Weapons Against Complexity:
Modularity and Abstraction
By Kevin Lau and Mike Wilson
Goals:
Goodness Measures for Abstraction:
1) Performance: our real systems must run in a way that pays the bills.
Generally speaking, modularity will hurt performance, and our job is to minimize that damage. A performance reduction of 10% is not so bad.
2) Robustness: defined as tolerance of faults and errors. This makes it so that each module is able to contain a maximal amount of damage.
3) Lack of Assumptions/Flexibility/Neutrality: maximize the usefulness of the components and modules by removing constraints on the system.
4) Simplicity: make the system easier to build, document, understand and use.
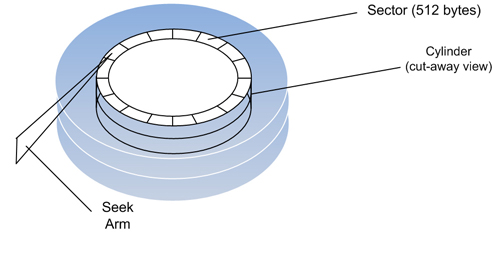
A Review of Disk Drives:
Time required to seek and read any random sector: 12ms.
Number of operations that can be performed in a period of 12ms: 12,000,000.
If the read head is in the right spot, about 100 MB/sec can be read from the platters.
Cost of Memory:
Disk: ~$ 0.30 / GB
RAM: ~$ 60.00 / GB
Prof. Eggert purchases ECC memory (error-correcting circuits or error correcting code, or error correction code).
Our Program:
Compute the number of words in a file: words are defined as the longest string of bytes matching the pattern [a-zA-Z]*.
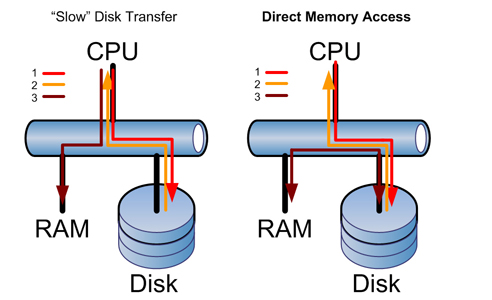
This is definitely not an efficient way to do things.
1) Performance: the CPU sits idle while the information is retrieved.
Thankfully, we can use DMA (direct memory addressing) to write from the bus directly to RAM.
How your computer boots:
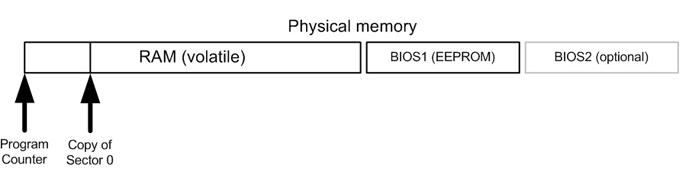
1) The CPU starts with a program counter pointing to a point in BIOS (Basic Input Output System) in “real mode”, which means that there is no indirection or other tom-foolery.
Side Note: A bit about BIOS:
1) Since the CPU will run whatever code is sitting in BIOS at the other end of that pointer, you better have something good for it to do.
2) The BIOS is stored in EEPROM (Electrically Erasable Programmable Read-Only Memory), which means that it can be damaged, overwritten, and corrupted. That’s why most modern systems come with two or more copies of the BIOS.
End Side Note.
2) BIOS contains a program written by smart people in companies you’ve never heard of.
3) The first part of the program is a self-test, which checks the BIOS, the CPU, and the memory.
4) Next, the bus is scanned for devices, a process which can take some time.
5) The “most likely” device is identified, and sector 0 (the Master Boot Record, or MBR) is read into RAM.
6) The program counter jumps to sector 0 in RAM.
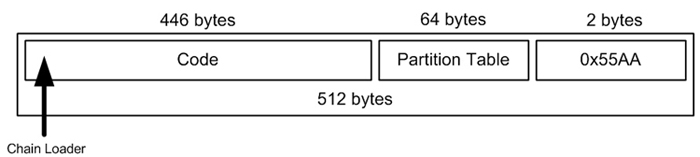
7) MBR- Sector 0: 512 bytes total.
The first 446 bytes contain code to do things.
The next 64 bytes contain the partition table, which has four 16-byte entries. Each entry contains information regarding:
a) where the partition starts
b) how large it it
c) the partition type (an 8-bit field)
d) other flags, such as whether the partition is bootable.
The final 2 bytes contain 0x55AA (0101010110101010), which helps identify that this sector really is the MBR.
8) The code of the MBR finds a bootable partition, and loads the Volume Boot Record (VBR) for that partition into RAM over itself.
9) The Volume Boot Loader usually chain loads a much larger boot loader, such as GRUB (Grand Universal Boot Loader), which finally contains enough information to load large operating systems.
Our first chance to add a fast word counter is to load the program from the VBR. Assuming that this is done, the program is now sitting in RAM, and we need to identify where the words are located, how the data is stored, and how big the record is. We will identify the file by the starting sector and the number of sectors that contain it. As a matter of convenience, we will define the first two words in RAM directly following our program.

Currently, our program operates in this manner:
1) First, we read in some data.
2) After we finish reading, we count the words that we read.
3) We can repeat this process until we reach the end of the record, causing the CPU to wait during the read, and the hard disk to wait during the counting procedure.
4) After we are done, we can print to stdout.
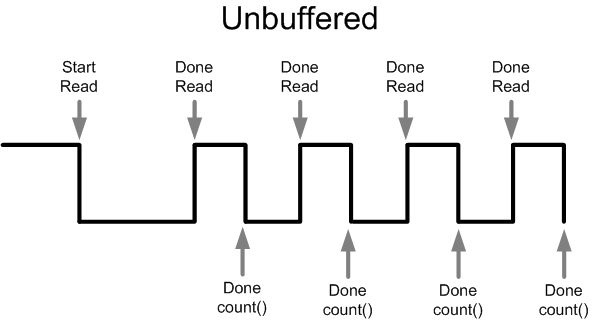
Unfortunately, this is a very inefficient way to do things since it takes so long to line up the read head and pull data off the platters. So, let’s try again.
1) First, we read some data into a buffer.
2) Then, after we finish, we request the hard drive to read more data into a second buffer while we utilize the CPU to count the words in the first buffer. If we are fast enough, the read heads will still be close enough to the place they finished reading to pick up again without much or any lost time (thanks in part to buffers on the hard drive).
3) After we finish reading into the second buffer (assuming that the CPU has finished counting) we read into the first buffer while the CPU counts the words from the first buffer.
4) We can continue this alternating sequence until the file has been read and the words have all been counted.
Ideally, we will find a balance between then amount of memory that will be read into a buffer and the length of time that it takes to count the words in that buffer. This use of two buffers is known as double buffering.
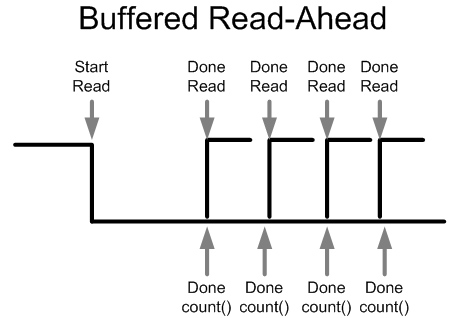
An analysis of our performance:
1) Performance: fantastic. We get a gold star, because our system is so fast. Everyone will want one. We might be the new Microsoft.
2) Robustness: not so good. If this program fails, our computer is not going to work, and we get to hit the reset button.
3) Neutrality: really not good. We’ll have to know quite a bit about their system to be able to get this program to work right.
4) Simplicity: stinky cheese. Our users better know how to get this program to load from their VBR and where to put their file, or else they’re hosed.
Since that didn’t work very well, let’s introduce a little Modularity by splitting this into two pieces: the Operating System and Application.
Interface #1:
Our first Application Programming Interface (API): isn’t it cute?!
void free(void* memptr); // Memory Allocation
char *readline(int fd); // I/O
This new function, readline(), will allocate memory, read one line, and return a pointer to the newly read line. When the end of file (EOF) is found, readline() returns NULL.
In order to use this new interface, we’ll create a very simple program.
char *p;
while (p = readline(0) != NULL)
{
// count the words
n += countwords(p);
//prepare to do it again
free(p);
}
Yeah! Wasn’t that easy?!
Unfortunately, there are three problems with this general solution.
1) This design allows only sequential access to the file.
2) Really long lines of text are not handled well, which will keep the CPU tied up while we search for the end of the line or EOF.
3) This design fails to support multiple systems and styles, assuming a UNIX-like line end.
We are not quitters, so we shall try again.
Interface #2:
In order to promote modularity, we’ll leave the original application and glue the old application with this new interface.
size_t linelen(int fd); //returns the length of the line
int readbyte(int fd); //only reads one byte, and returns –1 at EOF
The glue:
char* readline(int fd)
{
size_t l = linelen( fd );
char* line = (char *) malloc( l );
for (size_t i = 0; i ≤ l; i++)
line[i] = readbyte( fd );
return line;
}
We partially fixed the original problem #2, since the CPU won’t be locked up on long lines during readline() waiting for the end of the line. The new function readbyte() introduces some additional CPU overhead, which cuts into our performance. In addition, the computer still has the opportunity to lock up on linelen(), which will run a long time if it can’t find the end of a line.
In addition, we failed to address the forced limitation of sequential access.
Interface #3:
Finally.
This time, we’ll get rid of linelen() and introduce realloc(), which will allow us to resize our memory as needed.
void* realloc(void * ptr, size_t nbytes);
char* readline(int fd)
{
size_t nread = xxx; //this is the number of bytes to be read
size_t allocated = 1;
char* line = malloc(allocated);
for (int c; (c = readbyte(fd)) != \n && c != EOF; line[ nread++] = c)
if (nread == allocated)
line = realloc (line, allocated *= 2);
return line;
}
This will solve problem #2, since the control can be wrested from the application in the event of a long line.
In addition, problem #3 is solved using this interface since this is an application and can be written to support any necessary requirements or system preferences.
Thus we see that we really can accomplish a great deal if we pool our strength, believe in ourselves, and listen to what Professor Eggert teaches us.