CS 111 section 2
Scribe notes for 4/17/2007
by Keith Stevens and Alex TicerCalling the Kernel
How to call the kernel
Method 1
Treat any method calls as a simple function call. This is a very simple implementation and provides fast responses from the kernel. Unfortunatly this gives the application the same level of power as the kernal since the kernel's functionality is nothing more than a set of library calls. With this much power given to the application, it is more capable of producing malicious behaviour. This approach is best used in embedded systems where the applications well inspected and well controlled prior to being installed.
Method 2
This method will use interupts to switch control over to the kernel. Ordinary functions can function at full speed when performing standard operations, such as adding, multiplying, loading/storing from the applications local memory, etc. When an application needs the a service provided by the Kernel it will cause an interupt in the hardware which will then be serviced by the kernel.
The kernel will maintain a table of interupt handlers which designates what actions to take based on the specific interupt number recieved. For example on the X86 processors the command INT 25 will produce an interupt to be sent from the CPU with and interupt handler 25 will take control.
The advantages of this approach are that it hands all control over to the kernel since only the kernel will decide how to respond to interupts, not the application. Unfortunately this method is slower than Method 1 since interupts can occur at any time, the interupt handler must a larger amount of information than a function call requires.
What can go wrong with this approach
- A system call might malfunction and never return
- kernel has the ability to modify the application's stack and code
- slow due to overhead of saving the applications state
- number of possible interupts is hw dependent
File Access
Each process has it's own unique file descriptor table, which can be used by the process but is maintained inside the kernel. This allows each process to modify which files it can read or write from without affecting any other process. the contents of each entry in the file descriptor table points to a System wide file table which only the kernel has access to.
Standard File Descriptor Entries
- 0 - stdin
- 1 - stdout
- 2 - stderr
Below is an example of how redirection of a file descriptor might be implemented.
Example: sort>/tmp/foo
close (1);
if(open("/tmp/foo",0_WRONLY,0) != 1){
abort();}
execvp("usr/bin/sort",...)
However, this doesn't work because the file descriptor 0 might be available. Open() works such that it returns -1 on failure and otherwise the number of the lowest available file descriptor. The use of the function dup2(int old_fd, int new_fd) is required. It will make a copy of the old file descriptor and return the int new_fd upon success. Thus, now they are pointing to the same file but if an error occurs it returns -1. No operation occurs if old_fd == new_fd and old_fd is a file descriptor number.
Instead use this style
int fd= open("/tmp/foo", 0_WRONLY,0);
if(fd<0) abort();
if(fd!=1){
if(dup2(fd,1)!=1) abort();
close(fd);
}
execvp(...);
This should solve most of the problems that might occur because it checks to make sure the function opened and didn't have an error. If fd doesn't point to the right file descriptor then use dup2 to set it appropriately and make sure no error occured here either. Finally close fd.
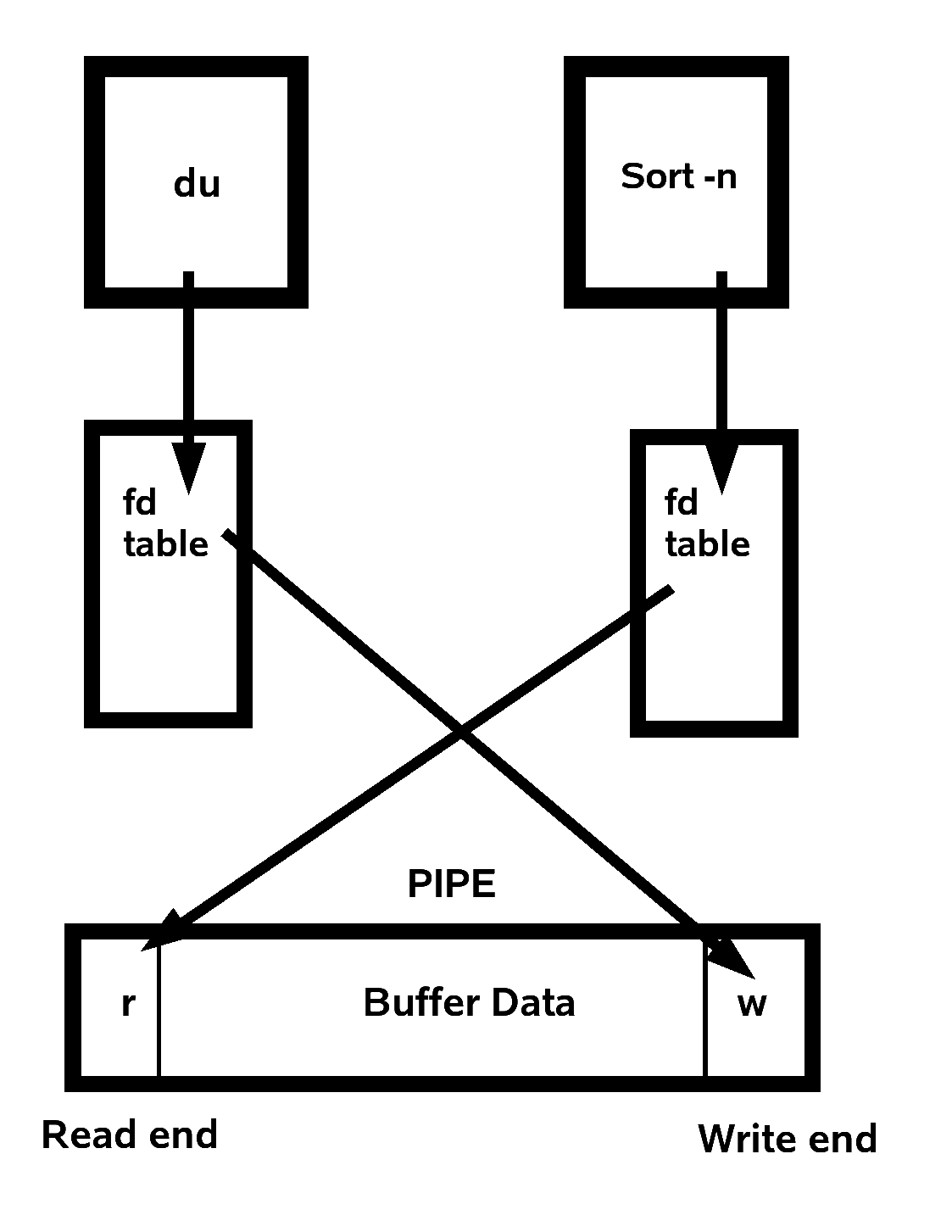
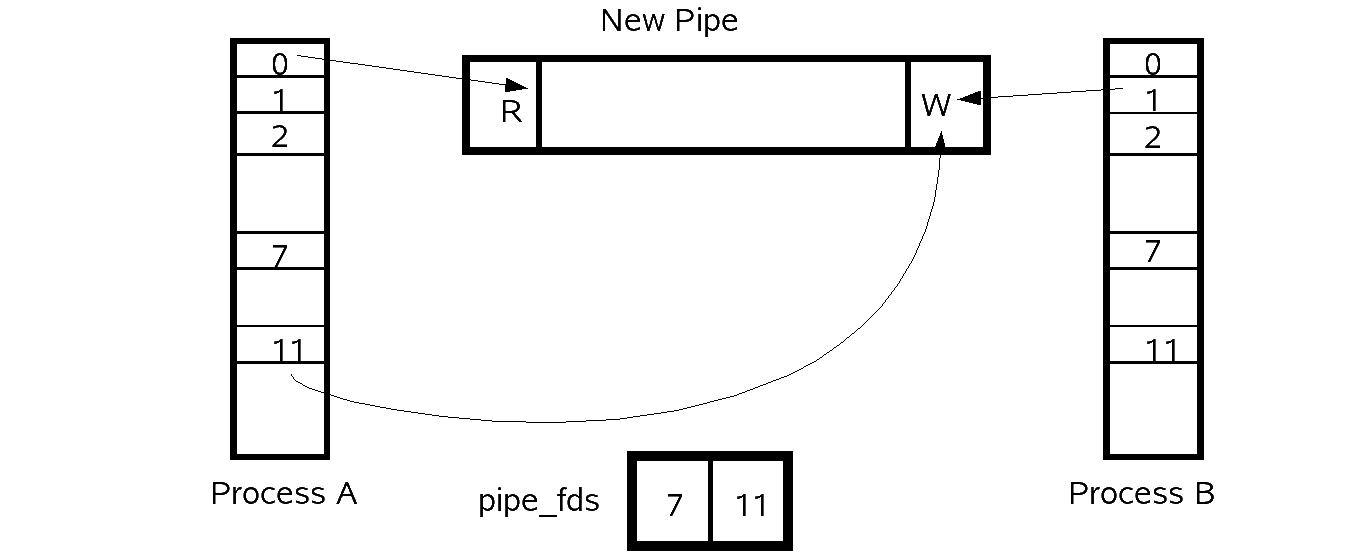
Pipes
Pipes are used to link the output of one process to the input of another process while keeping these processes completely seperate. An example of piping commands together is given below:
$ du | sort -n
This is a general overview of what is taking place.
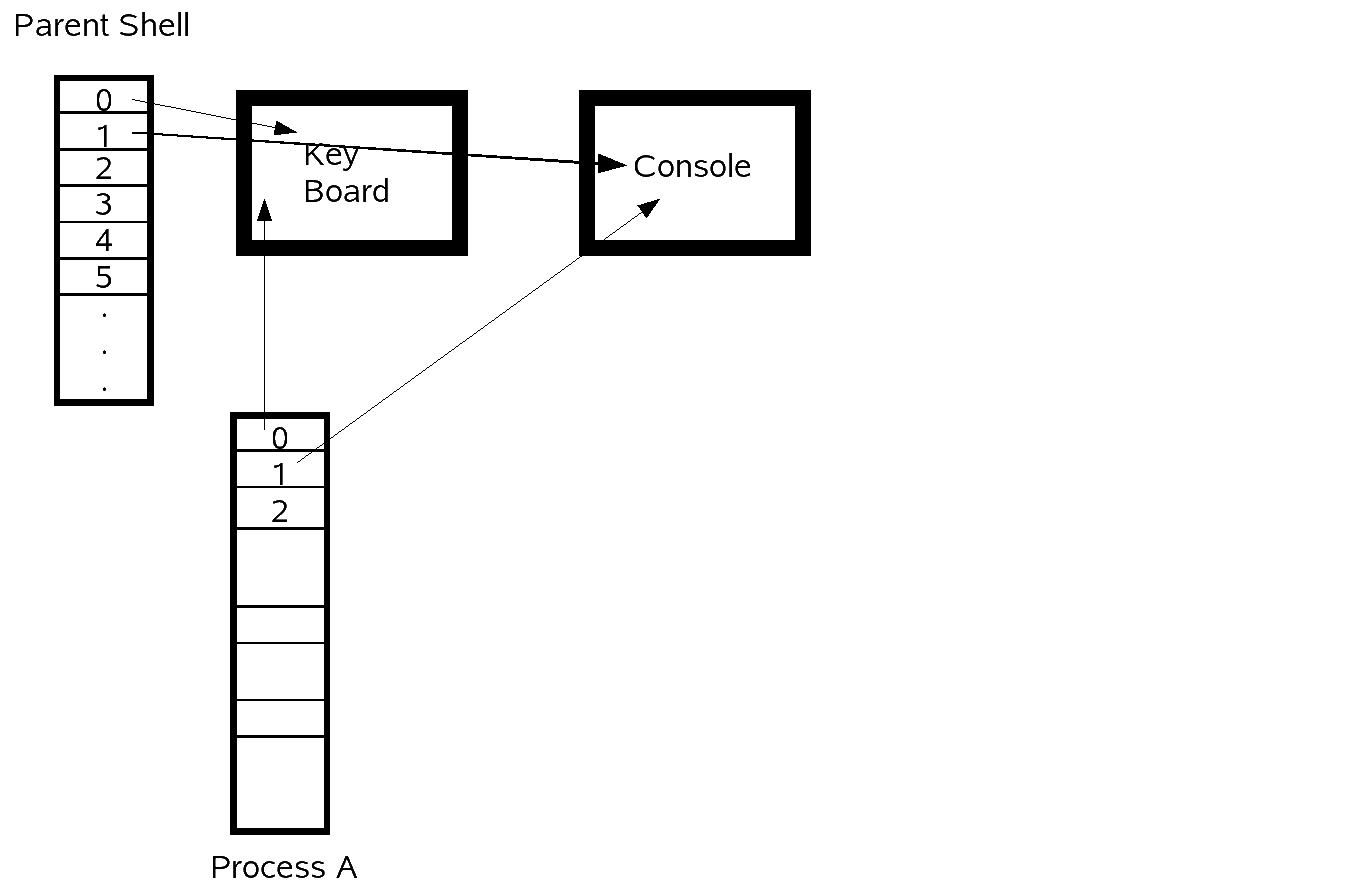
From the parent shell a fork is done. This splits the parent shell and process A. In the parent it will call waitpid() and wait for the child process A to terminate. Inside the child process A another fork is done which splits apart process A and process B. For the example of $ du | sort -n process A will be sort -n and process B will be du.
Process A
Inside process A, in this case sort -n, it will setup its own file descriptor table. Originally these will point to whatever the parent's file descriptor table pointed to, because the fork just copies this over to the child. Thus the file descriptor 0, which probably pointed to STDIN, the keyboard, will be set to point to the read end of the pipe. Also, careful attention must be paid to which file descriptors need to be closed or else bad things may happen. This is discussed later.
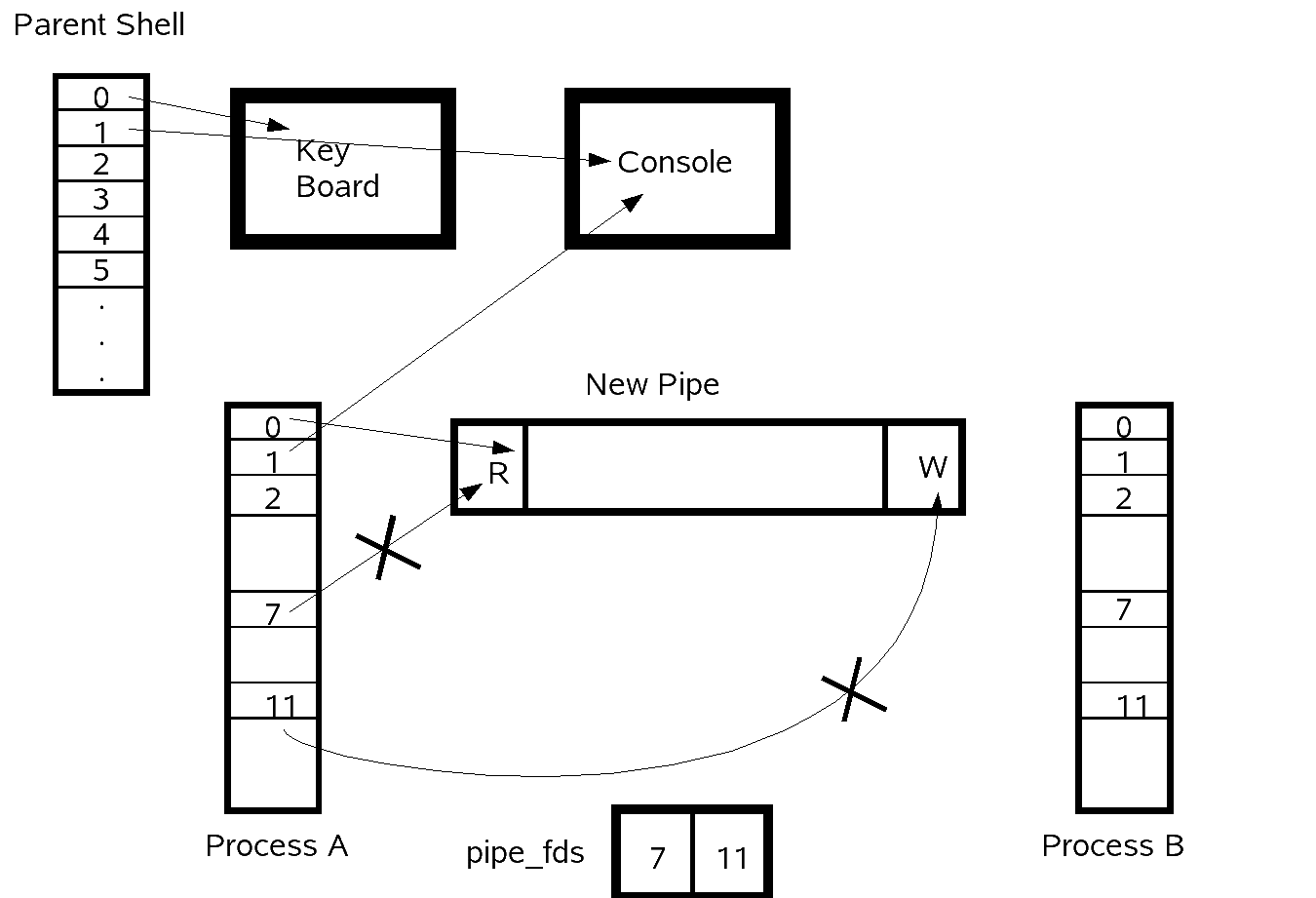
Possible code for setting up process A:
if(pipe_fds[0] !=0){
dup2(pipe_fds[0],0);
close(pipe_fds[0]);
}
close(pipe_fds[1]);
execvp("sort",...);
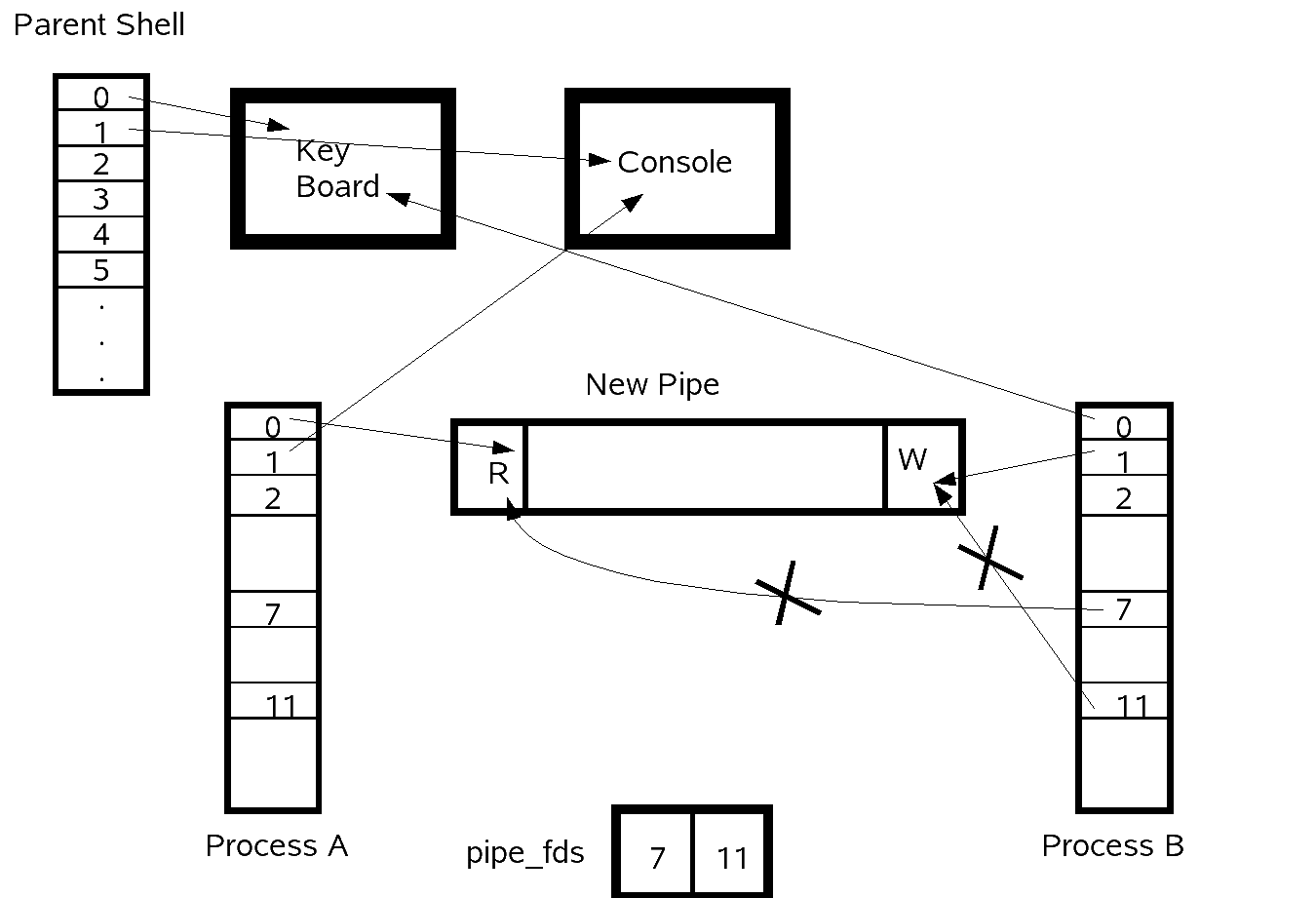
Process B
Inside process B, in this case du, it will setup its own file descriptor table just as process A. This will point to whatever Process A's file descriptor table pointed to for the same reasons as given for process A. Thus the file descriptor 1, which probably pointed to STDOUT, the console, will be set to point to the write end of the pipe. Just as in process A, careful attention must be paid to which file descriptors need to be closed.
Possible code for setting up process B:
if(pipe_fds[1] !=0){
dup2(pipe_fds[1],1);
close(pipe_fds[1]);
}
close(pipe_fds[0]);
execvp("/bin/du",...);
Diagram of File Descriptor Tables and Pipe Setup
Things to consider:
Normally if sort were to crash the pipe would then have no readers and the writer would get killed. Yet, if we had forgotten to put close(pipe[1]); before execvp in process A a huge problem would have occured. There would be two writers to the pipe and once process B terminated and was done writing to the pipe, the pipe would still have a "writer" and a reader. This would go on forever and is known as DEADLOCK.
What if the parent is slow and the children are really fast?
Thus, by the time the parent looks to waitpid() for the children they don't exist anymore. This is known as a Race Condition. These zombie processes are processes that have exited but thier parents haven't waited for them. Zombies aren't runnable and their memory can't be reclaimed until they are reaped by the parent by calling waitpid().