The flash drive is an electronic device with no rotation or moving parts. There are two types of flash drives: NOR and NAND. The NOR drive is an older, more mature, and cheaper type. It is faster at reading data. The NAND flash drive is newer and has bigger capacity. It is faster at writing data.
Flash drives can only change 1 bits, but not 0 bits. It takes the AND operation of what is being written and what is already on the drive. In addition, an erase changes all bits on a block to 1, which is really slow. For NOR drives, the erase operation takes seconds. It takes 100,000 erases on a block for a NOR drive to wear out. For NAND drives, an erase can take milliseconds and the drive wears out after 1,000,000 erases. After 1,000 reads, the data on that block on a NAND drive will be lost. However, if you do 999 reads on a block and then perform a write, then that block is good for another 1000 reads before the data is lost.
Flash drives will always have bad blocks, which are damaged sectors. The drive will still work, but the bad blocks just are not in use.
| Sun 32GB NAND Flash Drive | Sun 1TB 7200RPM SATA Hard Drive |
| $960 | $660 |
| Read: 35,000 IOPS | Random: 80 IOPS |
| Write 3,300 IOPS | |
| Random 4kb | Capacity: 30x Speed: 30x slower |
| 2.5W (max) | |
| 2.1W (typical) | |
| 0.1W (sleep) | |
| MTBF: 2 million hours (assuming 7*24*3years) | |
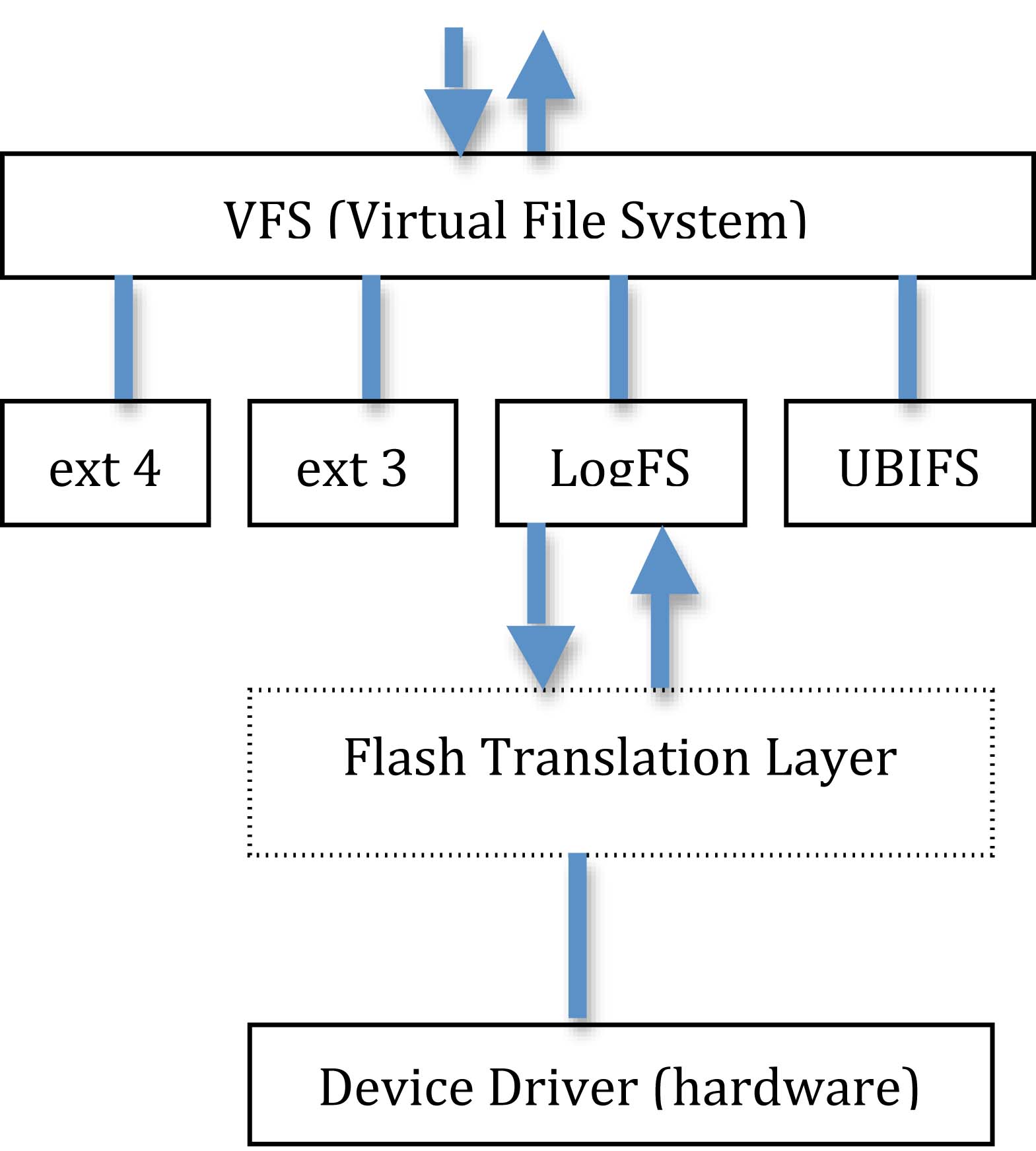
Flash Translation Layer: It is a block manager of a larger array, consisting of garbage collector. Implements a wear leveling algorithm that prevents hammaring on a same block. For example, if the block 57 was already written, then it will write to another block instead. This is all done in the hardware level.
[x][x][?][?][x][?][x][?][?]
[x] - block is in use
[?] - unused block
Garbage Collector: The garbage collector will leave the [?] alone in normal file system. However, in flash file systems, the garbage collector will erase the unused blocks in the background.
If the user is paranoid about the garbage collector in the FTL, which is hardware, there is the UBIFS, which is implemented in software, that communicates with the device driver directly. However, it does take up bit of the CPU.
Batching is reading x sectors at a time, where x can be any number such as 1, 8, 16, or even 1,000,000. Reading 1,000,000 sectors at a time can have great performance. However, it lends itself to internal fragmentation and external latency because we often do not read that many sectors. To fix this problem, we can read variable size blocks; different sizes for different operations, which leads to complexity. Therefore, we usually read 8 or 16 sectors at a time, which solves the complexity of reading variable size blocks.
Prefetching: The process of guessing what blocks the application will need next and fetching that block before the application asks for it. The prefetched blocks are put into the cache. This only works well for sequential reads.
Speculation: When the hardware guesses where the next read is. This is implemented at the instruction level.
Dallying: Dallying waits for more requests before it starts writing. Then, it starts writing everything together. Unfortunately, this might lead to data loss. Data loss can result from power failure when all the data to be written is still in the cache, which is permanently loss during power failure.
In order to prevent data loss, we give the application a way to tell the operating system not to dally by flushing out all cached data onto the disk.
Consider the following sample code:
1 for( int i=0, i < N, i++ )
2 {
3 read(fd, buf, 8192); // drive 1
4 compute();
5 write(fd, buf, 8192); // drive 2
6 }
Consider T threads each running the sample code above and T input drives and T output drives, all running in parallel at full speed. This keeps the CPU busy so that no CPU processing time is wasted.
The disk is a scarce resource. Scheduling is the process of allocating the disk head to accommodate the input/output requests.
assume cost of seeking from i to j is |i-j|