|
Seagate HDD |
Corsair SSD |
Capacity |
1 TB |
60 GB |
Cache |
16 MB |
|
RPM |
7200 |
|
Internal transfer rate |
1.29Gb/s |
|
External transfer rate |
3Gb/s |
3Gb/s |
Sustained Transfer rate |
0.93 Gb/s |
280MB(read)\ 280MB(write) |
|
||
Rotational Latency |
4.166ms |
|
Seek time(read) |
8.5ms |
|
Seek time(write) |
9.5ms |
|
Track-to-track time |
0.8ms |
|
Power (idle/typical) |
9.5W/12.5W |
2.0 W |
MTBF |
1 million hours |
1 million hours |
Annual failure rate |
0.73% |
|
Non-recoverable read errors |
1 per 10E15 bits read |
|
Shock Resistance |
1000G |
*:main latency source.
Assume, 1 CPU cycle time: 1ns; Programmed I/O takes 1000 CPU cycles : 1 ![]() ; Device latency: 50
; Device latency: 50 ![]() ; Computation time per buffer: 5
; Computation time per buffer: 5 ![]() .
.
Polling |
Straigth forward away |
|
Latency |
5ms + 40ms + 50ms + 5ms = 100ms |
for(;;){ |
request + device latency + read + compute |
||
Throughput |
10,000/s |
|
1 request / time on process |
||
Utilization |
5ms / 100ms = 5% |
|
Compute time / overall time |
||
|
||
Batching |
Read more data per reading |
|
Latency |
5ms + 40ms * 21 + 50ms + 5ms * 21 = 100ms |
int batchNum = 21 |
request + device latency + read + compute |
||
Throughput |
21/1000ms = 21,000/s |
|
21 requests / time on process |
||
Utilization |
105ms / 1000ms = 10.5% |
|
Compute time / overall time |
||
|
||
Interrupts |
Let CPU doing other task while waiting for device |
|
Latency |
5ms + 50ms + 5ms + 1ms + 40ms + 5ms = 106ms |
for(;;){ |
request + wait for interrupt + overhead of interrupt + check ready + read + compute |
||
Throughput |
1/56 ms = 17,857/s |
|
1 request / time on prcess |
||
Utilization |
5ms / 56 ms = 8.9% |
|
Compute time / time on process |
||
|
||
DMA |
Direct memory access, Controller send data to memory directly |
|
Latency |
50ms + 5ms + 1ms + 5ms = 61ms |
for(;;){ |
block + interrupt handler + check + compute |
||
Throughput |
1 / 11ms = 910,000/s |
|
1/ time on process |
||
Utilization |
5ms / 11ms = 45% |
|
Compute time / overall time |
||
|
||
DMA + Polling |
Let CPU doing some while waiting for DMA ready. |
|
Latency |
50ms + 1ms + 5ms = 56ms |
for(;;){ |
block + check + compute |
||
Throughput |
1 / 61ms = 167,000/s |
|
1/ time on process |
||
Utilization |
5ms / 6ms = 84% |
|
Compute time / overall time |
||
120 PB of data is stored on 200,000 hard drivers. Each disk contains 600GB data.
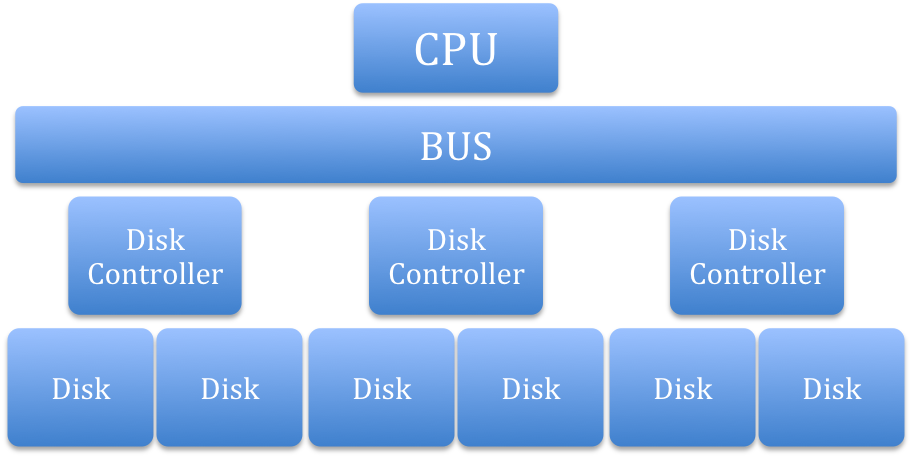
Each disk controller(DC) will be connected to the bus, and each DC will control certain disks.
This structure is too slow, so what we need is a specialized network to connect multiple CPUs, Disk Controllers, and Disks.
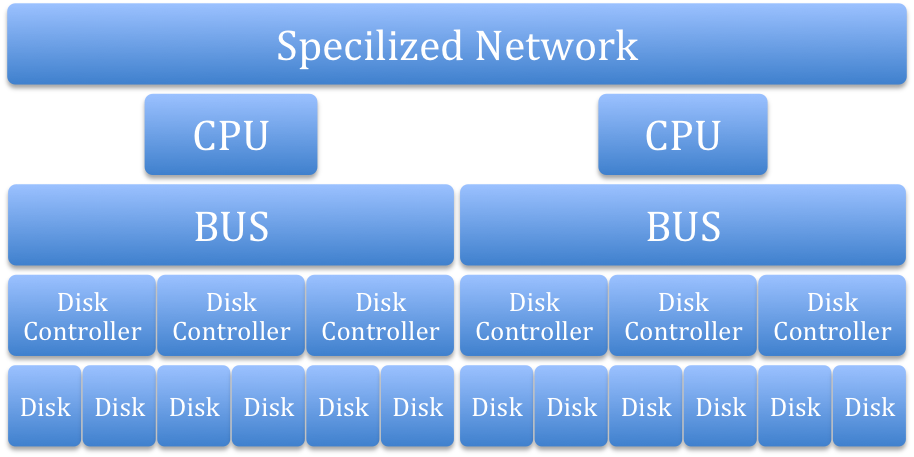
Disk 1 |
Disk 2 |
Disk 3 |
Disk 4 |
Disk 1 |
Disk 2 … |