by Matthew Ball, Marc Nguyen, and Kresimir Petrinec
In this lecture, we will deal with the time delays introduced by accessing a physical hard drive. For this lecture, we will assume the following specifications:
| Capacity: | 120-300 GB | Rotational Speed: | 7200 rpm (120 Hz) |
|---|---|---|---|
| Average Latency: | 4.20 ms | Rotation Time: | 8.33 ms |
| Full-Stroke Seek1: | 21.0 ms | Track-to-Track Seek: | 2.0 ms |
| Average Read-Seek Time2: | 8.9 ms | Average Write-Seek Time3: | 10.9 ms |
| Transfer Rate (Buffer to Host): | 3 Gb/s | Transfer Rate (Buffer to Disk): | 0.97 Gb/s |
| Power Dissipation: | ~ 8 W |
Smaller blocks are more flexible, but are slower when dealing with larger chunks of data. Conversely, larger block sizes are more efficient for big chunks, but they are more prone to wasting a lot of data (e.g. storing a social security number on a 1 GB block). For now, the typical block size is 8 KiB. Therefore:
Read Time = 8192/(0.97/8 * 10^9) seek latency read Read-Seek Time = 8.9 ms + 4.20 ms + 0.07 ms = 13.2 ms (= 13.2 million CPU cycles)
To improve the apparent performance of I/O by exploiting locality of reference (the phenomenon where memory access tends to be clustered in both time and space):
For example purposes, we will use the following loop to test hard drive access times:
// In real code, would check return statuses of each operation
// Assume blocks at random
for(;;) {
char buf[8192]; // 8 KiB buffer
read(ifd, buf, sizeof buf); // read --> 13.2 ms
// With compute, want to exploit locality of reference
compute(buf); // encryption --> 1.0 ms (example)
write(ofd, buf, sizeof buf); // write --> 15.2 ms
// -------
// 29.4 ms/iteration
}
// 1/0.0294 = 34 iterations/s
// 34 * 8 = 272 KiB/s throughput
| Seek Time: | 19.8 ms |
|---|---|
| Rotational Latency: | 8.4 ms |
| Transfer: | 0.1 ms |
| Compute: | 1.0 ms |
seek latency xfer comp. write 8.9 ms + 8.33 ms + 0 + 1.0 + 15.2 = 33.3 ms
seek latency xfer comp. write 0.0 ms + 0.0 ms + 0.0 ms + 1.0 ms + 15.2 ms = 16.2 ms
As you can see, using batching and prefetching, we were able to almost double our performance!
R seek rot+xfer comp. W seek 8.9 ms + 8.33 ms + 1.0 ms + 0.0 ms = 18.23 ms
R seek rot+xfer comp. W seek 0.0 ms + 0.0 ms + 1.0 ms + 0.0 ms = 1.0 ms
R seek rot+xfer comp. W seek 0.0 ms + 0.0 ms + 1.0 ms + (10.9 ms + 8.331 ms) = 20.23 ms
As you can see, the combination of prefetching, batching, and dallying allowed us to increase our performance by a total factor of 23!
// Original version
ssize_t read(...) {
while (inb(0x1f7) & 0xC0 != 0x40)
continue;
}
// Multitasking version
ssize_t read(...) {
while (inb(0x1f7) & 0xC0 != 0x40)
schedule(); // Switches to different thread
}By allowing other threads to run while the disk is busy, we can drastically improve performance!
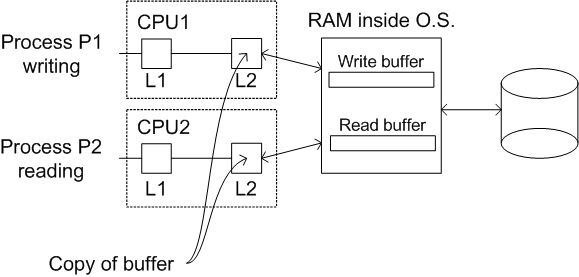
sync(); // Flushes every buffer (only schedules it)fsync(fd); // Flushes every buffer associated with that file descriptor (does it immediately, not scheduled)fdatasync(fd); // Immediately flushes fd's data buffers (doesn't care about metadata)This is not just a kernel problem!
#include <stdio.h>
getchar <-- Use a buffer
putchar <-- that lives inside app
fflush <-- please sync buffers with OSUsing flash-based memory brings some benefits and problems: