
Yufei Chen, Cunpu Bo, Xiaoyi Zhang
Start with a very simple scheduling algorithm:
All process will call
yield(); |
every now and then.
Example:
int main(void) { int sum = 0; for (int i = 0; i <10000000; i++) { sum ^= i; if (i % 65536 == 0) yield(); } return sum & 0xff; } |
Example:
while (!ready(d)) yield(); |
while(!ready(d)) continue; |
The process will yield, but tell the OS, we are waiting for a particular device D to become ready.
waitfor(d) <----- disk controller
alarm clock
kernel scheduler records for each process what it is waiting for.
For polling, busy waiting and blocking, we are assuming cooperation. Sometimes you can’t assume this. For example, the program could have Loop with no syscalls. What then?
The second method is called timer interrupt. The process involves actual changes with the machine
This is called preemptive scheduling.
Pros:
Cons:
Preemptive scheduling does not solve infinite loop directly.
Example:
for(;;); |
Solution: we can place some limit onto the CPU time allowed for a process
e.g. ulimit -t [.....] +SIGXCPU |
The mechanism fundamentally does not change when the system becomes more complicated

you can think of each thread to be in charge. Each CPU could have separate timer to prevent locking, but the fundamental does not change.
for (int i = 0; i < 5; i++) { p = fork (); if (p < 0 && errno == EAGAIN) { sleep(1 << i); continue; } if (p >= 0) break; } |
Real time scheduling
The situation of scheduling is analogous to situation in real life. Think of yourself as a registrar. you have to decide:
etc.
How good is our scheduling algorithm?

Aggregate statistics for these time:
| (Customer point of view)
|
There are a few metrics that we need to look out for as a scheduler
Utilization: % of factory time for useful works (factory owner’s point of view)
Throughput: # of jobs / second
Fairness - every admitted job will eventually finish. (This interpretation is a fairly simple version of fairness)
Some goals are competing. For example, fairness compete with utilization. Also, for system with hard deadline, worst-case time is sacrificed for average time.
Jobs | A | B | C | D |
Arrival time | 0 | 1 | 2 | 3 |
Run time | 5 | 2 | 9 | 4 |
Scheduler will do the following:
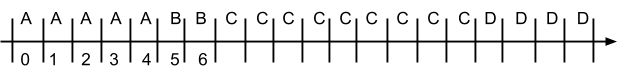 And here are the metrics, assuming context switch time is
And here are the metrics, assuming context switch time is 
Jobs | A | B | C | D |
Wait | 0 | 4 + | 5 + 2 | 13 + 3 |
Turnaround | 5 | 6 + | 14 + 2 | 17 + 3 |
Pros
Cons
Schedule:
A | A | A | A | A | B | B | D | D | D | D | C | C | C | C | C | C | C | C | C |
Utilization: 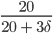 , same as first come first serve
, same as first come first serve
Schedule:
A B C D A B C D A C D A C D A C C C C C
Metrics:
Jobs | A | B | C | D |
Wait | 0 |
| 2 | 3 |
Turnaround | 5 | 6 + | 14 + 2 | 17 + 3 |
Pros:
Cons:
to 
Unix time system often have interactive users, therefore they tend to use First Come First Serve + Preemption, and it tends to be a better match for any interactive system.
What often happens is that you have different job classes
Once we have the job classes, we may want priority-based scheduling. The highest priority will be taken care of first. Within the same priority, you will have round robin.
Two kinds of priorities
In Linux, there is an external priority called “niceness”. Greater niceness -> willing to wait.
Traditionally niceness ranges from -19 to 19. E.g. nice (+3). (you can only pass in nonnegative numbers)
Priority = (niceness + _______ )
In essence, all schedulers are different priority based scheduler
Doc for nice: http://man7.org/linux/man-pages/man2/nice.2.html
Further readings for scheduling: Understanding the Linux Kernel By Daniel P. Bovet & Marco Cesati http://oreilly.com/catalog/linuxkernel/chapter/ch10.html