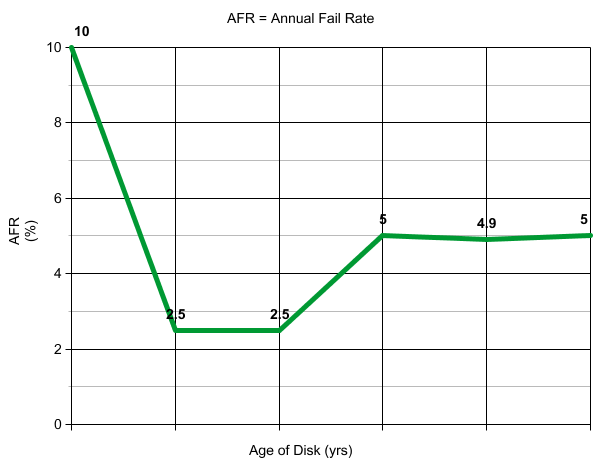
"Don't trust the system completely because it can fail"
What Can Go Wrong?
Consider a text editor's save function. How do we implement this?
open("f", O_WRONLY, ...);
write(...); write(...); write(...);
close(...);
If there is a power failure in between writes, you get a mixture of old and new versions!
Never write over your only copy!
// Write new data to a temporary file
open("/tmp/f", O_RDWR, ...);
write(...); write(...); write(...);
// Copy data from the temporary file to the intended file
open("f", O_WRONLY, ...);
read(...); write(...); read(...); write(...); read(...); write(...);
close(...);
close(...);
If the program crashes during the writes to the temporary file, then
the old data remains
unchanged.
If the program crashes after the temporary file has been written, then
we can get the
new data from the temp file
Consider: write(f, buf, 10000000)
This could not possibly be atomic! No disk write buffer is that large.
Writes to sectors (512 Bytes) are atomic
| Old | ?? Garbage ?? | New |
| Old | Old |
| ??? | Old |
| New | Old |
| New | ??? |
| New | New |
But wait! How do we know which value is correct after a crash and
reboot?
There is no tie breaker.
Answer: We can't! We need the
following:
| Old | Old | Old |
| ??? | Old | Old |
| New | Old | Old |
| New | ??? | Old |
| New | New | Old |
| New | New | ??? |
| New | New | New |
Then the fixup after a reboot is as follows:
If A==B==C then everything is correct
If A==B then copy that value to C
If B==C then backup that value to A
Else Copy A to B and C
This uses 3 times the space, but it is the best we can do if sector writes are not atomic.
Using these assumptions they built a system with two hardware sectors
for one user
sector. This is an example of a Fault Tolerant
System
User does not notice performance effect of a single failure
- Expensive
No single point of failure but performance might be affected after failure
+ Cheaper
- Not as robust
Indicate which changes are pending and then in the case of a crash,
have the fsck utility
complete those changes after reboot
If crash occures before step 3, fsck does nothing and the write never
happened.
If crash occures after step 3, fsck repeats steps 4 and 5 and the file
is written.
This approach also survives crashes during reboots.
Pre-Commit Phase
(Can back out: crashes mean nothing has happened)
Post-Commit Phase
(Transaction is done, you can also add steps to improve performance
here)
From double entry bookkeeping: never erase anything
Keep a copy of mutated data on an alternate disk
e.g.
Journal (optimized for writing)
| Begin | Change | ... | Change | Commit | End |
File System "Cell Storage" (optimized for reading)
Recovery must be idempotent: Doing an operation twice must produce the
same result
as doing it once
Cell storage could be in RAM!
Non-volatile is more common
| During Writes: | During Recovery: |
| Log your planned changes Log "commits" Install Changes |
Scan forwards through log Look for uncleared commits Execute planned changes "Roll-forward" recovery |
Write Ahead Logs work best if we're just blasting over data
| During Writes: | During Recovery: |
| Log all OLD values Install all NEW values Commit |
Scan backwards through log Look for uncommitted data Write old data back to disk "Roll-back" recovery |
Write Behind Logs work best if old values are cached anyways
For High Utilization Disks:
Redundant Array of Independent Disks
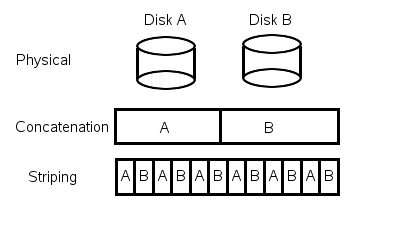
Does not avoid faults
Striping doubles throughput
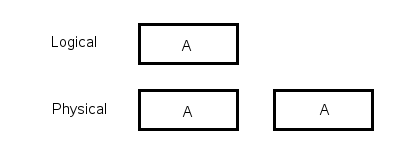
+ No Single Failure Point
- 2 Times the Cost
To Write to Disk:
Write to device 0 and to device 1
To Read from Disk
Read from device 0. If this fails, read from device 1
No fsck required.
RAID 1 Reads are faster (2 independent disk arms)
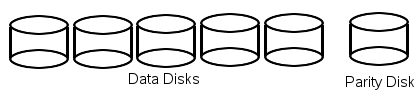
Each bit in the parity disk is the XOR of the corresponding bits from each of the data disks.
To Write to Disk: Read the old value and the parity block
Calculate the new parity value
Write the block to the data block and write the new parity to the
parity block
To Read from Disk: Read block you want.
If the block is bad, XOR all the other blocks and compare with the
parity bit to find the
old value
Failure Rate of RAID 4 = Failure Rate of a Single Drive *
(Failure Rate of a Single Drive * Mean Time To Recovery)
RAID can be done in hardware (by a controller unit) or in software (by the OS)
Hardware is better for low end systems
Software is better for high end server farms. It is more customizable
for a specific
environment and application.
Caller and Callee do not share address space (no pointer passing).
They also do not necessarily share architectures.
For example, the x86 is a little endian machine while a SPARC processor
is a big endian machine.
Thus, it is necessary to choose a standard (They chose Big Endian)
How do we efficiently convert an internal data structure into a
bytestream to go over a wire?
See next lecture!