A file system is a data structure that represents files (on disk and in RAM) that provides an abstraction representing a collection of files.
If a file system for only one file was to be made, it would be easy to implement. However, a file system for a large collection of files is desired. Essentially, this means a good data structure is needed.
The explanation of file systems will covered over four lectures, each describing an important aspect:
As an undergraduate student, Dr. Eggert did research under a quite peculiar and baffling professor. Basically, this professor was crazy.
Now Dr. Eggert did not know about UNIX at all during this period of his life. So when he was assigned to create the file system, he created what he thought was the best implementation in his undergraduate mind: a simple implementation.
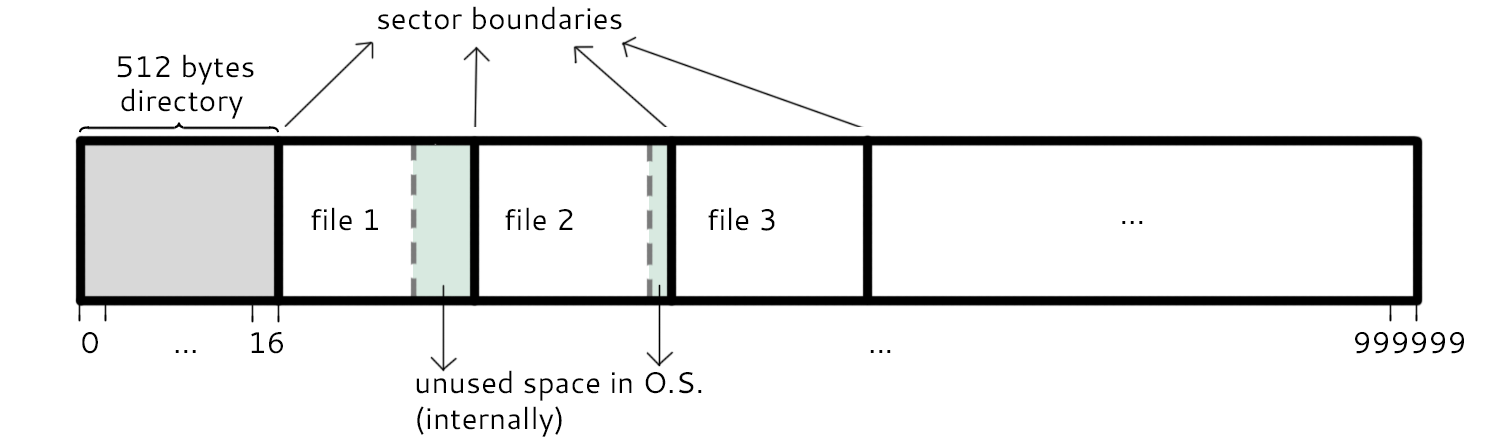
This is a map of the disk using Dr. Eggert's Dumb File System. Each sector takes up 512 bytes. The first sector, split into 16 sections, is reserved as the directory for the files that will occupy the remaining sectors. We start by placing the beginning of each file on a sector boundary. The excess space not within the size allocation is marked as unused space by the OS (marked in green).
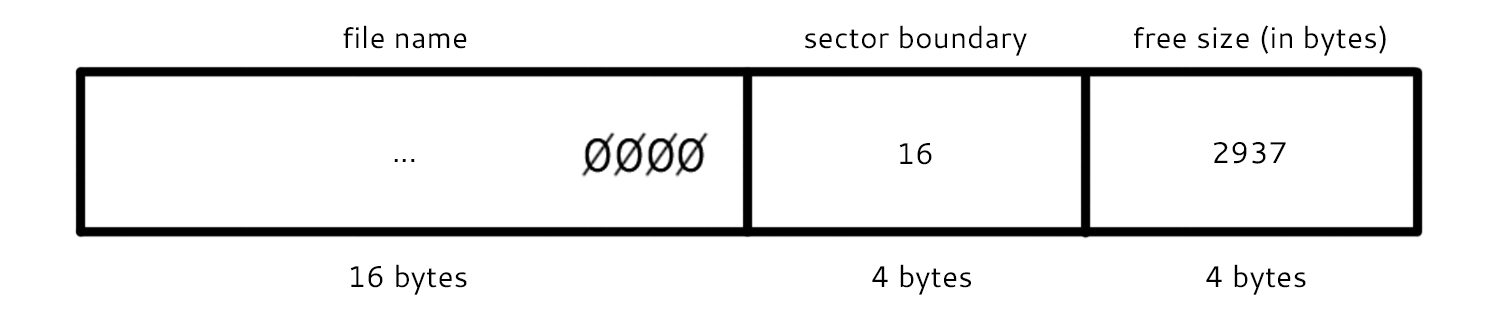
Each entry in the directory consists of 32 bytes. The first 16 bytes store the file name. The next 4 store the address of the sector boundary where the file begins (the first sector of the file). The next 4 bytes store the actual size of the file (in bytes). And the rest of the space stores other information, like the number of sectors allocated to the file.
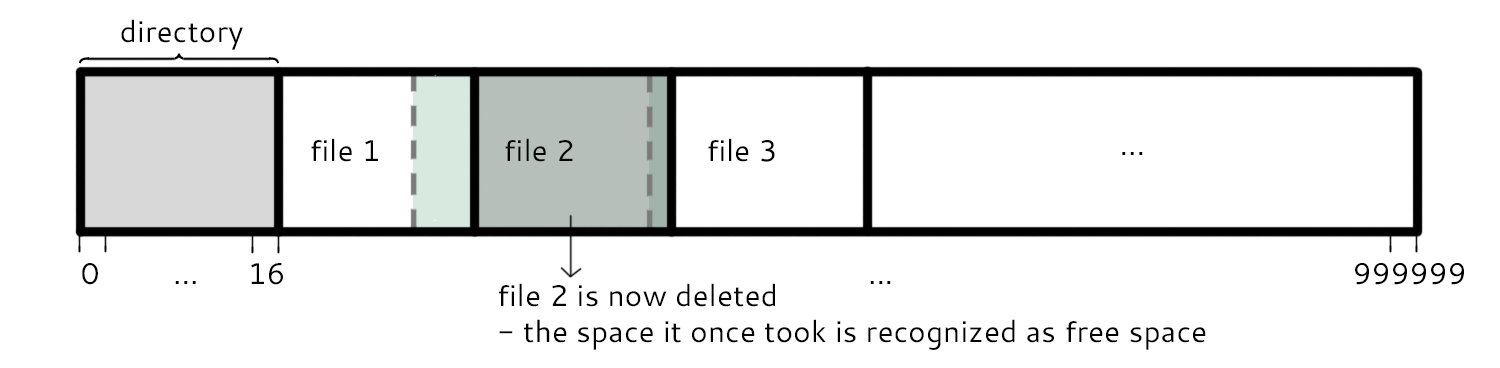
When deleting a file (e.g. file 2), the sectors that it was formerly in need to be marked as free space.
Believe it or not, there are several file systems created in likeness of Dr. Eggert's Dumb File System. One of these is the RT-11, a real-time operating system. In certain cases, such file systems are desired because they have consistency and predictability in their timings. Think back to hard real time scheduling (safe and slow). In this case, people are willing to deal with the problems of these kinds of file systems.
A solution to fix/avoid/lessen the problems (primarily fragmentation) of the contiguous file system was wanted. Enter FAT.
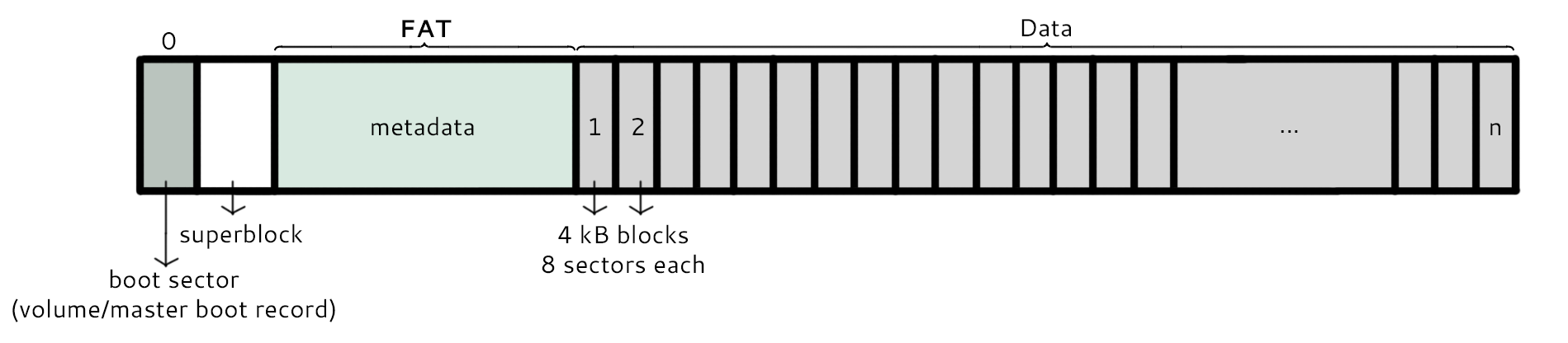
This is the new layout of the disk with the FAT structure instead. The block with address 0 is reserved for the boot sector. The block with address 1 is reserved for the superblock, which contains information about the file system including the version number, the size of the file system, the block size, and the location (block number) of the root directory. The metadata section contains the FAT. Its structure is illustrated below.

The FAT is essentially an array containing block numbers. There are three types of values stored in here, namely:
The size of each section of the array is related to the number of blocks in data. Because each section is 16 bits, the largest size representing the number of sectors can be represented by 2^16 B. And the size of each sector is 4 KiB, or 2^16 B. Thus, the file system can be at most 2^12 * 2^16 = 2^28 B = 256 MB.
In RAM, a pointer field (next) could be created to move from one block to another. Why not do this in disk? Why make an array of block numbers?
So FAT says make a linked list:
A question that still remains is: How can filenames and other information be stored?
For FAT, there exists an extra data structure that contains theses things:
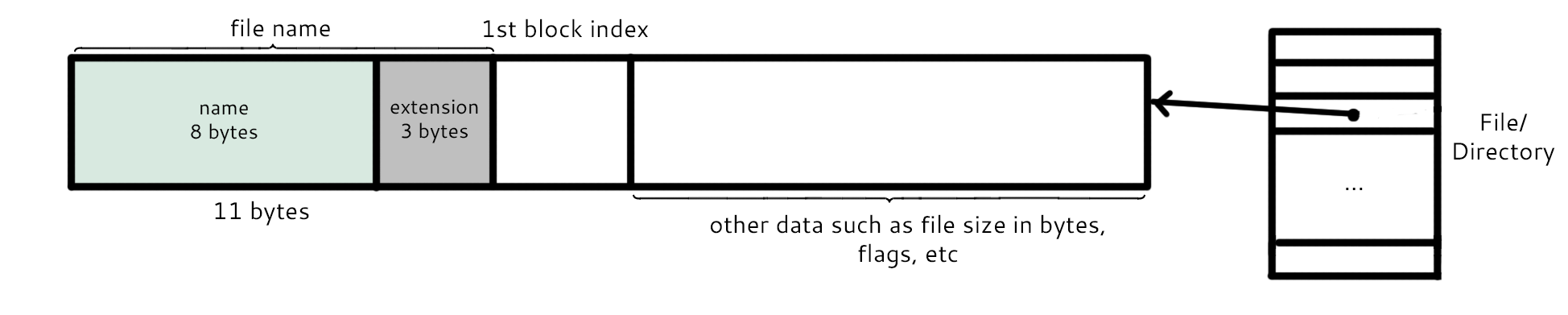
The FAT directory entry begins with the file name, which consists of 11 bytes. The first 8 bytes are the actual name of the file and the last 3 bytes are the extension of the file (txt, doc, and others). The period seen in files on the computer like "foo.txt" is not stored. The next section contains the number of the first block index for that entry. Then afterwards comes other information like file size in bytes and option flags.
Regarding FAT directory entries, directories would be considered files as well. The only difference is a filetype flag that helps to determine which of the files are actually directories.
But how can the top level directory be found in this case?
To solve this problem, the root directory number is located in the superblock.
Though FAT solved several problems in terms of file systems, it contains difficulties of its own. This can be seen when comparing some seemingly simple commands.
EXAMPLE 1: mv xyz def
For FAT, this is easy to implement. The file is essentially just being renamed within its FAT data entry.
EXAMPLE 2: mv d/xyz e/xyz
At a first glance, this seems quite similar to the first example. In the user's perspective, this should act and be as easy to implement as the first example. However, this is not the case for FAT; this command is harder and causes more trouble. A graphical description of the steps needed to take is shown below:
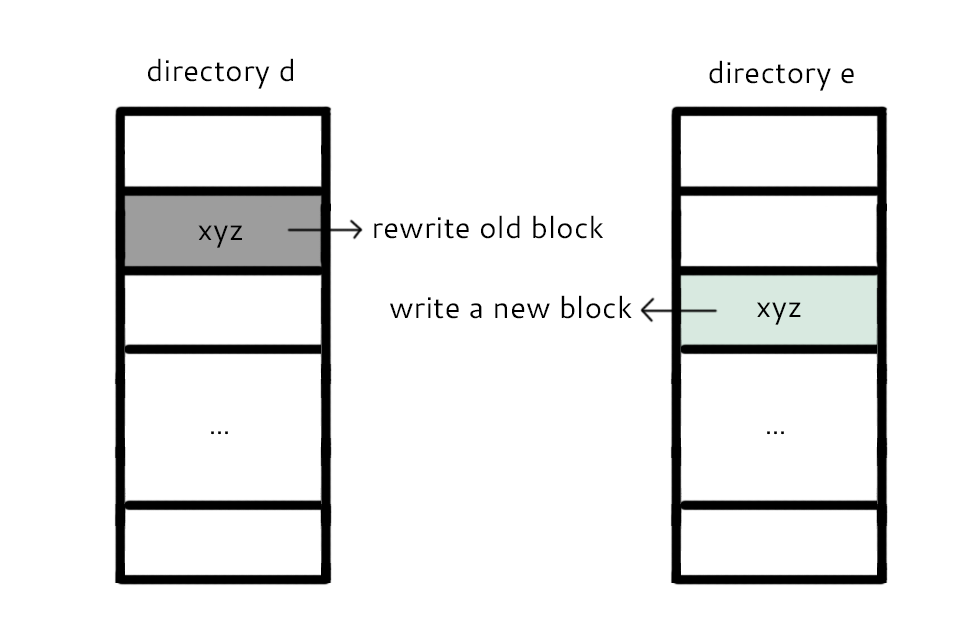
As shown above, the process of moving between directories is much more complicated than renaming within the same directory. There are two steps the file system must take in order for this to happen:
A. Write to the new block (allocate xyz in e).
B. Rewrite the old block (replace block with zeros in d).
However, which of these two tasks are to be done first? Consider the case in which the computer crashes in the middle of this procedure:
Regardless of which action is done first, things can get problematic. So how did the original FAT respond to this situation? It errors out of it (quite the unsatisfactory solution).
How was this problem resolved? Was there another technique to fix it? Look no further than below.
Unix v7 File System (1977)
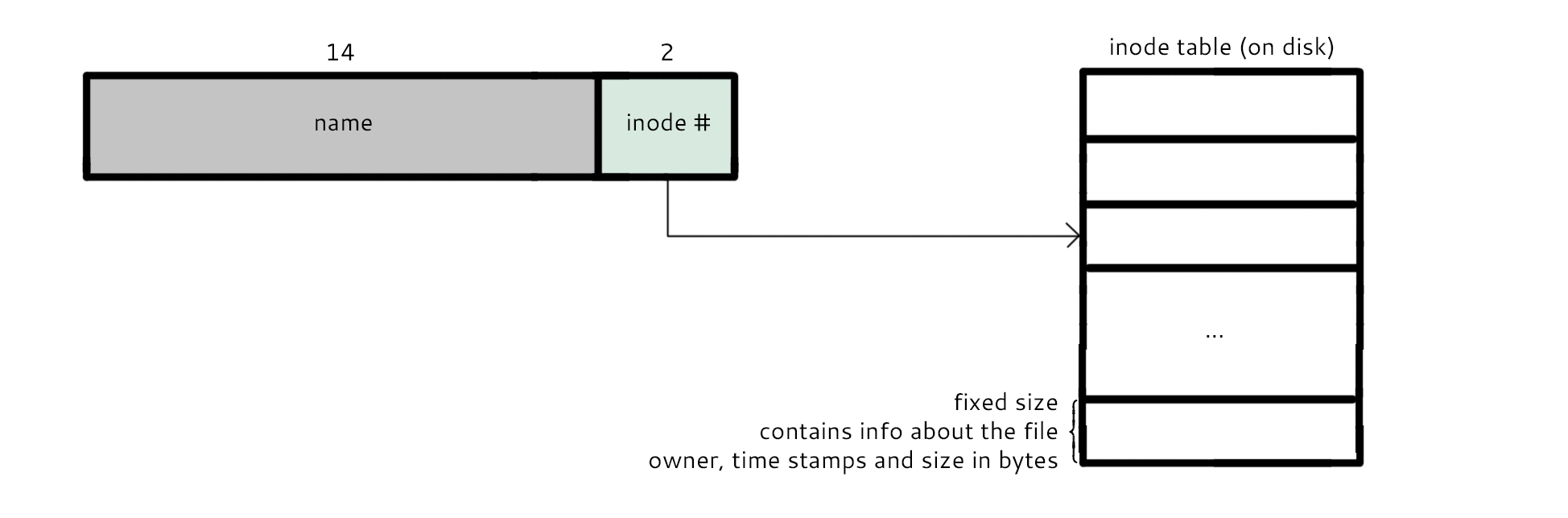
On disk, there is an inode table that contains a fixed size amount of information about each file. Mainly, it contains the file name, which is 14 bytes, and an inode number, which is 2 bytes. Additionally, it contains information about the owner, time stamps, and size of file in bytes.
In the oldest version, renaming from one directory to another was still not allowed. But consider the following commands:
link("d/xyz", "e/xyz");
unlink("d/xyz");
The first command, link(), creates a hard link e/xyz. In result, there are two different directory entries that both specify the same inode. The second line, unlink(), then removes the hardlink d/xyz so that only one link remains to the file. This is essentially the same as the mv command.
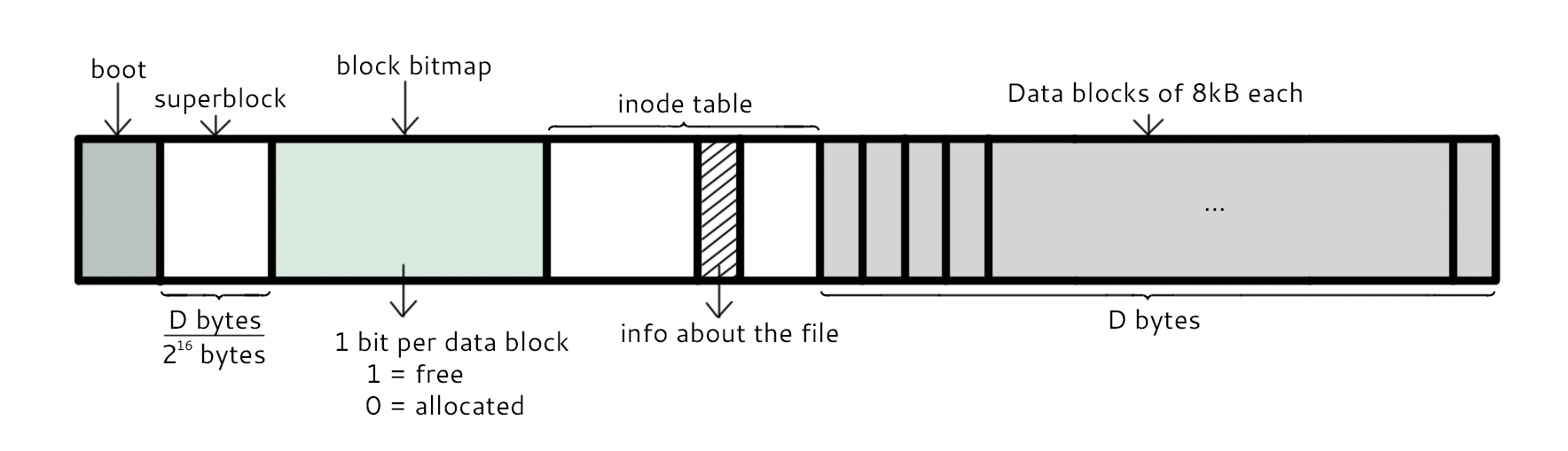
The first and second sector are reserved for the boot and superblock, respectively. The next section is known as the block bitmap, which contains 1 bit per data block (D/2^16 bytes given D bytes size of data section). Each bit is a 1 if the respective data block is free and 0 if allocated. Afterwards is the inode table, which is shown above. It contains info about the files. And the rest of the space is reserved for data blocks, which are 8 KiB = 2^13 B each.
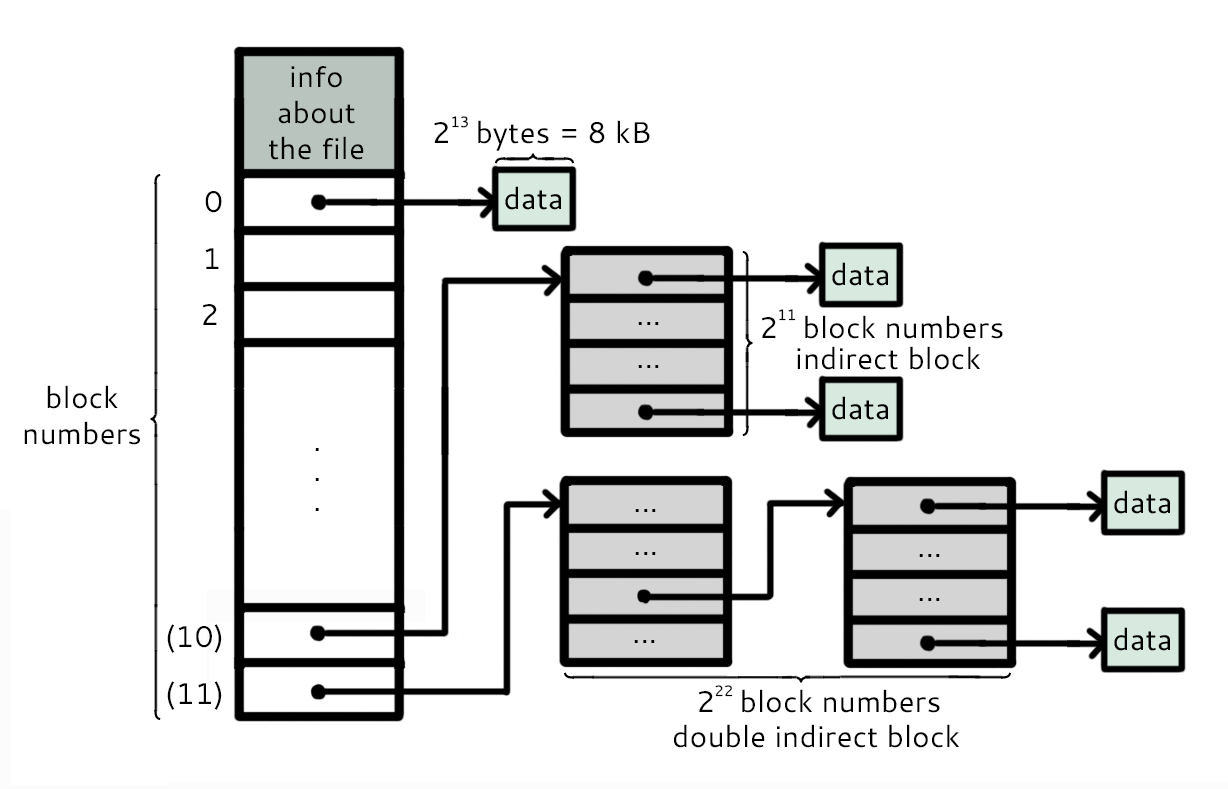
As it can be seen in the diagram, each section in the inode table contains much information. It first contains the information about the files, described above. Then it has 10 sections that store the inode numbers of the allocated blocks (0 - 9). If more than 10 blocks are allocated to the file, then an indirect block that contains sections that store inode numbers is created, which in this case can store up to 2^11 inode numbers. If that still is not enough sections to store the whole file, a double indirect block which contains sections that point to indirect blocks is created. In this case, a total of 2^11 * 2^11 = 2^22 inode numbers can be stored in the double indirect block. Altogether, the number of inodes that can be stored is 10 + 2^11 + 2^22, which was definitely sufficient for the total size of file systems during that time.
This file system has many similarities to FAT, especially how the inode table essentially replaces the FAT. However, one noticable thing is that to access the block information, the only block bitmap in comparison to a large FAT. Thus, there is less overhead.
Q: With link, how can you tell when you can reclaim storage?
A: Using a link count.
If st.st_nlink == 0, storage can be reclaimed.
Thus, the following conclusion can be made. Storage for a file can be reclaimed when:
1. Link Count == 0
2. The Last File Descriptor is Closed
The RAM keeps track of which files are open and records them.
The function namei() takes a filename and returns the inode number. So how does it work?
The function begins by going through some recursion or loop.
To change the process working directory, use the following command:
In Linux, the command to change directories is cd and is used as such: $ cd foo
The first C compiled version of cd is shown below:
However, there was a bug in this original program. This cd would change directories, but only for the child process spawned in the cd.c program. The parent process was left unchanged and thus, the user did not see a directory change.
If the file name is "/a/b/c/d" the / at the beginning of the name means that this location starts at the root directory.
To change the "root", use the following command:
How is this useful? Consider the case where a user is provided a certain "root", which restricts his or her access, shown in the diagram below:
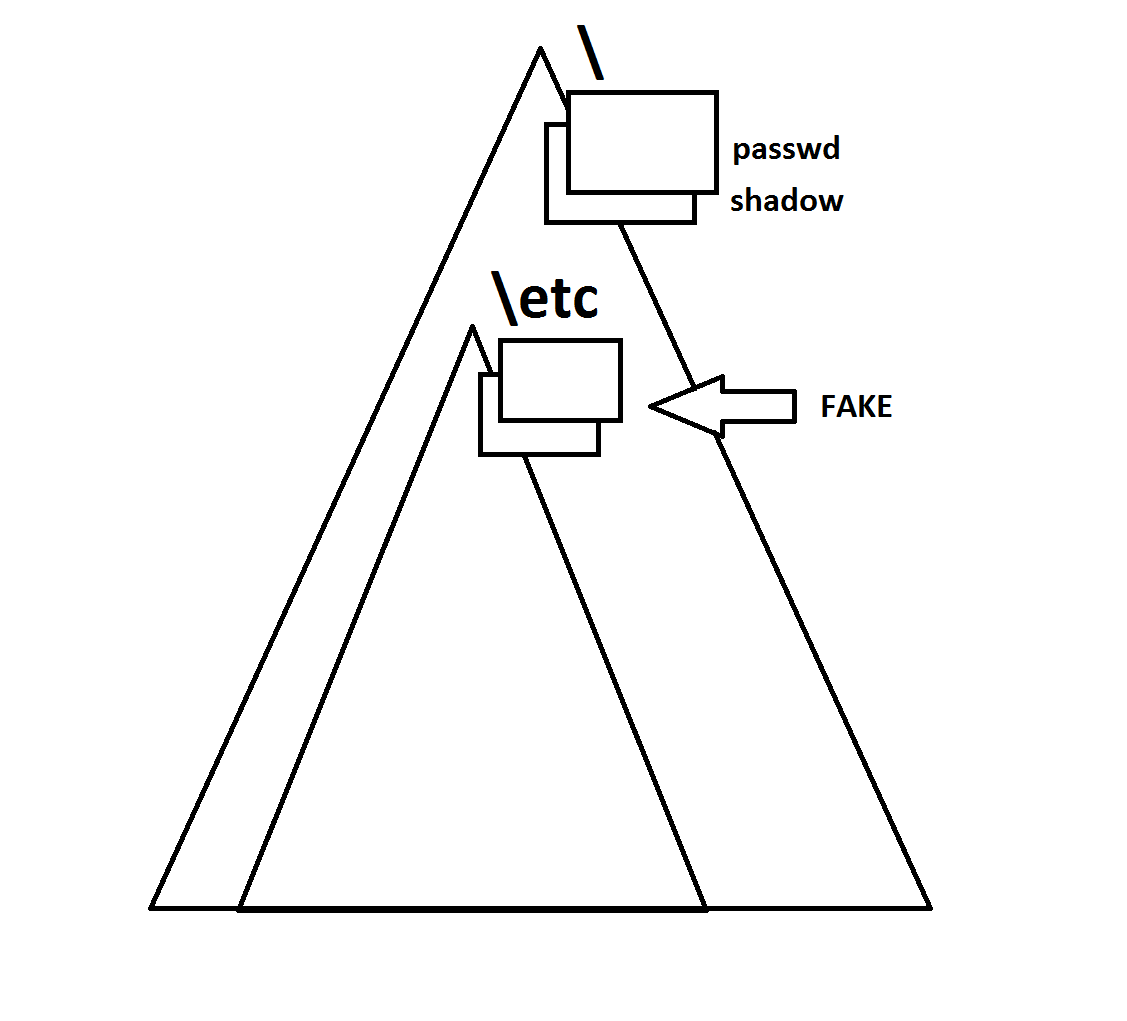
The smaller triangle represents what the user can access, which makes for a "protected" area outside of the smaller triangle and within the larger one. Thus, the root user can essentially prevent certain areas from being accessed by other users.
However, this command requires root access and is considered a "priviledged" command within the priviledged commands. Why? Consider the case from the diagram above where the smaller triangle is not present. There are two files in "/etc", known as passwd and shadow which contain the password information and can only be accessed by root. If another user was able to use chroot() and change the root directory, a "fake" passwd and shadow could be made within the smaller triangle's /etc that can be accessed by such user. The user can then use the passwords self-created to become a superuser which is VERY BAD.
Consider the following diagram:
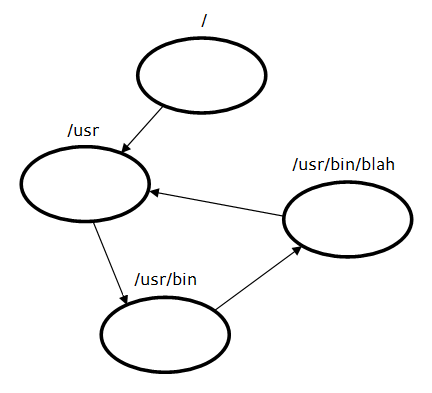
Can a circular link dependency like this one be allowed? It seems like it would cause some trouble. How can we check for this situation?