. and ..?Let's open up a shell and type the following command:
$ ls -alWe know that ls lists the contents of the current directory and that the a and l options show the hidden files and file details, respectively. The output of the above command will be a list of the files in the current directory, even the hidden ones. Two of the hidden files in the list are of special interest: . and ...
. is a self pointer to the working directory.
.. points to the parent directory.
How do we implement these pointers in the file system?
. and .. in every directory. + Same code for both pointersEasy Way. and .. from disk. + Saves disk spaceConsider this command:
$ ln / /usr/bin/oopsYou can see that we're trying to hard link to a directory, but this isn't allowed. Why not?
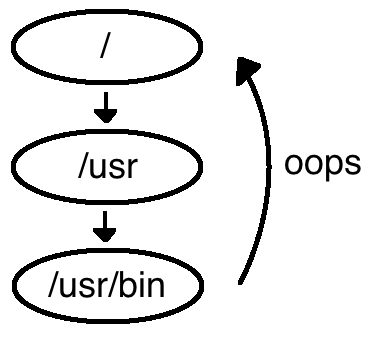
Linking directories would create cycles. Consider a program like find that uses Depth First Search (recursion). The find program in its current implementation would infinitely loop if it encountered a hard link to a directory. Let's take a look at some possible solutions.
find so that it detects loops and skips them. O(n*logn)
. and .. are simply not allowed.
Consider a git project with the following structure:
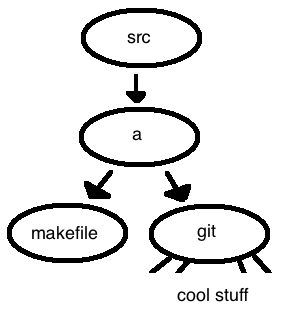
Let's trying running some commands:
$ cd src
$ git clone a b
Now our file system looks like this:
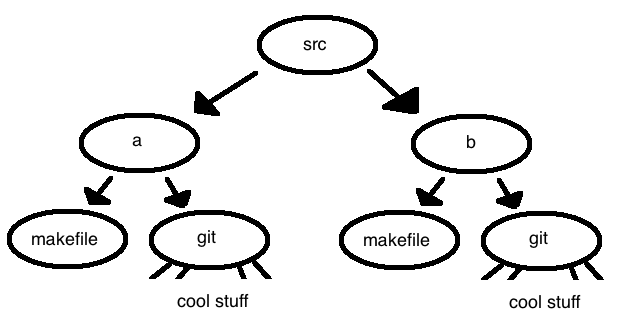
We've just copied the contents of a into a new directory called b. We were shocked to see that the clone operation took only 1.3 seconds to complete despite running on Professor Eggert's creaky old desktop machine that has a 5,400rpm hard disk drive. The project we've just cloned was the source code of Emacs, an open-source project with a 30-year history. How did we copy so much data that quickly?
This fast clone was possible because of hard links. The majority of the project (let's say a few hundred megabytes) are just history - historical files we won't ever need to change. Because these files are read-only, there is no harm in simply creating a hard link to their location. We really only needed to create brand new copies of the files we'll be modifying for our next commit.
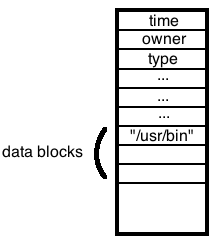
In the Berkeley Fast File System, inodes are stored separately from the data to which they correspond. An inode contains information about a file, including its type (file, directory, or link), owner, timestamps, and data blocks.
For symbolic links, the data block points to the contents of the symlink. For example, if the link is pointing at /usr/bin, the data block of the inode simply contains the string "/usr/bin".
Consider the namei command, which takes a file path and follows it until a terminal point is reached. It outputs the type and name of each level (a line of output, for example, would be d usr where "d" means "directory" and "usr" is the name of the directory being passed through). This program can be used for resolving confusion around the structure of symbloc links. When it sees a symlink, it substitutes its contents for teh name. We can see some potential problems with this: what if a link points to itself, or what if the file doesn't exist?
If the file doesn't exist, the program can simply fail. In a loop, the program will try to resolve the symbolic link 20 times before giving up: it sets errno to ELOOP. Since 20 is an arbitrary limit, a loop is not guaranteed, but there is a still a good chance that the loop exists.
How do we waste less space with symlinks? Short symlinks are stored in the inode itself. Data blocks are used to store large symlinks. The file system also uses two block sizes where short blocks are 1/4 the size of full blocks.
We can use the functions stat() and lstat() to access information about a file. These two functions are identical except when handling symbolic links: when stat() is given a symlink, it follows the link and fills in the information about the linked file. When lstat() is called on a symlink, the functions returns information about the link itself.
For a symlink "b", unlink("b") does not follow the link but deletes it, leaving the destination file intact.
rename("b", "c") also does not follow the symbolic link.
| Type | Symbol |
| Directory | d |
| Regular file | - |
| Symbolic link | l |
| File | p |
| Character special | c |
| Block special | b |
| Contiguous file | C |
From top to bottom:
Software File systems and mountA file system must be mounted before its contents can be accessed by the system. For an everyday use case, consider what happens when you plug a USB drive into your computer. The kernel will mount the drive's file system so you can view and edit its contents, and then unmount it when you're done working. The kernel maintains a table of mounted file systems. An example mount table is as follows:
| Pointers | Dev, Inode Numbers |
| FS2 | 1,350 |
| FS3 | 1,57 |
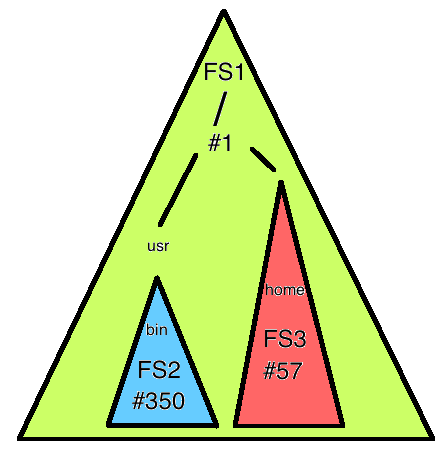
To mount a disk, use the mount command:
$ mount /dev/dsk/03 /usr/binThis invokes a system call to mount /dev/dsk/03 to /usr/bin. To prevent cycles, avoid duplicates in the mount table. Symlinks can work across file systems. The mount command requires root access because mounting a file system that already contains files will hide the existing files until the system is unmounted in the future. This poses many security risks.
shred and Erasing DisksThe shred command is useful for securely erasing files. It overwrites the data in a file with random numbers 3-7 times to prevent any party with physical access to the drive from seeing what was there. Because magnetic hard disks can leave traces of files on the platters, overwriting data multiple times helps to ensure that the data is in no way recoverable.
shred often has to write a lot of data, especially if it's overwriting large files. Let's look at a faster way to delete a file called "little-black-book".
$ rm little-black-bookThis command is practically instant. The file won't show up when we ls inside the directory, so it's gone forever, right? Wrong! All we've done is erase the pointer to the file - the data is still physically present on the disk, and if somebody wanted to, they could recover it with little trouble. We've already discussed the security advantages of a command like this:
$ shred little-black-bookShould we just use shred every time? Which file deletion command you pick depends on your security needs and time contraints.
What if we're using a file system that uses redundant data? It's possible that the file we've just shreded is still present on disk, but possibly hidden by the operating system. We could shred the entire file system, but this could take a very long time. At this point the safest, most sure-fire why to remove the file from existence is to physically melt the drive. Indeed, some agencies possess furnaces for this exact purpose. In fact, a common process for permanetly deleting data is soft shred (using the shred command) -> hard shred (physically shredding the disk) -> demagnetizing (using magnets to erase the pieces of the disk) -> melting the pieces.
There are multiple types of file systems - EXT4, VFAT, and FFS are just a few examples - and we may want to mount them together in one place. We do this by abstracting the file systems using a VFS (Virtual File Systems) layer.
The VFS is implemented in the style of many object-oriented programs. For example, struct inode_operations contains pointers to functions such as link, unlink, and open. struct inode_operations contains pointers to read and write.
![]()
![]()