Virtual Memory (cont'd) and Processes; Caching Policies
Date: 11/26/14 Scribe: Zhaoyuan (Zoe) Xi
Wrap-up of Virtual Memory (VM) Usages:
Review of Virtual Memory Usages
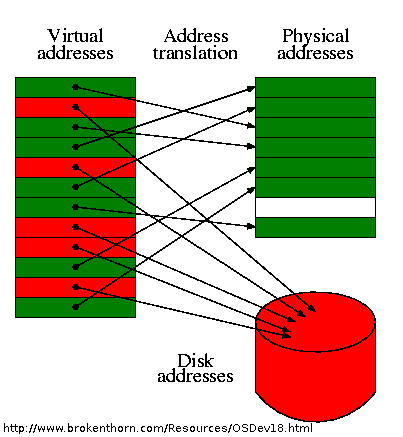
In the previous lecture, we discussed the concept of virtual memory,
which is an abstraction of main memory that maps memory addresses used
by programs, referred to as virtual addresses, into actual physical
addresses in computer memory. Three important usages of virtual memory
include:
Caching - VM provides a way to extend main memory using disk. It
uses main memory efficiently by treating it as a cache for an address
space stored in disk, keeping only the necessary data in main memory,
while transferring data back and forth between disk and memory in
units of pages. This allows the computer to reference more memory than
is physically available.
Protection - VM provides memory isolation and page-level memory
protection. VM gives each process its own virtual address space, thus
protecting each process from corruption by other processes. VM can
also provide page-level protection by adding additional permission
bits to page table entries.
Memory Management - VM simplifies memory allocation. When a user
process requests additional heap space, the OS first allocates the
appropriate number of contiguous virtual memory pages before the VM
maps them to arbitrary physical pages in physical memory. This saves
the OS the trouble of locating contiguous pages of physical memory.
Instead, the pages can be scattered randomly in physical memory.
Virtual Memory as a Tool for Memory Management
Unix initializes chunks of contiguous virtual memory by associating
them with chunks of files on disk in a process known as memory mapping;
that is, we map areas of VM --> areas of disk. This notion of mapping
contiguous virtual pages to arbitrary locations in arbitrary files
provides an efficient way to share data, create new processes, and load
programs. Programs can maintain and modify their virtual address space
using the mmap system call or, more commonly, via a dynamic memory
allocator such as the malloc package.
The mmap System Call
Unix provides a system call known as mmap that gives a process limited control over its virtual memory by allowing them to manually create and delete chunks of virtual address space. mmap asks the kernel to create a new area of virtual memory and maps a chunk of the file to that area of virtual memory.
Dynamic Memory Allocation
A more common way to manage a program’s virtual address is via a
dynamic allocator such as malloc, which maintains an area of memory in the virtual address space known as the heap. The heap contains dynamically allocated variables, and whenever a program requires
additional memory at run-time, a dynamic memory allocator is used to
explicitly allocate a block or contiguous chunk of virtual memory that
was originally free. Dynamic memory allocators come in two flavors: explicit and implicit. Both require the application program to allocate blocks; they differ in how the allocated blocks are freed.
Explicit allocators (C/C++):
- Requires the program to explicitly free any allocated blocks
- In C, the standard library provides an explicit allocator known as the
malloc package: we call malloc to allocate a block, and free to free a
block
- In C++, the new and delete functions are analogous
Implicit allocators (Java, Lisp, etc.):
- Requires the allocator to free an allocated block when it is no longer
needed by the program
- Implicit allocators, also known as garbage collectors, automatically
free unused allocated blocks
VM and Apache: an extended example
Large programs such as Apache often want to run other programs or need to respond to multiple requests that are independent of each other, i.e. the second request should not have to wait for the first to finish. In the example below, the running “instance” of Apache may call fork and malloc several times throughout its lifetime. When we call the fork function, it creates a new process with its own independent virtual address space. The child’s virtual memory is initially an exact copy of the parent process’s virtual memory, but because Apache calls malloc many times, quite a bit of virtual memory is allocated… and then we call execlp which loads python into the current process space. The problem with this is that fork is expensive because it has to copy the entire process state.
// An “instance” of Apache...
for (;;)
{
r = get_a_request();
if (fork() == 0) // if succeeds, child process executes next line
process(r); // => calls execlp(“python”, ...);
}
Alternate Method #1
An alternative is to use vfork(), which is like fork except that the parent process is temporarily suspended and the child process borrows the parent’s address space until the child exits, or calls execlp, at which point the parent process continues. But this method also has a problem. Because the child process has access to the parent process’s memory, there is no memory isolation/protection and the child process of vfork must be careful to not stomp over and accidently modify the memory of the parent process.
A side note: In the case we have an Apache + Python combination program, the code for both reside in the same memory area, so we don’t have to fork and call exec, we can alternatively use pthreads if we want the processes to run in parallel.
Alternate Method #2
Another alternative would be to use an optimization strategy known as copy-on-write. Here instead of copying the entire parent’s virtual memory, just the page tables are copied and the page table entries corresponding to that area of memory are flagged as read-only. Instead of immediately creating separate copies of the parent process’s virtual space, both share a single copy of the information in physical memory (they can all be given pointers to the same resource). Then on the first occasion where a process needs to modify the data, the child process creates a new copy of the page in physical memory, the page table entry is updated to point to the new copy, and write permissions are restored onto the page. Copy-on-write makes it possible to save precious memory resources in the case where separate processes all use the same resource.
A side note: vfork is a win over copy-on-write in the case where execlp("echo",...) is a really small program relative to the virtual memory, as we don't have to copy over a huge chunk of virtual memory.
Virtual Memory Caching Policies:
Alright, now that we’ve wrapped up our introduction about virtual memory and its uses in dynamic allocation, we backtrack for a bit and expand upon our discussion of virtual memory with respect to caching. As mentioned earlier, virtual memory provides a mechanism to extend main memory (RAM) accessible to a program by using disk. It does this by having RAM serve as an address space cache for a much larger disk in which the memory of the program actually resides in. When a program references a memory that is not currently cached, a page fault occurs and control is transferred to the kernel so that it can find a victim page in RAM to swap out to disk.
How to Choose a Victim Page (to access another region of memory):
The motivation: The cache contains only a small portion of the address space and our program wants access to another region of memory. So we need to find a page to swap out to disk. But which page do we choose? We want to make sure we choose a good page replacement policy because page faults/accesses to disk are expensive!
Page Replacement Policies:
1. Always swap out physical page 0.
Not a good idea. It’s essentially like saying we have room for only 1 page in the cache.
2. Modulo increment (n++ % P) where n is the index of our last physical page we replaced and P is the total number of pages
This will work if the whole program fits in physical memory and if we know that the program accesses virtual memory sequentially.
3. Random Access
If we can get random access to any virtual page, then any page will be accessed next with equal probability and the performance of any policy is about the same so it doesn’t matter which policy we adopt. In reality, random access to virtual memory is rare due to locality of reference, i.e. programs tend to reuse memory that was previously accessed. So in the following examples, we will assume non-random access to virtual pages and locality of reference.
4. First In First Out (FIFO) Policy
The victim page is the page that has been sitting in cache the longest. The assumption is that pages get used for a short period of time, and then the program loses interest in them so we can swap them out.
The following is a simulation of FIFO with 5 virtual pages [0-4], 3 physical pages [A-C], and a reference string of: 0 1 2 3 0 1 4 0 1 2 3 4. The reference string is the order in which the program requests the virtual pages and we make a total of 12 access requests starting at t0 with a request for virtual page 0. The requests that result in page faults are underlined.
0
1
2
3
0
1
4
0
1
2
3
4
A
0
0
0
3
3
3
4
4
4
4
4
4
B
-
1
1
1
0
0
0
0
0
2
2
2
C
-
-
2
2
2
1
1
1
1
1
3
3
Total page faults: 9
Can we do better than that though? Out of twelve requests, nine page faults occurred, which is not an insignificantly small ratio. Now let's try to run the same FIFO simulation with more memory (one more +1 physical page). The following is shown below:
0
1
2
3
0
1
4
0
1
2
3
4
A
0
0
0
0
0
0
4
4
4
4
3
3
B
-
1
1
1
1
1
1
0
0
0
0
4
C
-
-
2
2
2
2
2
2
1
1
1
1
D
-
-
-
3
3
3
3
3
3
2
2
2
Total page faults: 10
Interestingly enough, increasing the number of physical pages (RAM) does not necessarily decrease the number of page faults. In fact, in some cases like in our example, increasing the number of physical pages actually leads to an increase in page faults. This is known as Belady’s anomaly. While in practice it does not occur often, it is possible with the FIFO policy.
5. Furthest in the Future (The Oracle)
In this policy, we pretend that there is an oracle that can see into the future and predict which page is not going to be needed for the longest period of time. Choose that as the victim page to swap out.
0
1
2
3
0
1
4
0
1
2
3
4
A
0
0
0
0
0
0
0
0
0
2
2
2
B
-
1
1
1
1
1
1
1
1
1
3
3
C
-
-
2
3
3
3
4
4
4
4
4
4
Total page faults: 7
In our simulation, when the program requests page 3, it sees that it is not in RAM and looking into the future, the program is able to see that 0 and 1 will be immediately used, while 2 won't be requested until much later. So we load page 3 into physical page C. As one can see, this policy has a reduction in the number of page faults. In fact, the Oracle policy is the most optimal policy in this list. Howevever, in practice, it's difficult for the kernel (even if the compiler has access to instructions and compile-time variables) to predict ahead of time which page is going to be requested, so this policy is not frequently seen.
6. Least Recently Used (LRU) - An approximation to the Oracle
In LRU, the victim page is the page that was least recently used. The idea behind this is that the future may resemble the past, so the page that was just recently used will probably not be requested right away again. Using the same conditions as before, we run an LRU simulation:
0
1
2
3
0
1
4
0
1
2
3
4
A
0
0
0
3
3
3
4
4
4
2
2
2
B
-
1
1
1
0
0
0
0
0
0
3
3
C
-
-
2
2
2
1
1
1
1
1
1
4
Total page faults: 10
Ten page faults is a lot. Furthermore, note that in order for the OS to know which page was least recently used, we have to store that information in additional memory. This is a drawback of the LRU policy as resources are precious. However, despite this drawback and the large number of page faults in this simulation, the LRU policy is normally better than FIFO. This is because LRU is like an approximation of The Oracle Policy -- registers and compilers can work together to look at compile-time code and sort of "predict" the future. Turns out, we just used a special/bad example for LRU...
More Virtual Memory Optimizations:
Demand Paging
Recall that transferring a page between disk and memory is known as paging or swapping. Demand paging then refers to the copying of a disk page into memory (on-demand) only if an attempt is made to access it and that page is not in memory/cache (i.e. a page fault occurs). This method of loading in a page at the very last minute is used by most modern systems and is advantageous compared to loading all pages immediately because it only loads in pages that are demanded by the executing process, so there is potentially more space in main memory. As a result, more processes can be loaded in, reducing context switching time and there's less loading latency at program startup, since less data is accessed from disk into main memory. Disadvantages include: individual programs face greater latency at first access; possible security risks like timing attacks; and thrashing may occur due to repeated page faults. Here's a comparison between a system using/not using demand paging.
Total Cost
Latency
U = # of pages used U <= N
Demand Paging
U (C + F)
C + F
C = cost of reading 1 page
No Demand Paging
N * C
N * C
F = cost of page fault
The Dirty Bit
The dirty bit tells us whether the associated page has been modified. The dirty bit is set when the processor writes to or modifies the area of memory. Later when we select the page for replacement we examine its dirty bit. If the bit is set, then we know that the page has been modified since its read from disk. So we must write that page into disk to update its contents. If the dirty is not set, the page has not yet been modified since its read from disk and there is no need to write to disk, allowing us to reduce the number of writes to disk.
References:
(1) Eggert, Paul. "Virtual Memory (cont'd) and Processes; Caching Policies." Lecture 15. University of California, Los Angeles. 26 Nov. 2014. Lecture.
(2) Bryant, Randal, and David Richard. O'Hallaron. Computer Systems: A Programmer's Perspective. Boston: Prentice Hall, 2011. Print.
(3) Nathani, Fahad, Nabil Nathani, and Robert Nguyen. "CS111: Operating Systems (Winter 2013) Lecture 15." UCLA Computer Science. N.p., 6 Mar. 2013. Web. 07 Dec. 2014.
(4) Yu, Yiqi, and Yang Lu. "CS111: Operating Systems (Winter 2013) Lecture 15." UCLA Computer Science. N.p., 6 Mar. 2013. Web. 07 Dec. 2014.