Scribe Notes - CS 111, Spring 08. (04/07/2008)
(Daily Scribes: Shaun Taylor, James Prompanya, Matija Abicic)
Contents |
What was wrong with out standalone program of last lecture?
- It was not portable - It couldn't be easily moved to a different computer, or even a different disk or disk controller. Magic values and assumptions about the particular hardware were hardcoded into the application.
- It was not scalable - No way to run other programs, no way to support multiple discs.
- It was not modifiable - Reuse of program parts could only be done by cut-and-paste, there was no division of systems.
- Too much of a pain to change
- No way to recover from failures
The remainder of the lecture will focus on the second and third points with the goal of modularity and scalability in mind. While this particular program was contained in a single c file, usually interfaces are contained in their own files or libraries, and header files allow apps to reuse the code. This accomplishes two goals: modularity (breaking into pieces) and abstraction (figuring out good boundaries for the pieces).
Effect of modularity on finding bugs
- Assume N lines of code (LOC) in our system
- Assume K modules
- Assume the number of bugs grows proportionally to N
- Assume that the time to find a bug grows proportionally to N
Nominal case (K = 1)
The time to find all bugs in this prorgam is proportional to Bugs * N or N²
Interesting cases (K > 1)
The time to find all bugs in this program is proportional to ((Bugs / K) * (N / K)) * K or N²/K
Flaws of the analysis
These equations make the following assumptions:
- It takes zero time to find the module that the bug is in (we always know which module it is). In practice, this is not always the case, but if programs are written with proper information, descriptive comments, and boundaries it is usually easy to tell within a module or two where a bug is.
- The bug is a byproduct of only one module. In practice, a bug can result due to an assumption of how several modules work together, so this is not an accurate picture.
It is also easy to note that, according to this equation, if one were to create an infinitely large amount of modules, we would reduce the amount of time it would take to find a bug to zero. Of course, in the real world, creating an infinitely large amount of modules would have the opposite effect: a module per line, for example, is essentially not having any modules at all.
Still, the equations are close enough to hold true, and are used here only to prove a point.
Effect of modularity on the whole system
Modularity can be bad or good, and usually has both effects on a program.
- Performance - Modularity typically hurts performance a bit. The goal with proper modularity is to minimize this bit (typcially acceptible values are <10% or sometimes <5%).
+ Robustness - Tolerance of faults and errors. Modularity usually helps this a bit by isolating systems so that bugs don't propagate as far in the system.
+ Lack of Assumptions - Lack of assumptions as related to hardware or other code.
+ Flexible/Neutral/Portable/Interchangeable - Flexibility is particularly helpful when combining with abstraction.
+ Simplicity - Easy to learn, short manual, easy to use.
A sample of increasing modularity using the read_ide_sector function
void read_ide_sector(int secno, int addr);
First off, what's wrong with the function? The void return shows that this function assumes the read always works. There is no way to communicate a failure to the calling function. Second, "read_ide_sector" is too specific. It assumes we are on an ide disk, when there are several other types of storage. Third, the data types do not work on all modern computers. Many modern computers use 64bit addressing schemes which is too large for "int a" to hold. Also, with a sector assumed to be 2^9 (512) bytes, an integer sector number only allows addressing for approximately 1 TB of data on a disk.
int read_sector(off_t secno, char *addr);
This is a much better improvement. It allows for 64bit addresses, larger disks, and gives a return code that lets the caller know an error has occured if something goes wrong. However, it still assumes that we want to read a single 512 byte sector.
int read_sector(off_t secno, char *addr, size_t size);
With the addition of the "size_t size" parameter, we have a way of telling the function what size the sector should be. However, with this introduction we have to worry about what to do when the function is passed a sector size that doesn't actually match the physical sector size on the disk.
int read(off_t byte_offset, char *addr, size_t size);
This revision does away altogether with the notion of a sector and instead exposes the ability to address any byte on the disc arbitrarily. However, it still assumes that there is only one drive on the system!
int read(int fd, off_t byte_offset, char *addr, size_t size);
This function is much better. It makes no assumptions on the disk we want, the size of the file to read, or the physical attributes of the disk we are reading off of. However, there are several ways that this function can fail. What should it do if the size we pass to it is not available on the disk (aka trying to read 400 bytes when we are 200 bytes from the end of the disk)? How should we handle eof, etc? This makes the function more complicated for the caller as the caller has to worry about all these failure modes.
size_t read(int fd, off_t byte_offset, char *addr, size_t size);
This function changes the return type so that we can return the number of bytes returned. It however introduces the problem of portmanteau variables (variables with more than one meaning depending on value) which is generally considered bad practice. Nonnegative integers represent how many bytes read, and negative integers indicate an error has occurred.
At this point, what if the caller wants to read sequentially always starting at the offset that was left off on before? Let's get rid of the "off_t byte_offset" parameter.
size_t read(int fd, char *addr, size_t size);
off_t seek(int fd, off_t byte_offset, int flag);
The seek function allows someone to still do random reads, while making it easier to read sequentially for the majority of tasks that require so. It returns the same style of portmanteau variable, where positive indicates the new position, and negative indicates an error. The flag variable allows us to do one of three things:
-
SEEK_SET = 0- Seek to the byte_offset from the beginning of the disk. -
SEEK_CUR = 1- Seek to the byte_offset from the current location on disk. -
SEEK_END = 2- Seek to the byte_offset from the end of the disk (the byte_offset is usually negative here).
What have we ended up creating? These are Linux/Unix/POSIX primitives!
(Note: the seek function is actually called the lseek for historical reasons.)
Advantages of lseek + read versus read(...off_t byte_offset...)
+ Sequential reads are easier to program. + Reads work with non-seekable devices (keyboard, network, etc). + We've effectively simplified other operations such as write as well.
Two things about linux primitives
- Abstraction (mentioned) - View of the underlying system that is simpler than the underlying system. The system is restricted (ie. virtualized) from the perspective of the calling program.
- Virtualization - Building a higher level interface out of a lower level one, and not giving the programmer the ability to do everything the lower level can do (ie. restricting bad operations).
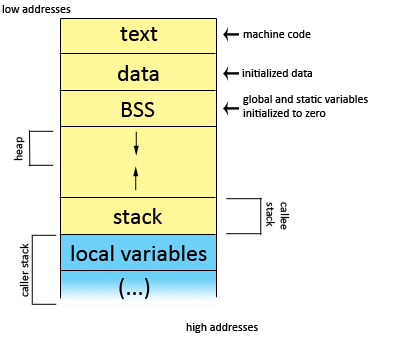
How to do virtualization in a reasonable way
0. The easiest way is to not do it. Basically, lots of globals, one main program. The advantage to this method is speed. The disadvantage to this method is that it is hard to debug and understand.
1. Function calling - Library functions (from the BIOS, OS, other libraries like the c standard library, etc). This implies the use of the stack to hold local variables.
Sample function calling method
Take, for instance, this simple recursive function that calculates a factorial:
int fact(int n) {
if(n == 0)
return 1;
else
return fact(n-1) * n;
}
To compile this properly, you need to make sure that you disable all levels of optimization by including -O0 in the compile flags. If you compile with level 2 optimization (-O2, default) the compiler will smartly change this into a simple loop instead of recursion. The correct way to compile is gcc -S -O0 fact.c
The assembly language for the function is shown below:
fact:
pushl %ebp Save frame pointer (fp)
movl $1, %eax Get ready to return 1
movl %esp, %ebp Establish our new fp
subl $8, %esp Create our new frame
movl %ebx, -4(%ebp) Save ebx to the stack
movl 8(%ebp), %ebx ebx = n
testl %ebx, %ebx n = 0?
jne .L5 Recursive case
.L1:
movl -4(%ebp0, %ebx Restore ebx
movl %ebp, %esp Restore stack pointer
popl %ebp Restore frame pointer
ret Return to calling function (restore instruction pointer)
.L5:
leal -1(%ebx),%eax eax = ebx - 1
movl %eax, (%esp) store n-1 as argument for inner function
call fact push return address, jump to fact
imul %eax, (%esp) (n - 1) * n
jmp .L1
To call this function properly, you would set up like such:
pushl %3 fact(3)
call fact call the factorial function
addl $4, %esp pop argument off stack
The result of the function is now in eax.
Stack issues
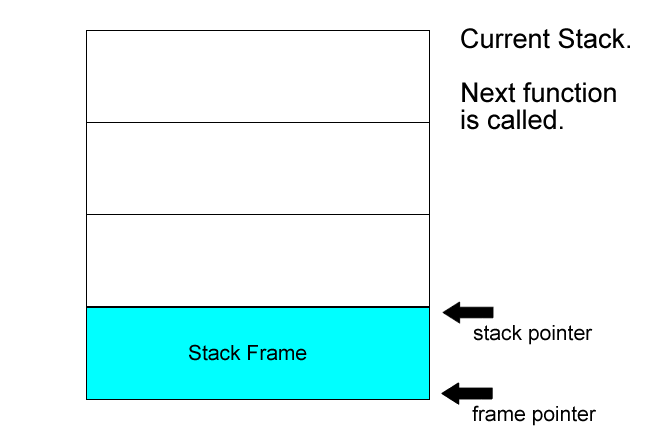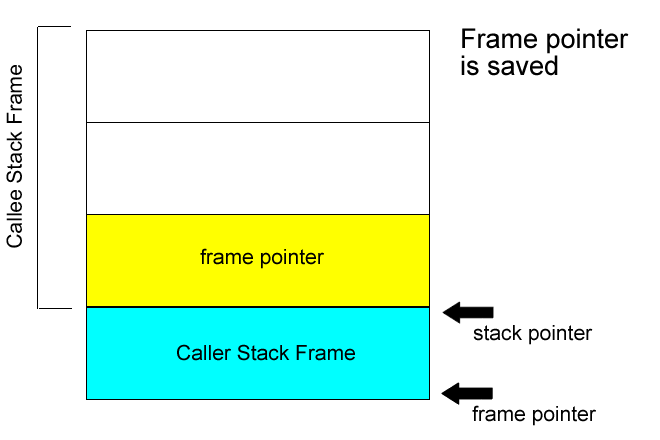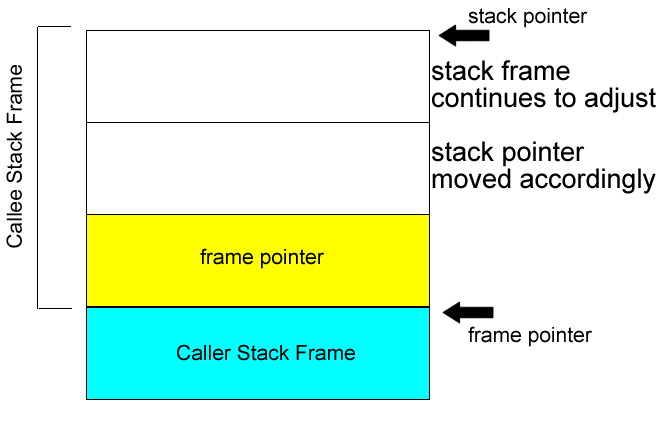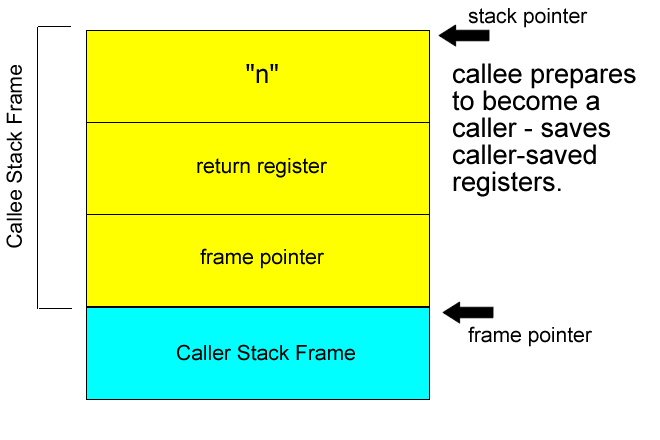
Note: in the x86, %ebp register holds the stack pointer, while the %esp holds the frame pointer. Regardless of the current frame, one can modify another's stack frame by using incorrect offsets.