Scribe Notes 5-31-07
A Product of Kevin Lau and Mike Wilson
The Remote Procedure Call (RPC)
The way it used to work:
The interface was maintained so that only the callee will have to change.
Now:
Callee:
int open (char const* file, int opts) {
// send a message to the server
sendmsg(server, “LOOKUP”, “foo”);
// look up foo, wait for response
wait();
// receive response
recvmsg(response);
return fd;
}
The core of RPC is Request, Response.
+ Hard modularity comes “free” with RPC, so we don’t need to worry about the callee.
+ Caller and callee don’t need to have the same architecture, so PCs can talk to Sun, etc.
+ In principal, you can exploit the parallelism => scalability
- No passing by reference => large structures must be copied, a slow process.
- The procedure call overhead is slower
- The are PLENTY of security issues.
± Reliability: + if a client goes down, we’re still okay
- if the network goes down, we’re not okay
Example: Send the time and date.
One possible, and popular, solution is to use Unix Time, the number of seconds that have elapsed since Jan 1, 1970 at midnight UTC. The start of our class today, May 31, 2007, was 1180576800. This will package very nicely in 32 bits, which means that we’ll need to send 4 bytes across the wire. Now we need to know how we will package those bytes, and there are two common methods: big-endian, and little-endian.
For four bytes labeled left-to-right 0,1,2,3, a request to send these bytes would result in the following orders:
Big-endian: 0,1,2,3
Little-endian: 3,2,1,0
The standard now is big-endian because IBM was bigger than the other companies and wanted it that way.
Informative Sidebar: In a paper published by Danny Cohen entitled “On Holy Wars and a Plea for Peace”, Cohen borrowed the terms “Little-Endian” and “Big-Endian” from Swift’s Gulliver’s Travels. Gulliver found out that there was a law proclaimed throughout Lilliput that eggs should only be broken on the little end, a law which infuriated those Lilliputians who broke their eggs on the big end, the Big-Endians. A great war broke out, and eventually the Big-Endians found refuge on the nearby island of Blefusco, but 11,000 Lilliputians had to die first. Swift uses this story to make a statement about Holy Wars, but that’s not why we’re here. What’s more important is that Cohen identified the conflict and allowed us to talk about Big-Endian and Little-Endian instead of Least Significant Bit or Most Significant Bit.
B. In order to rewrite all of your code, you will need a significant quantity of stub code that arranges the marshaling, unmarshaling, sending, and receiving. The task of providing this stub code is annoying, boring, and error-prone. That’s why there are lots of stub generators in existence that will arrange all of your calls as RPC. Yeah!
In 1990 a physicist at CERN (they’re almost done with the world’s largest particle accelerator!) invented HTTP as a way to share information between scientists at CERN. Unfortunately, he was not a CS guy.
A request has this format:
HTTP/1.1 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Server: Apache/1.3.27 (Unix) (Red-Hat/Linux)
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Etag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Content-Length: 438
Connection: close
Content-Type: text/html; charset=UTF-8
<html>BLAHBLAH</html>
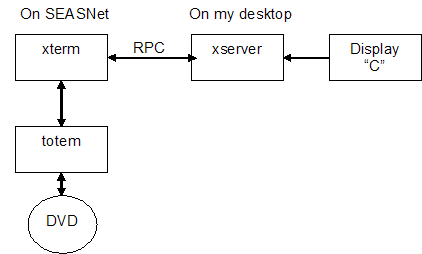
You can log into SEASnet and run xterm, which will pretend to be a terminal on whichever X server you’re logged into.
Less Interesting Sidebar: Prof. Eggert does not recommend streaming video between here and Outer Mongolia over xterm, because it might be a little slow.
If there is no response, we run into a few questions.
Q. How long should you wait?
A. No matter what you choose, you’ll be wrong. It depends on the speed of your network, the patience of your users, etc.
Q. If it does timeout, what do you want to do?
A1. Keep trying, a.k.a. at-least-once RPC. This is most suitable for idempotent operations, which are operations where the result is the same even if you perform the operation more than once. For example, writing the first byte of a file.
A2. Report the error to the caller, a.k.a. at-most-once RPC. This is suitable for operations that should only happen once, or fail, such as transferring money between accounts.
A3. Exactly-once RPC. This is ideal, but is also impossible. You can do this with high probability, but it can get tricky.
Example: Reading a file. Sending a request and waiting for a response before sending another request wastes too much time.
To improve performance, you can do two things:
1) Send multiple requests without waiting for a response, which is called asynchronous communication. This is much more efficient and has significantly higher throughput.
2) Use caching to store the previously read information in case the user requests the same information again. This introduces some synchronization issues.
Extended Example
NFS – The Network File System, developed at Sun in the 80’s.
The NFS was developed because people at workstations wanted to share their data, but they had to copy the files between themselves using FTP. So, they developed NFS to allow multiple workstations to access a common file system.
The workstation requests the file “foo” from the file system, and the VFS layer routes that request to the NFS. The NFS uses stubs to send a request across the network to the NFS Server, which finds (or doesn’t find) the requested file on the disk. Then the VFS Server returns a unique file handle to the NFS on the workstation, by which that file system can access the file on the server.
For example, LOOKUP(directory_filehandle, name) will look for that file. So, in order to find file /a/b/c/d, the system would need to perform 4 LOOKUPS to move up from root to the appropriate file.
Other commands include:
CREATE(dirfh, name, attributes)
MKDIR(dirfh, name, attributes)
REMOVE(dirfh, name)
READ(fh, nbytes, …)
WRITE(fh, data, …)
One of the main design criteria was robustness, for the following reasons:
1) If one child crashes, the other should still work just fine. This implies that no clients are allowed to lock files.
2) If the server crashes and reboots, the clients should not notice anything but a slight slowdown. In this manner, it acts like a flaky network that sometimes drops out and comes back. Further, this implies that the NFS Server must be stateless.
As a result of these conditions, the file handle implementation looks like this:
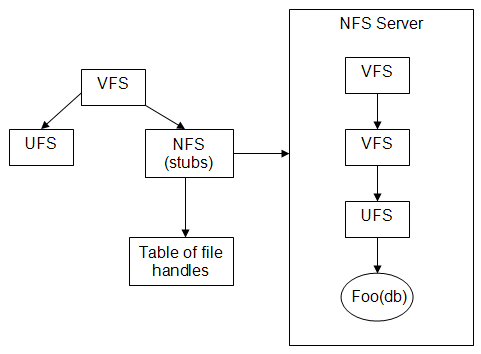
The serial number will increase each time the inode is reused, in essence maintaining a version number for each inode. As a result, the inodes in the VFS will each maintain an extra field for the serial number, so that it can be updated and attached to the file handle.
The important result here is, when a request provides this information, if the serial number provided and the serial number of the inode do not match, we report the error “stale NFS file handle”.
Unfortunately, this means that if one person opens a file, and another person unlinks that files, or removes it, then when the first user tries to read from the file, they will receive the “stale handle” error.
The Performance of NFS, courtesy of www.spec.org
SPEC SFS97R1 V3.0 for NFS
Tested on
Network Appliance FAS3040A (2007)
1 2.4 GHz Opteron 250
8 GB RAM
4 Disk Controllers
224 HDDs, 72 GB each, 15000 RPM with FCAL (Fiber Channel-Arbitrated Loop), dual-parity RAID
1 GB nonvolatile RAM, used as a cache for writing
In comparing the throughput, in number of operations per second, against response as the average latency, in ms, per response, we see that the performance is incredibly fast. This speed of performance can be achieved using the following techniques:
1) Use asynchronous requests, as discussed earlier.
2) Use caching, as discussed earlier.
Unfortunately, we need to worry about synchronization issues, since there is no read/write synchronization in NFS.
However, there is an open/close synchronization. Basically, if you close a file and get an okay, then we know all the writes were successful. In this way, we can get a level of synchronization. But that means that we had need to test the close, as follows:
if (close(fd) != 0) …