Computer Science 111, Spring 2010
Lecture 10, File System: Performance 5/4/10
By: David Chan, Zev Solomon.
- File system: A set of blocks on disk that represent the Unix file hierarchy
- Will usually cause us to change our design to improve performance
- Most commercial file system data resides on disks (hard disk)
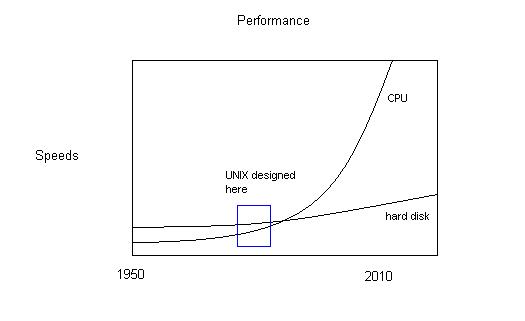
- Speeds aren't increasing as fast as CPU speeds are increasing (not exponential)
- Unix was designed when disk speed was greater than CPU speed
- Design attributes different today because CPU speed > disk speed => obsolete
- The need for a new file system is orthogonal to the need for a new kernel
Why Disks are Slow
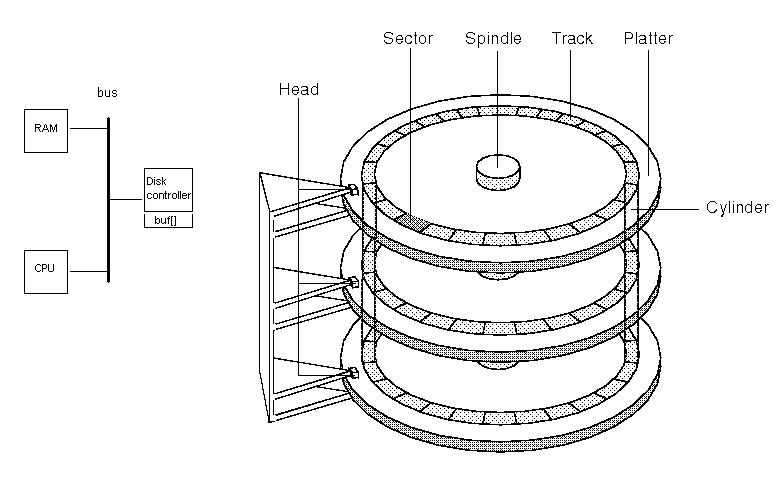
- Built out of multiple platters rotating around a single spindle
- The problem is that the disks rotate around at 120Hz (7200rpm)
- Steps to do a read:
- Accelerate heads towards where the sector will be
- Decelerate heads, settle them over the correct track <-- Seek
- Wait for the sector to be under the heads
- Constant speed. Takes a long time to speed up the disk, but we don't slow it down because it would take too long to speed back up.
- Read the data as it goes under the head
- Copies the data into the disk buffer which sits on the hard drive itself
- CPU will read the disk buffer into RAM
- Transfer data to main memory
- Most hard drive failures are due to hardware failure because of excessive heat
- Humdrum Drive Numbers:
- Seagate Barracuda ES2 1TB
- 16 MiB cache
- 7200rpm = 120 Hz (8.333 ms to do a full rotation. Slowwwwwwwwwwwww)
- 8.5ms for avg read seek, 9.5 ms for avg write seek (4.2 ms rotational)
- 1.2 million hours MTBF (mean time b/t failure)
- 0.8ms Track to track read seek
- 1.0ms track to track write seek
- ? 20ms full stroke seek
- 1287 Mb/s maximum internal xfer rate
- 116 MB/s maximum sustained xfer rate
- 3 Gb/s external transfer rate
- Bytes/sector 512, 520, 524, 528 (configurable)
- 12.5W typical
- 9.0W idle --> most of the power goes into just spinning the disks
- 0.73% AFR(24x7) --> Annualized failure rate (disagrees with MTBF a lot)
- 10^-15 non-recoverable sector read failure rate
Suppose we want to run this code:
For (;;) {
char c;
if (read(fd, &c, 1) <= 0)
break;
process(c)
}
It takes this long:
8.5 ms seek
4.2 ms rotational
.004ms xfer
It takes us 12.7ms per character
8.4 ms avg (2x rotational, because the disk has to make another full rotation, no seek time)
We run this for ~120 characters/sec (REALLY SLOWWWWWWWWWpoke)
How do we make this faster?
Batching
- Prefetching: get data from the disk before the application asks for it because we are guessing that it is going to be needed
- It is not always a win because if you guess wrong, the application will need to wait a long time for more data
- Suppose the disk changes after you fetch?
- Cache Coherency
- One solution: require all I/O to go through the cache
- Read whole sector, keep for next time
- 511 of 512 reads .001 ms = .5
- 1 of 512 read 8.3 ms
- Total 8.8 ms to read the sector (512 chars)
- ~0.017 ms/char (60,000 chars/sec)
Bigger Batches
- How about we read all of the disk into ram?
- We don't have that much do we…
- 116 MB/s sustained xfer rate
- 1 track batch = ~1 MB (166 * .00833)
- To process 1 MB:
- 8.4 ms to transfer
- 0.8 track to track seek
- 8.4 + 4.2 + 1000 = 1012.6 ~= 1 MB/sec
- This is fast enough so that we are now CPU bound
- We can now shrink our batch to save memory if we choose to
Will this trick work for writing too?
- Prefetching works for reading, but we can't prefetch for writes
- Dallying
- The idea: update the cache but don't actually update the disk immediately
- The problem: the cache is still volatile so if there's a power failure, we will have issues.(Will touch on when dealing with Robustness)
Our implementation of prefetching made an assumption:
Locality of Reference
- Two nearby in time accesses probably access nearby inspace blocks
Speculation
- The operating system guesses what the application will do in the future
- Does extra work first to improve performance
Emacs Problem:
- When you do a write(), the bytes might still not be on disk
- Once you close, they might just be cached
- To get around this, new system calls:
sync(); //schedule entire cache to be written
fsync(fd); //all of data and metadata for file sent to disk (The problem is that it is slow)
fdatasync(fd); //Only the data
Multitasking
Performance Metrics for I/O
- Utilization: fraction of system that's doing useful work %
- Throughput: rate of request completion (I/Os / s)
- Latency: delay from request to response (ms)
Example Strategies + metric
Method |
Latency |
Throughput |
Utilization |
Polling |
100 μs |
10 KB/s |
5% |
Batching |
1000 μs |
21 KB/s |
10% |
Interrupts |
100 μs |
18 KB/s |
9% |
DMA + interrupts |
56 μs |
167 KB/s |
45% |
DMA + polling |
50 μs |
180 KB/s |
85% |
