CS 111 Operating Systems Principles, Spring 2008
Lecture 15 Notes (Wednesday, May 21)
prepared by Mikal Saltveit, RyoSuke Shinoda
Performance of Disk Access (Low Level, independent of file-system)
Goals / Wants:
- High Throughput (disk I/O's per sec)
- Avoid Starvation (i.e. a bound on total latency, we want some fairness)
Simple Model:
- N blocks on disk : 0,1,2, ... , N-1
- Disk head is at block h (h is the accepted symbol for the disk head)
- Seek time from i to j is proportional to the distance |i-j| between them.
But this model =! reality. [[seek + rotational latency]] OR Virtual Memory. Really this model is closer to tape storage.
We want a /\ disk scheduler to INPUT a series of I/O requests and OUTPUT a schedule.
an online and relatively fast (relative to disk)
List of Possible Schedulers
|
|
Simplest Scheduler, FCFS (First Come First Serve)
- +No starvation
- avg seek time (assuming uniform random access to disks)
CRF (Closest Request First):
- +maximize throughput
- -starvation
SSTF (Shortest Seek Time First): opposite of FCFS
- + maximize throughput
- - starvation
SSTF + FCFS
- Break input string of requests into chunks or requests
- use SSTF within each chunk (high throughput)
- use FCFS for chunks themselves (some fairness, bound on waiting)
Elevator algorithm
- Like SSTF except you don't change the direction of the seek arm until you have to.
- Favors middle sectors visited twice as frequently
Circular Elevator Algorithm
- When you get to end of disk rewind to track 0, start over
- +fairness
- -throughput
Anticipatory scheduling
- "guess" what requests will come in, act based on these guesses. standard example: sequential access 10 requests: 1, 12, 29, 1000, 5196 ... What if after 1000 is finished it asks for 1001?
- Sometimes delay 1ms after satisfying a seq read request. (wait for next closest instructions to come). Called DALLYING. Adding this delay makes your code go faster.
- Then, go back to (1).
|
Robustness of the Disk
Suppose the power is cut?
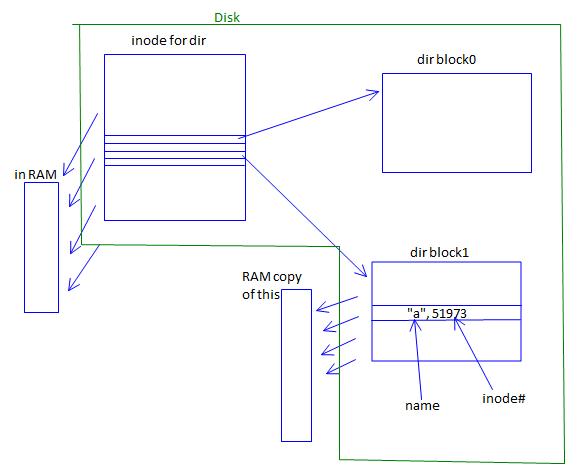
rename ("a","b")
- read directory block containing "a" entry.
- Change "a" to "b" in RAM version.
- write directory page to disk.
Power can go off anywhere in the process without crashing machine since we are assuming write is atomic operation.
Assume disk writes are atomic => write happened or it didn't. There was enough power in the capacitor to finish writing the byte.
rename ("d/a", "e/b")
- Read d's block into RAM
- read e's block into ram
- clear a's entry
- write d's block
- create b's entry
- write e's block
Power can go off without affecting disk between (1) and (3) and after (6), however, it is not allowed from (4) to (6).
Change order: write b before we delete a. End up with 2 links, link count = 1. We are still hoosed, the problem is inevitable
Programers decided this was too hard to fix, pushed problem to user with link and unlink.
- link ("d/a", "e/b")
- unlink ("d/a")
File System Invariants
- Every block is used for exactly 1 purpose: Boot, superblock, freespace bitmap, inode, datablock
- All reference blocks are initialized to data appropriate for their type
- All referenced data blocks are marked used in the bitmap
- All unreferenced blocks are marked free in the bitmap
- All link counts of inodes accurately measure the number of references to these files.
Penalty for violation of:
- Disaster
- Disaster
- Disaster
- Free space leak (wasted storage): we can violate this in small ways. Preferably temporarily.
- Linkcount too high -> wasted storage Linkcount too low -> Disaster!
FSCK(File System Check):
- At boot, it checks Free Space Leak. Standard checks.
- -Slow
To implement link ("d/a", "e/b")
2. updates directory block
1. increment link count for "d/a"
Sidebar: Zero link count?
Fstat (0, & st);
St.st_nlink == 0?
File is not reclaimed until
- 1. Link count = 0
- 2. No open file descriptors
Lower Level Robustness: IEEE terminology:
- Error - mistake made by system designer
- Fault - defect in hardware or software that may cause failure
- Failure - system behaves wrongly: user observes symptoms.
File System/etc. goals:
- Durability: system survives limited hardware failures
- Atomicity: changes are either made or not-made
- Performance: high through put, low latency
Scheduling vs Robustness
Consider following instructions:
B.Write new inode with link count
A.Write new directory entry
C.Write data1
D.Write data2
If in SSTF: execute these in this order => CBDA What if it crashes between B and D!!!
FCFS fixes this problem, but big performance hit.
Solution: tell scheduler about dependencies among writes.
It loses some throughput. Preserved important invariant.
fsync(...) <- big hammer
in unix: Metadata order is important. Data order is not.
Writes to bitmap blocks... Can there be swapped with other writes? (Yes, if you are just freeing stuff. FSCK can fix this problem).