CS 111
Scribe Notes for 6/02/08
by Tetsuya TakahashiLecture 17: Security I
Distributed RPC (Remote Procedure Call) Systems
Distributed file systems make files on one computer accessible over the network to other computers.

caller - marshal the data which is done by stubs auto generated send via network.
callee - unmarshal data act respond similarly.
| e.g) | protocol HTTP (atop TCP/IP) |
||
| request: | GET/HTTP/1.0\r\n |
||
| (over the wire) \r\n |
|||
| response: | HTTP/1.1 200 ok\r\n |
||
| content-type: text/html |
|||
| content-length: 10243 |
|||
| e.g) | X: |
||
| client: | send | DRAW | |
| send | x (in 16 bit binary) | ||
| send | y (in 16 bit binary) | ||
| send | color (32-bit #) | ||
| server: | read | x | |
| read | y | ||
| read | color | ||
| draw | pixel | ||
- RPC failure modes are different
- + callee can't trash caller's data
- - messages can get lost
- - messages can get corrupted
- - network might be down (or slow)
- - server might be down (or slow)
- Suppose we detect corruption client can respond
- If no response, what should client code do?
- how long to wait? 1ms 10ms 1s 10s?
- resend (keep trying) at least once RPC -> suitable for idempotent operations
- report failure to user at most once RPC -> suitable for transactions
- add info to queries/responses, .... exactly once RPC
RPC Performance

a) e.g. HTTP pipelining
- problems: suppose 1st request fails?
- - outstanding requests should be independent text!
- - force caller to deal with asynchronous failure.
b) cache (cache coherency ...) common answers on client.
c) prefetch answer before client code asks, then cache.
(e.g. Google maps)
Synchronous RPC
For synchronous RPC, result arrives before function returns. We see that a synchronous RPC has a significant effect on the program's performance. A solution to the performance problem is to change the protocol, either in a specific, or to use asynchronous RPC.
Asynchronous RPCFor most Remote Procedure Calls, the result arrives later, after the function returns. Asynchronous RPC do not block, so we can send next request before the result of the previous request arrives.
The problem with Asynchronous RPC is that we may not get the result that we need. The result of a call might be an error, but we don't know it at once, since the function returns immediately. It is hard to deal with programs when errors come up later. Solution to this problem requires software design to cope with delayed errors. An example of this design might be a callback function supplied by the user, which get called if there is an error.
NFS (Network File System)
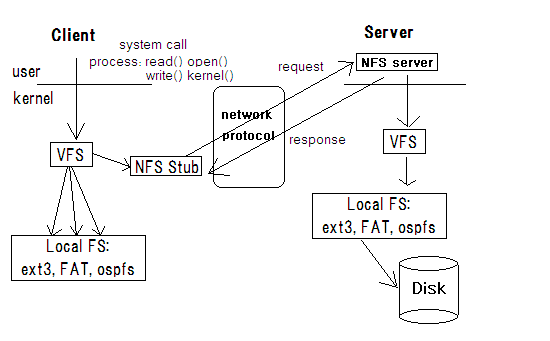
NFS -network file system- (NFS Stub) converts user-level command to RPC.
(A stub is a proxy for the remote object. )
NFS server reverses the process, converts RPC to user-level command.
Network File Systems (NFS) is a distributed system that allows a user of one computer to access files located on another computers, using regular file system calls (open(), read(), write(), kernel(), etc.) The reason for NFS is centralization of file storage for convenience and safety. The NFS server is not required to be in the kernel level. It can be a user level application.
NFS protocol
NFS is designed as a stateless protocol. So, server keeps no per-client state,
and every RPC executes atomicaly and contains all state necessary to perform RPC (that is, authentication information, file data, etc.)
This makes it immune to denial-of-service attacks. Its design must be robust. There should be no problem when client crashes or when server reboots.
There are no file descriptors; instead, there are file handles, which are 64-bit numbers identifying files (not filenames).
Below are some examples of that. ("dirfh" stands for 'directory file handle' and "name" stands for 'name of directory entry')
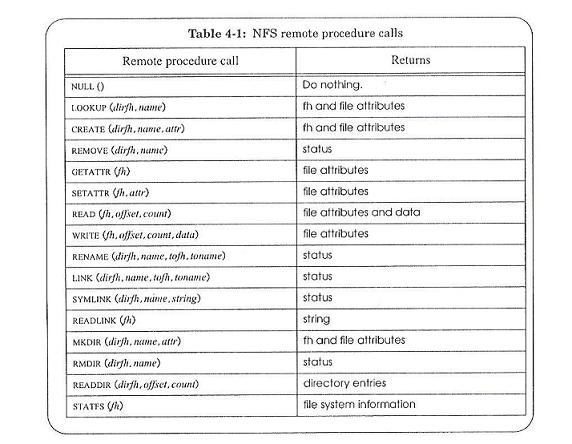
NFS file handles
- "integers" that uniquely identify a file on an NFS
- persist across reboots of the file server file system
- On Unix based NFS servers = (device# + inode# + serial#)
- implies kernel support
| scenario : client | 1 | gets a fh |
| 2 | removes the file | |
| 3 | creates a file with some inode# |
Design good:
- "stateles" server --- no important state exists only in RAM on server.
- * clients operate correctly after server reboots,
- + client "hangs" don't affect other clients or server.
- - classic NFS doesnt support read/write locks.
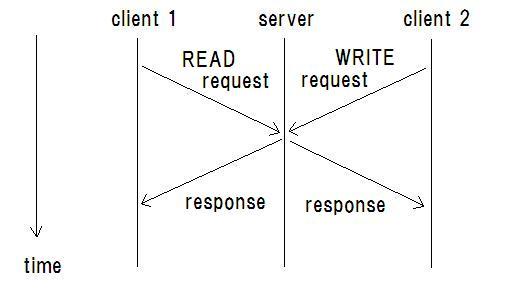
read/write consistency is not guaranteed in NFS.
open/close consistency is guaranteed in NFS.
NFS implementation on clients does pipelining + caches
Security
In real world, defends against attacks via force + fraud (most common in O.S.)
Main form of attacks are against
- Privacy (unauthorized release of information)
- Integrity (tampering with data)
- Service (denial of service)
General goals
- Disallow unauthorized access ( <- hard to test negative goals )
- Allow authorized access ( <- easiest )
- Resist DOS attacks ( <- hardest )