CS 111 - OS OrganizationScribe Notes for 10/15/2014by Kai-Zhou Yang, Quanjie Geng, and Ran GrossOS Organization Goals
3 Fundamental Abstractions for SystemsMemory APIMemory is the sytem abstraction that deals with remembering data for future computations. In its simplest form, the Memory API has two fundamental operations, named
Some issues with the memory API that must be addressed are the following, which will be expanded upon in later lectures:
Interpreters API
The interpreter abstraction describes the actions taking place in a system. By layering several instances of this abstraction in both hardware and software, extremely high-level processes may be realized, such as from machine-level instructions to a word processor. To achieve efficiency, the interpreters API also requires hardware support, which is seen in such instances as the CPU. The API is defined by 3 properties:
The connections between successive layers of interpreters abstractions may be extablished using interrupts. In this sense, upon reaching an interrupt instead of executing the next instruction a different program takes control of the interpreter, thereby changing out the interpreter's instruction and environment pointer The Interpreters API should also be "safe". The definition of "safe" depends on both what sort of restrictions on access should be imposed onto the user as well as how much performance should be achieved using the API. Balancing these aspects requires virtualizing the processor and controlling how much direct hardware support for the user should be integrated into the API. 
Priority in Virtualization
Link APIThe link abstraction allows communication between distributed machines by passing messages, the main advantage of which is that machines may be located anyhere. By abstracting the OS from the machine, the kernel can be located anywhere. For example, Macintosh OS X relies heavily on the link API. As with the former two abstractions, the Link API is simply defined:
A significant disadvantage, however, is that data to be sent on communication links must be serialized, meaning it must be in a specific format such as XML, which may not be possible for all data types such as pointers. Such a high-level abstraction will naturally come with performance issues as well. An Object-Oriented Operating System?An approach to implementing an operating system is an OO approach such as that of Windows. We may write classes for I/O, buses, memory, and the interpreter, but as with most OO approaches we suffer a performance price. LayeringOperating systems make sure that application access intructions properly. Some instructions are dangerous if performed maliciously. For example, the halt and catch fire command stops the fan and let the computer burn or using the read and write commands on global memory where they can access memory outside of the program, which is bad normally. Therefore, we need to check an instruction before execution. However, if all the instructions are checked and performed, the computer would be ridiculously slow. So, we classify the instructions into two types:
Unprivileged instructions are the safe instructions. They are executed on the hardware without check. Privileged instructions are the dangerous ones. They need to be checked before execution. Thus, they are passed to the kernel to ask for its permission to run, so the kernel can decide whether or not run the command. The kernel then uses system calls to perform the instructions. This strategy is called layering. There are two ways of visualizing layering. Wedding cake diagram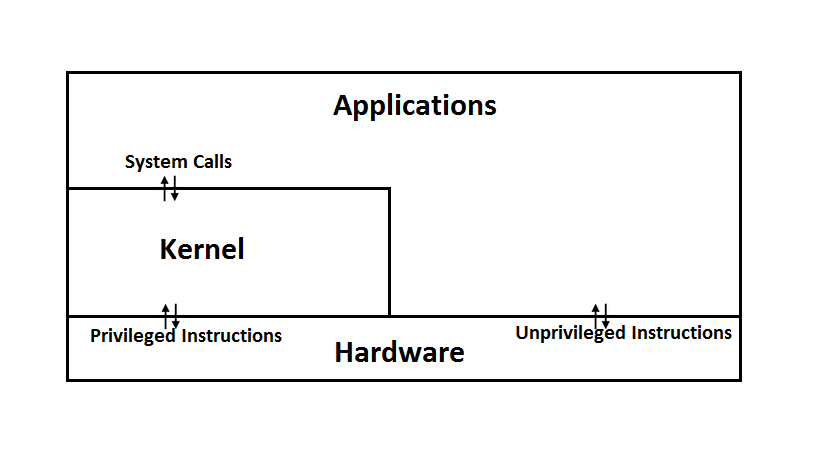
The wedding cake diagram shows a logical view of how this works. it shows on the bottom the hardware level, which only the system calls can reach. It shows how the unprivilaged code can be reached directly by the user, while there is an a layer above the unprivilaged commands where the user first bypasses the kernel before they get tot he hardware. Above this, there can be added more layers before the actuall user where the user gets pretend code that ends up calling the real code after bypassing a few layers. Ring diagram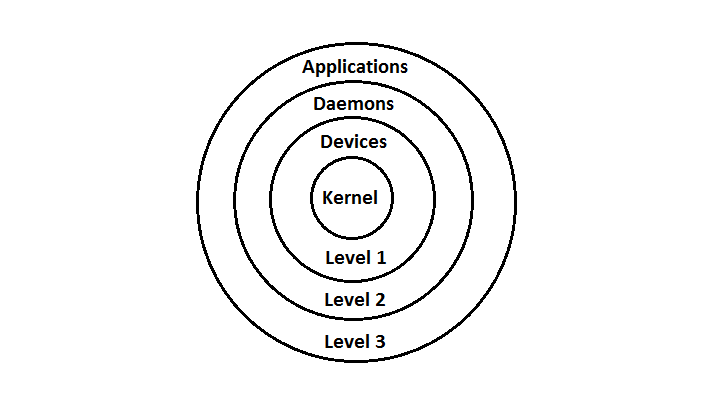
The ring diagram is another way of representing the same thing. Each additional ring represents a possible layer that can be used before the actuall apps the user is able to see. Operating System + Virtualizable ProcessorThis virtualizable processor let you support a process Process: Program running in isolation (on a virtual interpreter) By using virtual processors, we can run several processes all at once by jumping from one to another. This can be done as we store the state of a process and switch to another, and then come back to the original later. Accessing MemoryEach process has its own view of memory. 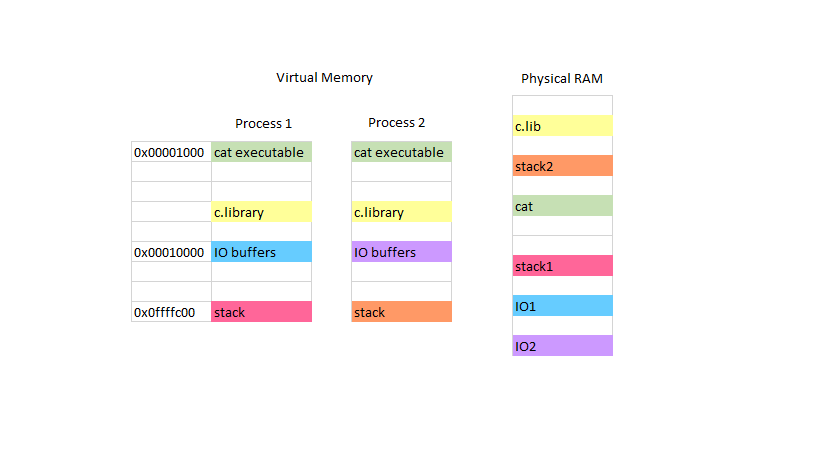
In between two processes, there are parts of the memory that are different, and some parts that are shared. Areas of memory like the C libraries and innate commands of the kernel are shared, as represented int he picture above by 'cat' executable and C library. These shared memory is read-only memory. Other parts of memory, like I/O buffers, and the stack is represented for each process individually. These are considered private for each process and can be rewritten by the respective process it belongs to. To create a child process from a currently running process, the fork() command can be used. pid_t is an innate C type used to describe process IDs. This fork function will return to the child 0, in the code above p=0 for the child.On the other hand, it will return to the parent process the process ID of the child. If there is an error, such as it cant create any more processes, it will return -1. Fork bombrefers to endlessly making new processes untill the program can't continue(fork returns -1) Example This will cause every new process made to create a child process of its own and go on linearly untill it returns a -1 and sett errno. Another example is: Which will break faster than the previous example. PROCESS TABLEYour computer has only one physical cpu, while it can run more then one processes at the same time. How does it happen? In order for a single processor to run multiple processes it has to switch mid-process between the different processes. To do that, between every switch, it keeps track of the current process by storing its state and registers to memory (the process table) while loading the next process's state and registers to start running. 
The process table above shows how the processor stores processes while they are not in use. The rows in the table represent the different process by their ID whilethe collumns represent which part of the process state is being stored, such as all the registers and the process state. A process not in use (process 12 in the table) holds values we do not care about, junk memory. A process like this could be used when fork is called. When fork is called, it copies most of the process state from the caller to the new process, which is chosen from one of the unused processes. Registers like esp and eax will not be copied directly. esp since the new process will have a stack of its own somewhere else in memory, and eax since fork() will return a 0 to the child and the process ID of the child back to the parent(the fork is shown by process 23 and 52). Changing between one process and another works similar to: In order to destroy a process, nothing needs to be done on the programmer side, processes destroy themselves. This system call below is used to exit a process once we are done with it. The intiger that is passed in as an argument is the exit status of the program. The exit function below is the one more commonly used in programs. This exit function is a library function that first flushes the output buffers and then calls the _exit system call after. The noreturn clause is used to signify that this function will not return, so there is no need to make any special preparations for it (for example, there is no need to set up the return address in the stack, since it will never be used). An exit status of 0 is considered a success, while any other exit status (from 1-255) is considered some form of error. When a process exits, its process state is changed to that of a zombie, which means that int he process table, all the values other than the exit status which we still care about is considered junk. 
Once the waitpid command is called on the exited process, its memory is finnaly freed, and its state changes to that of an unused process, so the process ID can be reused. It is in a way works similarly to a process destructor. While the process is waiting on another process, its state is shifted to blocked, and this allows another process to run in the meanwhile without having the process that called waitpid have to use processing power. waitpid takes in as its first argument the process ID of the waited-for process. Its second argument is the location used to store the exit status of the waited-for process. The third argument is flags used with waitpid. Something like WNOHANG which makes it so we no longer wait for the process, but rather if it did not yet exit, we kill it and put a 0 for the return value, if it did exit in time, this function returns normally. waitpid return -1 if an error occures and the process ID of the child process whose status is reported if it succeeds. 
The cat excecutable is made of some glue code that is used to tie it back to the overall process that called it when it is done running and object code cat.o that represents cat's main program linked in the excecutable. The glue code is something like a: where it takes the return value of the main function for cat and uses it as the exit status. PIPEThe pipe command bounds a queue of bytes stored in kernel memory. Pipe takes in as an argument an array of 2 elements of type int and uses them as a file descriptor (1 read, 1 write). The reading hangs if there was no data written yet or it gives the data stored there if there is some. pipe can be used with fork in order for a child and parent to communicate with one another. |