Scribes: Oliver Huang, Jonathan Chu
Things we need from file systems:
Example file system:
Let's have a file system that is:
How can we make a file system for this?
Idea 1: Have disk controllers maintaining a certain number of drives e.g. 16 drives/dc
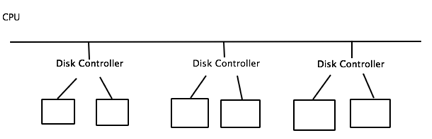
Problems: too slow
Idea 2 (better idea):
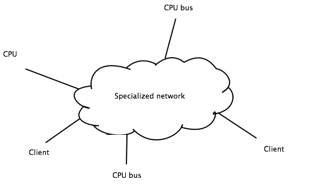
Parallelize the system. This approach works better for us, and is the approach used in the General Parallel File System.
GPFS is a good system to implement large file systems. The following are performance techniques used in such a system.
Involves splitting data so that one file is not stored entirely on one drive, instead the file data is broken up and stored in multiple drives. This allows the reading of a file to be done in parallel with a large number of drives, which speeds up the access time. Normally, the number of disks is a power of 2.
Distributed Metadata: Metadata includes information about a file, and not the actual contents of the file. This includes locations, ownership, timestamps etc., much like a catalog entry. The idea of distributed metadata is that there is no central catalog; it is not all stored in one place. Instead, the metadata itself is striped.
Efficient Directory Indexing- If a directory contains a large number of files, say over 1 million, there we need an efficient data structure to store all of these. We have multiple ideas for this:
Distributed Locking - the file system needs to be able to get locks on a file, even if the file is broken up (distributed). This problem is much harder
Partition Awareness - Say the file system is gets partitioned in two sections, this could happen, for example, in a network failure. A user in one section should be able to get files a separated partition. One solution to this problem would be to store copies of changes or reads made to the other partition; however, this introduces the problem of competing updates after the partitions are connected. The solution to this problem is majority rules, namely, the only the larger partition users can make changes, and the small side is read only.
File system stays live during maintenance - It is important that the file system is running as consistently as it can. One such time is during maintenance; we want users to be able to use the file system during this time.
GPFS is a big file system though. Let's think about how to build this from the bottom up. What hardware is important for file system components?
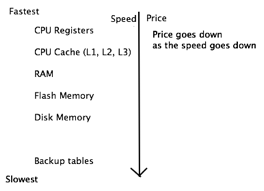
We want to keep these things in mind while building file systems. The file system itself is a data structure that lives on all levels of this hierarchy; it is sort of hybrid storage. We always want to measure the price/performance, so the question becomes, how can we measure performance?
There are three main metrics for file system performance:
Like all systems, there are always tradeoffs between metrics. The top two performance metrics, throughput and latency, are competing objectives; efforts to increase the throughput tend to the increase latency, and efforts to decrease the latency tend to decrease the throughput. Our objective then, is to find a sweet spot between throughput and latency.
When we want to access a file on a disk, these are the things that we must do:
To get a performance measure, we need to know how long this takes. Let's take a look at some example disk drives:
Seagate Barracuda ES2 1TB "near line"
Measuring the performance of Seagate Barracuda (external transfer rate, max internal and max sustained transfer rates, power) is much more straightforward than measuring reliability (MBTF, AFR, non reachable sector read failure rate) as the failure rates are so low that it is not economically feasible for manufacturers to wait for a failure to happen and record the time, thus the reliability numbers are often guesswork.
Corsair Force GT
The real (performance) advantage to SSD drives is that there is no seek time.
Let our example device have the following timings:
Recall the performance metrics for I/O
These are the numbers we want to define.
We want to check performance for the simplest case, where there is one read operation.
for (; ;){ send command to controller 5μs
char buf[40] device latency 50μs
read 40 bytes from device to buf read data 40μs
compute(buf) compute 5μs
} total latency: 100μs
To calculate the throughput, we divide 1 by the total latency of one iteration of the for loop, which gives us the number of requests per second.
| Throughput = | 1 requests |
| 100μs |
= 10,000 req/s
To calculate the utilization, we divide the amount of time the CPU is doing "real work" (ie. computing) by the amount of "busy work" (ie. reading, device latency...)
| Utilization = | 5μs |
| 100μs |
= 5%
Batching minimizes overhead by using bigger blocks of data, and attacks device latency.
Through batching, we read n sectors at a time, where n can be any number such as 1, 8, 16, 1024 or higher. Reading a large amount of sectors at a time can lead to great performance, however there is a tradeoff with internal fragmentation and external latency. A potential fix to this probelm is to read varying size blocks depending on the operation. This, however, can lead to higher complexity. Most of the times, we read in batches of 8 or 16 sectors.
Latency = send command + device latency + read + compute
Latency = 1000μs = 5μs + 50μs + 840μs + 105μs
| Throughput = | 21 requests |
| 1ms |
= 21,000 req/s
| Utilization = | 105μs |
| 1000μs |
= 10.5%
Multitasking lets someone else run while we are waiting.
By allowing other threads to run while the current thread is waiting, multitasking allows us to minimize the amount of time the CPU sits around idly waiting, thus reducing the total latency when calculting throughput, and subsequently raising utilization.
for (; ;) {
send command to controller send 5 μs
do{ block until interrupt block 50 μs (do not consider in calculations)
handle interrupt handle 5 μs
} while (!ready) check 1 μs
read buffer (40 bytes) read 40 μs
compute compute 5 μs
} total latency: 106 μs
| Throughput = | 1 request |
| 56μs |
= 17,857 req/s
| Utilization = | 5 μs |
| 36μs |
= 8.9%
Direct memory access (DMA) improves performance (tells device controller where to put data)
DMA is a method that tackles the PIO bottleneck by allowing the file system to access memory directly, which we have seen takes up a majority of the latency of the above methods.
While attacking the expensive overhead from the PIO bottleneck, DMA introduces an overhead with associated with the interrupt handler. Therefore if you have many I/Os, then the overhead from the interrupts can stack up and become the bottleneck.
Latency = block (do not consider in thruput calc.) + handle + check + compute
Latency = 61 μs = 50μs + 5μs + 1μs + 5μs
| Throughput = | 1 request |
| 11μs |
= 91,000 req/s
| Utilization = | 5μs |
| 11μs |
= 45%
In order to tackle the issue of the interrupt handler overhead in DMA, we now introduce a new method that combines DMA and polling. In DMA + Polling, we do not use interrupts. Instead, after issuing our commands to the disk controller and the computations, we start polling to see if the disk controller is done and ready. If the polling and the disk controller's times are well timed, then we can further increase throughput and utilization by throwing out the interrupt overhead while only introducing a tivial busywait that comes with polling.
for (; ;){
while(DMA slots busy)
yield()
}
With the above DMA + Polling approach, we get the following latency, throughput, and utilization:
Latency = yield + check DMA + compute
Latency = 56μs = 50 μs + <1 μs + 5μs
| Throughput = | 1 request |
| 6μs |
= 166,667 req/s
| Utilization = | 5μs |
| 6μs |
= 84%
Method |
Latency (μs) |
Throughput (Kb/s) |
Utilization (%) |
Polling |
100 |
10 |
5 |
Batching |
1000 |
21 |
10.5 |
Interrupts |
106 |
18 |
8.9 |
DMA |
61 |
91 |
45 |
DMA + polling |
56 |
167 |
84 |
It seems like DMA w/ polling is the best performance measure by far. However, it may not always be the best choice. The reason it was so good in this example is that this problem was very well synchronized and a very regular workflow. For a general-purpose operating system, such as Linux, there is no guarantee of this regularity, so this will not work as well. Though, for some embedded systems with more regularity, it might still be the best choice.