model/indicate processes.
Downsides:
->If something is added or removed from the process table, have to recompile(inflexible)
B) Opaque Identifiers:
These are basically numbers or values that have no human meaning, but can be used for process API:
*EX: "30" <- (Handle)
-> Use system call to deciper the handle:
i.e. int ip = get_process_ip(30);
-> More security and flexibility because you can't mess directly with the 'pointers'.
-> More insulated from the OS.
-> Kernel deals with changes in the page table entries.
Virtualizing Processes, Basic functions as implemented by UNIX/POSIX standards.
Creating a New Process: fork()
In order to create new processes, instead of creating a new one entirely from scratch,
we can clone an existing process's registers and stack, while merely changing the instruction
pointer(eip), the stack pointer(esp), and the return value(eax), to the proper values we want!
This is much more efficient than creating a new process from scratch.
pid_t p = fork()
* fork() creates a clone of the current process
* Returns 0 in child
* Returns child's pid in parent (if successful)
(NOTE: the memories are also copied in each process.)
else (//if failed)
* return -1
* sets errno to EAGAN, ENOMEM
A Fork Bomb
for(;;)
fork();
Fork can still be a dangerous process! This code will fork until all process spaces are taken up or all memory!
Killing Processes
To kill a process that has finished executing, you can use:
_Noreturn void _exit(int status)
* Immediately terminates the current process.
* Closes all file descriptors belonging to the process.
* Exit status returned to the parent process through the variable "status".
_Noreturn void _Exit(int status)
* Even stronger version of the previous function.
Closing Out Processes: waitpid()
Any process that exits will become a zombie process and will wait until waitpid() is called before clearing itself for another process to take it's place.
Typically, a parent will wait on its children.
pid_t waitpid (pid_t process, int* status, int options);
*Returns the pid ofthe process that exited
*Stores exit status into *status
*Returns -1 if it didn't work
Note that waitpid can hang if the exit is unsuccessful.
What if the parent exits without calling wait on a child that has exited?
The child will exit
The parent will still run, but does not call waitpid. The child remains as a zombie
If the parent exits with a zombie child, the zombie child will be reassigned to process 1.
Process 1 should be configured to run
while (waitpid(-1, 0, 0))
continue;
which will wait for every child process.
Formatting inspired by Eric Bollens