UCLA CS111, Fall 2014
Lecture 17 (12/03/14)
NFS Continued
Lesson Outline
Introduction
We're accessing a file system across the network. We have a client (the process) that issues commands like opens, reads, writes, etc.
fd = open("foo", O_RDONLY)read(fd, buf, sizeof(buf))write(fd, buf, sizeof(buf))
Say we have a server with a CPU attach to some files. We want clients to be able to access those files by their own processes without changing any of the clients' programs, even though the files exist on different machines. We accomplish this using a network. The server and the clients communicate with each other over the network, and the clients are able to treat the files on the servers as if they were local. The magic behind this lies with the Network File System (NFS) of the server.
Inside the kernel, we have the Virtual File System (VFS) layer, and the ext4 and NFS file systems are also part of it. The VFS has all the information about how to access/read/write a file. This will marshall the requests, ship them off to the network, the server will take the request, implement the request (e.g. open), send a response back, it'll come back up the NFS layer and back to the client code.
Just as local file systems have their problems, NFSs come with their own share of new problems. These fall into two main categories:
- Performance
- Security
Performance
Performance will be significantly reduced when dealing with an NFS. This is because there is extra distance between the client and the server, both physically and from intermediate software. This makes taking to a file over a network significantly slower than talking to a local disk.
Example 1
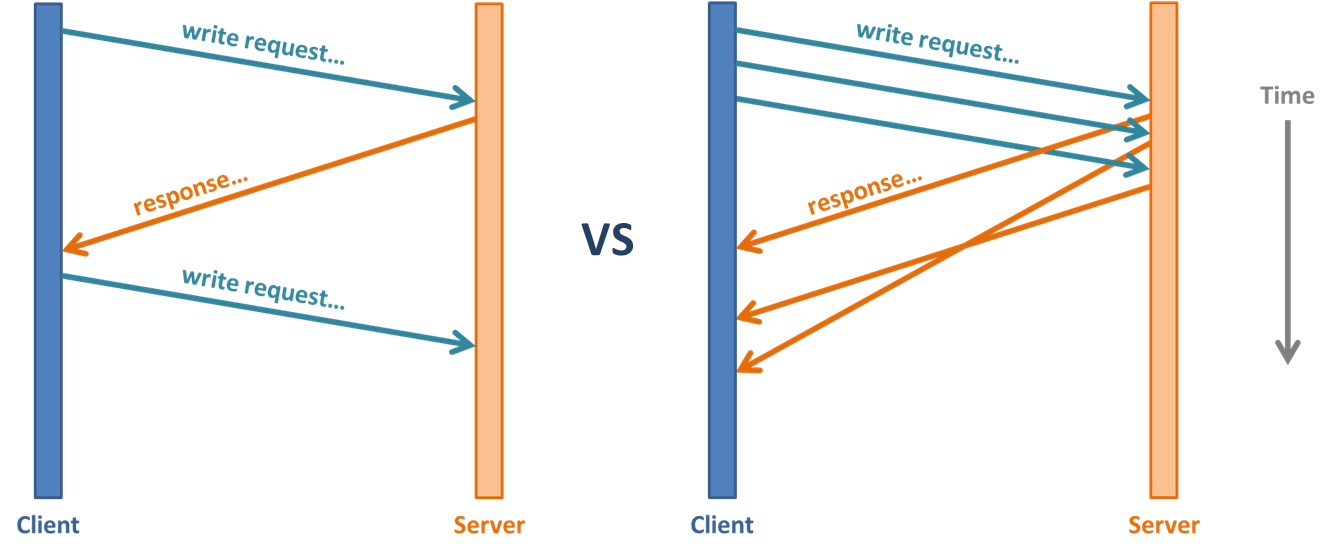
Suppose we're doing a bunch of writes. If we do the writes in a naive way, the client will send a write request, wait for the server, and eventually the server will send a write response saying the write completed. This will be relatively slow because we've added the network overhead twice since we send messages in both directions. We've talked about ways to solve this with RPC, so can we apply the same principles to NFS?
We want the writes to go faster, and one possible fix is to introduce asynchronous reads and writes: send several writes in a row without waiting for each response to come back to the client. Consequently responses might not come back in the same order as the requests were sent. See Figure 1 for clarification. If network delay is large, this will be a huge win over sequential writing/waiting for a response. But a side effect of this is that the client has to issue several write system calls, and when each one returns, the write hasn't actually been done yet (the request has just been sent). This is deceptive. It could return and say it successfully wrote 512 bytes when in actuality the write is in progress or hasn't even started yet.
There are obviously occasions when you need the server to read and write synchronously (e.g. database vendor) What client code could you use to avoid this problem? The answer: fdatasync(fd). This will communciate to the NSF layer to flush its buffers and ship the requests out over the network and wait for the response before returning control to the caller.
Example 2
Let's say the server is using hard disks (they're cheap and provide bang for your buck), so if we actually want the data to be written to the disk there will be ~20ms delay between the request reaching the server and the data being written to disk. This is a long amount of time to wait for the server to respond to the client, so the server can be tempted to "cheat" on the client-side by storing buffers internally of what is to be written and returning control to the caller of the write system call even though the request hasn't been sent to the server yet. After several requests accumulate, the client flushes them all over the server. You can also cheat on the server-side: store the data to be written in a buffer on the server, send the response saying it was written, and perform the write later.
We want one more design constraint for NFS though—it should be a stateless protocol. This doesn't mean the server itself has no state (it clearly does since it's saving your files). By stateless we mean servers don't care about client state. In other words, if the server reboots, when it begins talking with the client again, everything should work like before. These reboots shouldn't affect the client other than performance-wise (obviously if the server is down the client can't execute any system calls for remote files). The only part of the server state that matters is the contents of the files on disk (this was saved to disk so we can pull it off of the disk when we reboot).
With this in mind, is it ok for the server to report to the client that it wrote the data in a write request when it's actually still in RAM? The answer is "no", since the information in RAM will be lost upon crashing, so when it reboots there will be inconsistencies between which files the client and server think are in the remote file system. Because of this, reporting a successful write while actually storing the data in RAM is considered a 'no-no', but there are some vendors who do this anyway because of the performance advantages.
If you're a reputable provider and you want the advantages of cheating but don't want to lose data upon crashing, there is a way to throw some hardware at the problem that allows you to get the benefits of cheating without actually cheating. You can have some flash storage that is used to store logs on the server (See Figure 2). When you do a write, you use a log-based file system and store the log in flash. Remember: flash writes take less time to execute than disk writes, so this is an overall improvement for performance. If you crash, you can replay the log and restore the information onto disk. For this method, CPU, flash, and disk all work together to improve perforamnce (not as much as fully cheating but still a good amount).
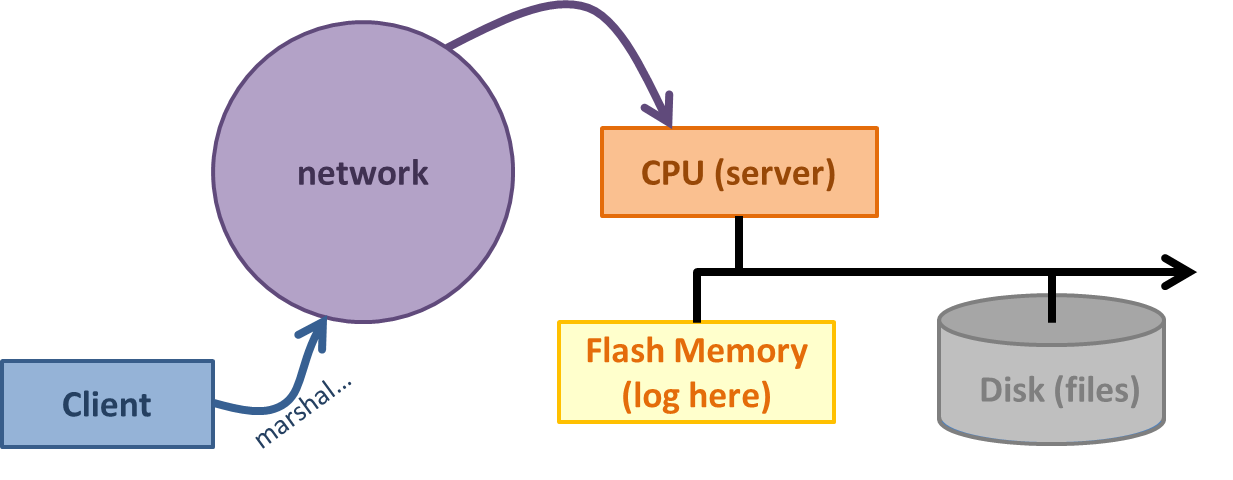
Fun fact: This is what SEASnet does!
How To Implement a Stateless Protocol
Clients still need an efficient way to implement system calls. For example if a client has a file descriptor (fd) with value 19, and it issues a system call for open with that fd to the server, it won't work because the server doens't know what that fd refers to (if it did the server would rely on the client's state and we don't want that!). So we abstract away the part that depends on the client state and just send the part that doesn't.
To overcome this, NFS uses file handles (kind of like a substitute for a file descriptor but doesn't depend on client state). It's a small number (32 or 64-bit int) that uniquely identifies the file on the file server. This number is supplied by the server and has to persist on reboot so the client can operate independently of server reboot. We can put the inode number into the handle since it uniquely identifies the file, but this won't be enough by itself since the NFS server could have multiple file systems within it, and those file systems themselves could be different from each other, so each of these will have their own serial numbers for the files. To fix this, we'll include in the handle the device number that specifies which file system the file is part of. This means that whenever a client wants to interact with a file it'll have to know these two numbers and ship them off to the server over the network.
Problems With File Handles
Using this system for interacting with a remote file system can lead to several issues:
- Assume you send a read request to a server with device 27, inode #39621, offset 39000, and size 512. The device handle is the first 3 fields in this request. But now you have a problem: even though you know all this information, in Linux there's no primitive to open a file based on its inode number! The usual way around this is to add a system call to let you resolve this, but since we're accesing files directly on behalf of many users we'll have to run as root, which means we will have to worry about the NFS's security.
-
In UNIX you can do:
(rm file; cat) < file
You can remove a file, but as long as someone is still reading from it the system won't remove the file from the file system, so this will work in UNIX. Since the kernel knows what processes are running, it'll know when all references to a file are removed and actually remove it. But this doesn't work with NFS because it wants to be stateless (NFS server doesn't want to know who has files open).
For programs that rely on this sort of thing, we have a hacky work-around. When you remove a file from NFS, but there's still someone using it, the NFS layer on the client turns the unlink call into arename("file", ".nfs396271").Then when the process finally exits, the NFS layer in the kernel sees it can unlink it, so it calls unlink and issues that command to the NFS server.
But this approach has downsides:- Other clients can see these files (they're actually there, even if they are invisible by default under the UNIX model)
- If the client crashes, there will be .nfs files lying around that no one will remove
-
If the client tries to remove a file, it will issue an unlink system call.
We will implement that by having the VFS layer send a remove message, which will go
to the NFS server, and then a response will come back to the client.
But suppose the REMOVE message gets dropped on the network (not uncommon)
so the client waits for an answer to come back but nothing happens.
The client will then resend the request. What if it wasn't the request that got lost but the response that did.
Then sending the unlink request again will cause the NFS server to give an error
saying the file doesn't exist because it already unlinked it earlier.
So we use an idempotency cache that looks for this sort of pattern on the server, and when the same request comes in we realize the response was lost and we send it again. But if the server crashes, the idempotency cache gets cleared, and you get the same error you did before: So you have to change your source code to check for the error:if(unlink("file") != 0) -> if(unlink("file") != 0 && erno != ENOENT) -
Another problem is if there are dueling processes. For example, reusing inodes
in a file system is normal.
If client 1 does an unlink of a file (referenced by device number and inode)
and client 2 creates a new file, the inode for the new file might be the same as
the inode of the file that was just unlinked.
Now we have 2 different clients that think the same inode is being used for their file,
so if client 1's response message after the unlink gets lost, it'll resend the remove
request and client 2 will lose its file.
The fix to this is to add a new field to the file handle—another integer that specifies the serial number of the file. Every time you create a file, you add 1 to that file's serial number. The server needs to put the serial numbers in disk so they're stable.
Note: If the idempotency cache could always be trusted then we wouldn't need this serial number. However, it is not reliable after crashes, which is why we need the serial number. - Another problem is that if one client removes a file with a reader, the file gets renamed to something like ".nfs3921". Then if some other client logs on and sees all these .nfs files and wants to do some cleanup, they might remove them without knowing that they're in use. Then, if the reader to that file tries reading, the server will return with the error code ENOENT which could mess up our if-condition from before. To prevent this, they have a special error number called ESTALE that conveys that a file handle is stale. At that point the reader abandons the task and returns the error to the user.
-
Consider the following scenario:
Client 1 does a write to the server and gets an OK back
Client 2 does a read to the server and gets an OK back
But the response message to Client 2 is delayed a little for some reason. So Client 1 may have written 'X' to the file and gets the response back at some time t1. Then Client 2 reads the file (before the write by Client 1) and sees 'W'. But because of the delay in the response message, Client 2 thinks it did the read after Client 1's write. So now Client 2 thinks it has the value of Client 1's write when it really doesn't. There's also clock skew that can lead to this effect. So when you do something like
you should use the server's time stamp because it arbitrates differing client clocks.ls -l --full-time file #shows modification time to nearest ns -
NFS clients cache writes for the same reason they cache writes with an ordinary file system.
So if one client writes a file (but it isn't really written yet because it's in the
client's cache) and another client tries reading that file, you will run into problems.
This is common enough that NFS actually has a requirement in the protocol that
when you close a file, you have to flush all buffers and make sure they send properly.
But this means
close(fd)can be very slow!! Also this might not work because the network might be down so the close will hang. Soclose()can potentially fail, even though on a local file system that can't happen.
Security
Issues and Goals
We've talked a lot about performance, so now we're going to talk about security. What are some possible security problems? Well, when a client sends a message to the server, it specifies the user id and group id (both ints) of the client to specify the access privileges. This can be exploited. How can we fix this?
- Lock access to files physically (make sure all clients and servers are trusted). You can force all clients to agree on user ids and to require passwords to log in
- Use a secure protocol (clients are authenticated via a method the server trusts).
Another issue is that data can be snooped or altered. We can fix this by using the simple approach above (use routers you trust), or through encryption. In the real world, we need to defend against attacks like this by force. There are also attacks by fraud (this is the major one in CS and OS). Main form of attacks are against:
- Privacy: attempts to find out data you don't want disclosed
- Integrity: putting bad data into your system (tampering with other people's data)
- Service: trying to prevent other people from using the service (denial of service)
So our general goals are to:
- Allow authorized use/access
- Disallow unauthorized access
- Maintain good performance
If you're testing a system you're trying to make secure, it's easy to test for authorized access (users will complain and tell you). It's hard to test for unauthorized access because people who exploit it won't alert you about it. Testing for performance can be easy or hard depending on which aspect of performance.
Attacks are common:
- 2014-11-28: Sony hack attack from North Korea (done via malware)
- 2012-03-01: DoS attack on BBC by Supreme Council on Virtual Space (Iran)
Threat Modeling and Classification
We want to take the infinite list of attacks that are possible and organize it such that we only worry about the attacks that are most likely. The largest threats are:
- Insiders
- Social engineering: tapping into phones, etc.
Trying to get fraudulent credentials doesn't require much technical knowledge (Kevin Mitnick) - Network attacks: buffer overruns, javascript mistakes, etc.
- Device attacks: viruses on USB drives that infect a computer when inserted
You should think about all these, list the ones most likely to damage your system, and prioritize which are the most serious. The general techniques needed for any secure OS are:
-
Authentication- prove you are who you say you are.
- Password
- Public/private key pairs
- Biometric
- Two-factor (choose two of the above)
- Integrity: checksums
- Authorization: keep track of what you're allowed to do (permissions)
- Auditing: use logs to keep track of what was done (accesses to the system) and when people make changes to authorizations