CS 111: Operating Systems Principles
Lecture 19: Scheduling
By Li-yang Ku and Edison ChauWhat problems does scheduling address?
- limited resources
- too many users/processes/etc (we will use processes as the example for the purposes of this document)
Consider the following analogy: there is a really popular club that people want to enter. People inside the club would be the processes that are currently running, while the people waiting in line outside the club would be the processes waiting to get their turn to run. The bouncer at the entrance to the club would be the scheduler.
How do we determine which processes get to run, and which ones sleep?
Levels of Scheduling
There are multiple levels of scheduling, each of which consider different factors:- Long term scheduling - Consider factors which will come into play in the long term with regards to scheduling. For example, for this level of scheduling, a factor that must be considered would be which processes are admitted into a system. When it comes to scheduling, not only are there limited resources for accommodating running processes, there are also limited resources for accommodating waiting processes. In our club analogy, if people wait outside the club on a sidewalk, the sidewalk can only hold so many people; if the line gets long enough, the sidewalk will eventually fill up, and there would no longer be room for more people to get in line. This is an example of what long term scheduling considers.
- Medium term scheduling - When considering scheduling in the medium term, one must consider factors such as which processes reside in RAM, and which processes reside in disk. Those that reside in RAM are eminently runnable, while those that reside in disk take much more time to run. Deciding which processes are which is integral to medium term scheduling, since the decision affects how each process runs.
- Short term scheduling - A short term scheduling factor would be which processes get a CPU. This is considered short term, as it determines which processes get to run and has the most immediate effect out of the examples presented in any of the other levels.
Scheduling Methods
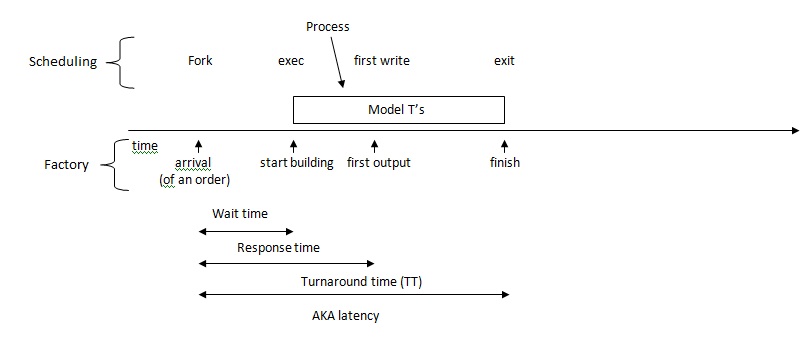
When coming up with scheduling methods, it is important to keep them simple and easily understood. It is also important to have them be intuitive to how certain people want or expect the scheduling methods to behave, so that they will be more likely to be useful to people than otherwise. Of course, being intuitive also makes it easier to understand.Scheduling existed long before computers did, and one of the places where it could be applied is in a factor. Let us consider a factory as an analogy for the purposes of learning scheduling methods. A car factory will produce cars upon receiving an order for them. However, even after receiving an order for a certain number of cars to be produced, the factory cannot begin production immediately - the factory must procure materials, rally their employees, and other such managerial tasks. After everything is in order, production of the cars will begin, and a certain time after that, the first of the cars will be produced. From then on, production will continue until the amount requested by the order is produced. When it comes to scheduling, the arrival of an order is (loosely) analogous to a fork system call of a process, as a process forks when it needs some work to be done (the order). The start of production for scheduling is like the exec call in processes, as once the exec call finishes, the child process will begin doing the work delegated to it by the parent. The first produced car is like the first write done by the child process, since that is the first useful output of the child. After that, the child will continue to do work until its task is finished and it exits, like production in the factory. In scheduling certain time periods are important to keep track of and inspect, as they are used as the metrics by which scheduling methods are judged. The time between the arrival of an order (the fork) and the start of production (the exec) is called the wait time. The time between the arrival and the first produced car (first write) is known as the response time, and the time from the arrival to the finish is the turnaround time.
Aggregate statistics:
Utilization: Percentage of CPU time spent doing useful work.
Throughput: rate of useful work being done (sum of runtime/total time).
Goals of Scheduling: To maximize utilization and throughput and to minimize wait, response, and turnaround times.
Problem: Often times the two goals above can conflict with each other!
Simple Scheduler
First Come First Served - Processes that are first get to run and finish before the others.

Each letter in the above diagram represents one second of run time. "||" represents a context switch between processes, and takes time δ.
| Jobs |
Arrival Time (seconds) |
Run Time (seconds) |
Wait Time (seconds) |
| A |
0 |
5 |
0 + δ |
| B |
1 |
2 |
4 + 2δ |
| C |
2 |
9 |
5 + 3δ |
| D |
3 |
4 |
13 + 4δ |
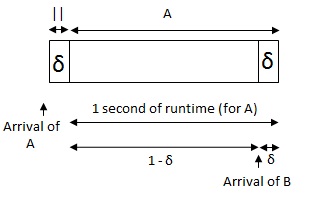
Utilization: It is almost equal to 1(20/(20+4δ)).
Average Wait time: 5.5 + 2.5δ.
Average turnaround time: 10.5 + 2.5δ.
Shortest Job First - Shortest jobs get priority over longer ones (This is based on the assumption that you know the job length of each job).

Utilization: The same as in FCFS, since things have only been reorganized, but no additional tasks (such as additional context switches) have been added.
| Wait Time (seconds) |
|
| A |
0 + δ |
| B |
4 + 2δ |
| C |
9 + 4δ |
| D |
4 + 3δ |
| Average |
4.25 + 2.5δ |
The average wait time improves for the SJF scheduling method, as can be seen above.
Since the average wait time has improved, but the utilization remains the same (as does turnaround time, which is not shown here), why not use the SJF scheduling algorithm all the time?
Answer: Fairness. SJF is not as fair as FCFS. This can have adverse effects, such as starvation. For example, if there is a very large job waiting to run, but a constant stream of small jobs keep coming into the system, then those small jobs take priority over the large one, and assuming a new small job comes in before the previous one finishes, the large job will never get a chance to execute. This is what we call starvation.
Preemption
Preemption in scheduling is when the system checks if conditions for scheduling have changed in the middle of running a process, and if they have, then a new process will be chosen to run based on these conditions.Let's look at an example of SJF with preemption.
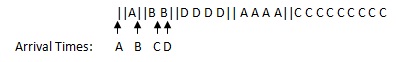
Average wait time: (δ + 2δ + (9 + 5δ) + 3δ)/4 = 2.25 + 2.75δ
The average wait time has decreased significantly, since wait time only factors in the time between when a process arrives, and when it begins to run, so the wait time for processes B and D have decreased. The fact that A was preempted and must wait for processes B and D to run and finish before continuing is not accounted for in wait time.
This time that A had to wait for B and D does come into play for turnaround time.
Average turnaround time: (2.25 + 2.75δ + 5 + (6 + 3δ))/4
Even with preemption, SJF still has the problem of fairness and starvation.
How about FCFS with preemption?
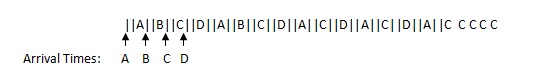
This scheduling algorithm is also known as round robin (RR).
Average wait time: (δ + 2δ + 3δ + 4δ)/4 = 2.5δ
This algorithm has the shortest average wait time by far, but there is a fairly obvious trade-off that can be observed.
Average turnaround time: ((15+ 15δ) + (5 + 6δ) + (18 + 16δ) + (11 + 14δ))/4 = 12.25 + 12.75δ
At the cost of decreasing wait time, we have increased our average turnaround by a significant margin.
Can a process starve in a FCFS with preemption scheduling algorithm?
Yes, it can. Consider the following scenario: A large job starts running, as per the round robin algorithm. After this large job has had a turn to run for some elapsed time, a new, short job comes in. When the short job comes in, the system thinks "Oh, well the large job already had a chance to run, so let's have the new job get a chance now." So the short job will run and we assume that the job is short enough to finish before being preempted (even though this scenario would still be valid without this assumption). Then, before the short job finishes, another short job comes in, and this cycle repeats indefinitely. Then, the large job will keep waiting forever, and starve. The solution to this problem would be to put new jobs at the end of the queue even if the current jobs have already had a turn to run.
Wait a second...considering that solution, wouldn't the above example of round robin be buggy? Since job A was running already, and job B just came in, shouldn't job B be placed at the end of queue, so job A would continue to run? The answer is yes, the above example is buggy. The fix to this bug is beyond the scope of this document.
Priorities
Priorities can be another method of scheduling. Processes are given priority values, either set by the user or by the system, and processes would be selected to run based on these priorities. In real time applications, priorities are typically set by the user. Examples of priority values would be how in the FCFS algorithm, the priority for a process is the negative value of its arrival time, while for SJF, priority is determined by the negative value of its run time.Real time scheduling
Real time scheduling deals with constraints that must be met, or else there will be consequences.
- Hard real time scheduling - The type of real time scheduling where the consequences to missing the constraints are disasterous. Examples of such types of scheduling would be brakes (if the brakes take too long to take effect, the car could crash), and nuclear reactors (example constraint would be dropping the rods on time; consequences are self-explanatory).
- Soft real time scheduling - The type of real time scheduling where the consequences of missing the constraints are minimal. As a result, if the deadline (constraint) is missed, the task is dropped. For example, in video streaming, if a frame cannot be prepared on time to display on the screen when it is supposed to, then skip the frame and go to the next. Soft real time often makes use of giving priority to the earliest meetable deadline first, since deadlines that cannot be met are dropped, so only meetable ones should considered. A rate-monotonic scheduling approach can also be applied here, where resources are basically split evenly between processes that desire them. For example, if you have 10 screens that are showing video, you divide the total frames you can output by 10, and give each screen one-tenth of the total frames. The screens will have poor performance, but each screen will have equally poor performance
The mars rover (real time)
3 priorities - low, medium, high
We have 1 process of each priority:
| Low Priority |
Medium Priority |
High Priority |
| lock(&m) |
||
| run (short runtime) |
Starts running |
lock(&m) |
| unlock(&m) |
Random code |
In the above table, the low priority process grabs a lock on a mutex so that it can do work. After the low priority process grabs the lock, the high priority one wants the lock, so it will have to wait for the low one to release it. However, while the low priority process is doing its work, a medium priority process starts up, and since it has priority over the low process, it will run instead of the low priority process, and continue running. As a result, the high priority process essentially ends up not being able to run, even though it is higher priority than the currently running process.
This phenomenon is what's known as priority inversion, and it caused us to lose the mars rover in question. The way to get around priority inversion is when a situation arises when a higher priority process is waiting on a lower priority process (due to something like a lock, in this example), the higher priority process will lend its priority to the lower priority process. In this example, the low priority process would borrow high priority and get to run instead of the medium priority process, and eventually release the mutex m so that the high priority process could then run.
More Scheduling
1CPU – What we talk about before.
1Disk – Many I/O requests, which to do first?
What is different from CPU scheduling? Context switch is expensive: seek + rotation latency
Simple abstraction of a Disk:
Instead of calculating the exact cost of rotating the disk and switching the head assume the disk is a long array.

Cost to access = | I - h| = |Desire location – head location|
Different kinds of disk schedulers:
FCFS |
– lots of seeking |
SSTF |
+ minimizes seek time |
FCFS + SSTF |
batches ( FCFS) + within a batch ( SSTF) |
Elevator scheduling |
SSTF in the same direction to the end |
Cycle elevator scheduling |
SSTF in positive direction |
Anticipatory scheduling |
Minimize seeks by guessing future requests |
Cloud Computation Intro
Cloud computation: A cargo full of computers. Operate all the computers at the same place to achieve economics of scale. Sometimes uses warehouse, but cargo is the most common.
Advantages:
| Large shared resources: | economics of scale |
| Customer's advantage: | short term commitment |
Problems/issues:
| Payment | OS must meter activities in a way that both customer and supplier trust | ||
| Resource Management | |||
| Security | Data confidentiality | Standard techniques: Encrypted connection to cloud Encrypt all files in the cloud |
This is all about TRUST. "Reflection on trusting trust" |
| Software licensing | A lot of computer needs a lot of licensing | ||
| Data transfer bottlenecks | CPU almost free, most time is spend on finding data. | ||
| Vendor lock-in | |||