LECTURE 15: Thursday, Week 8
Scribe Noters:
Tanya Gillis
Stefan Vainberg
Yahya Fahimuddin
Better page replacement policy
- if it's good enough, then Belody's Anomaly should never occur
What is the optimal page replacement policy?
Ex. ref string: 0 1 2 3 0 1 4 0 1 2 3 4
| A |
f0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
f2 |
2 |
2 |
| B |
|
f1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
f3 |
3 |
| C |
|
|
f2 |
f3 |
3 |
3 |
f4 |
4 |
4 |
4 |
4 |
4 |
Total: 7 faults
- look into the future to find the page you don't need for the longest time- that page will fault
- is there an approimation to the next page fault?
Least recently used:
- if a page has been used a lot, it probably will be used more
- LRU assumes temporal locality of reference
- accessing page i @ time t -> high probabilty of accessing page i at times: t+1, t+2, t+3...
Ex. using LRU on the previous example:
ref string: 0 1 2 3 0 1 4 0 1 2 3 4
| A |
f0 |
0 |
0 |
f3 |
3 |
3 |
3 |
3 |
f4 |
4 |
f2 |
2 |
| B |
|
f1 |
1 |
1 |
f0 |
0 |
0 |
0 |
0 |
0 |
f3 |
3 |
| C |
|
|
f2 |
2 |
2 |
f1 |
1 |
1 |
1 |
1 |
1 |
f4 |
Total: 10 faults
How to implement LRU:
A)
- Mark all PTE's as pointing to inaccessible pages
- a page fault on every access
- kernel stores timestamps for that page. will this work?
- it will be slow and have loops!
B)
*p = syscall load(p)
load tells content of location
*p =v, syscall store(p,v)
- clock interrupt (every 10ms, or so)
- how about:
-> have hardware update PTE on each access
Optimizations for paging:
Demand paging:
- load just 1 page of program into RAM
- mark other PTEs as inaccessible
- run!
+ program starts faster
vs
load 1st N pages at once, where N is the number of pages in the program that fit.
+ better batching
vs
Dirty Bit Optimization:
code inside kernel to do paging:
void pfault(int va, )
{
if (swapmap (va, current) == FaIL)
kill (current, SIGSEGV)
else {
(p,va)=removal_policy()
pa = p_pmap(va)
write pa to disk at swapmap(va',p)
read pa from disk_swapmap
current -> p_pmap(v)=pa
}
}
int swapmap(va,p)
{
return disk address for va
or
FAIL
}
- Assume no thrashing
- U = # of pages used. 1 <= U <= N
- C = cost of reading a page
- demand paging, startup cost
- demand F+C
- w/o demand NC
- program cost = U(F+C) if U
- program cost = NC if U == N
When can we skip dirty bit test?
- if the page hasn't changed
- hardware support for dirty bit
- whenever you store into page, set dirty bit to 1 if it's not 1 already
- more commonly implemented
- we can do this in the kernel (if no hardware support)
- mark pages as read-only at first
- set own dirty bit as needed on page faults & mark page read-write
- some pages are naturally read-only
- this can be shared between parent and child
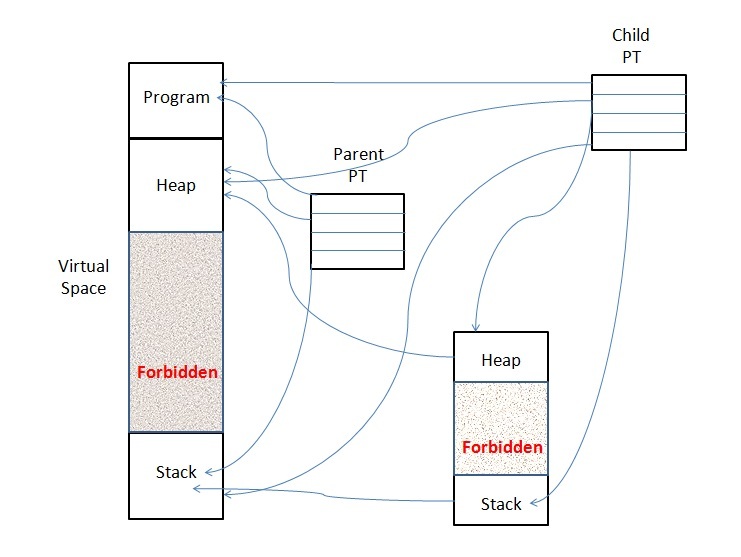
- child+parent share page table. parent is frozen until child execvp() or _exit(). child must not mess with RAM in any way that will mess up the parent
Distributed Systems + RPC:
so far: modularity via virtualization
now: modularity via message passing:

implement message passing atop conventional virtual kernel
also do it by having multiple machines
+ flexibility
- performance
simple message-passing model
Remote Procedure Call:
- requester executes a procedure call.
- response = p(request) like a syscall in that body is executed elsewhere
Properties of RPC:
- caller & callee don't share address space
- - noall by reference: call by value only
- caller & callee need not share machine architecture x86 caller, space callee
- - no shipping machine code
caller args, callee results
marshalling- taking a structure and converting it to sequence of bytes (efficient, not bloated, easy to generate, easy to parse)
callee args, caller results
unmarshalling- reverse
what you want (as a programmer) is an API
Ex.
r = arctan(x,y)
double arctan(double, double);
50 lines of code
Programs can take API and generate stubs
Examples of RPC:
 RPC failure modes:
RPC failure modes:
- message can get lost
- " " duplicated
- " " delivered out of order
- network might be down/slow
- server might be " "
- messages can be corrupted (checksum + report error)
Solutions:
- message is lost:
- -> resend, keep trying until you get resp.
- -> return an error at most once RPC
exactly once RPC is not doable