Spring 2010 CS 111 Lecture 3
Scribe: Torrey Umland
Introduction:
During the previous lecture we saw an example of running programs without use of an Operating System (OS). However, this approach had problems.
Problems with standalone applications:
1. Unnecessary duplication - Read_sector has multiple copies in MBR, VBR, application, and BIOS.
These 4 copies may or may not be identical.
There are performance and maintenance concerns because more memory must be occupied by each copy of the code, and each copy must be individually maintained.
Possible solution : Keep the BIOS copy, throw away the others, publish to applications
BIOS stands for Basic Input Output System
The Master Boot Record (MBR) is still there but uses BIOS read_sector function.
+ 1 copy of the code, 1 maintainer
+ standardized ( all devices use the same code)
- Inflexible (old code might be terrible for modern disks)
- Unportable ( BIOS tailors to only that system)
2. Read bus-contention overlap – happens with the insl instruction
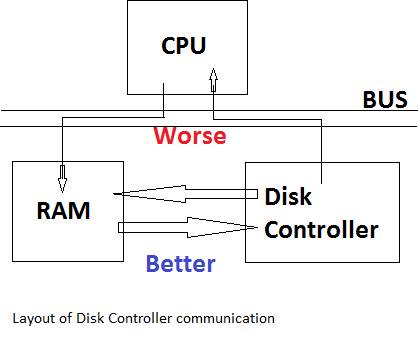
The insl instruction copies bytes off of the Disk Controller to the CPU, and copies from the CPU into RAM
Solution: copy directly into RAM
+ CPU is freed up allowing more parallelism
This technique is called Direct Memory Access (DMA)
Commands are sent directly to the Disk Controller to do the copying on its own.
This is more complex, but faster, and has less bus-contention
But, because of problem 1, we have to modify all 4 copies to use DMA….
3. Lack of parallelism
Our program does a series of reads and word counting. The initial approach is slow, the program reads some input, then counts the words, then reads some more etc.
The cost of counting is small, but not so for reading.
Also, if we were doing something expensive like cryptographic hashing, the cost would be larger.
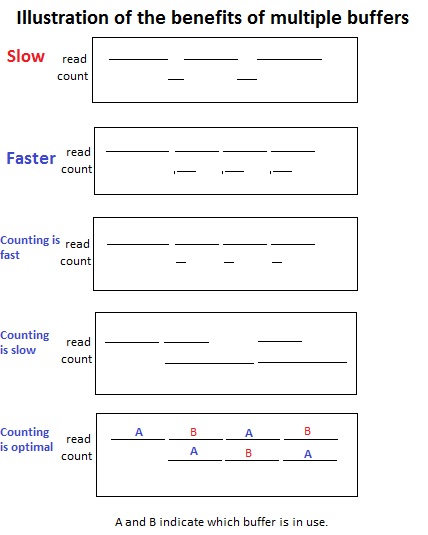
Solution: count while reading.
This requires multiple (2) buffers. Which in turn requires double the buffer space, a reasonable tradeoff because typically we have memory to burn.
This approach is faster regardless of the count/read speed.
illustrate the differences
The most performance increase comes from equal counting and reading times. The performance is doubled in this case.
To illustrate the use of 2 buffers observe buffers A and B and how their roles are alternated.
4. The biggest problem caused by the maintenance “pain” a single application
-pain to change (change multiple copies or change BIOS, which is a big deal)
Or we have to make it unportable, or take a survey of devices running it to ensure that we support all possible platforms
-pain to reuse parts in other programs ( both copies need to be maintained)
-pain to run several programs at once (all running programs become more complex)
-pain to recover from failures (Eggert’s code given in the last lecture ignores errors)
The problem #4 shows that our fundamental design is wrong, and we need a way of attacking this stuff.
1st 2 reasons relate to coping with complexity, and there are 2 strategies for this:
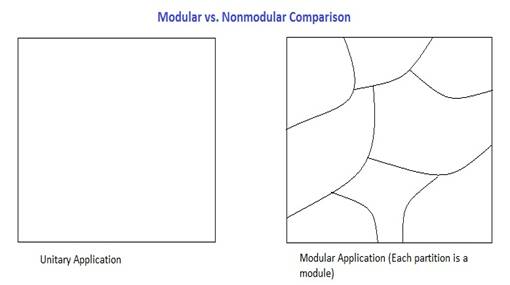
1) Modularity – break the application into little pieces
2) Abstraction – break it into the “right” pieces, with “nice” boundaries between modules
Modularization:
Suppose we have N lines of code.
The number of bugs , B, is proportional to N
![]()
The time, t, to find and fix a bug
is also proportional to N. ![]()
Thus, for the no modularization approach:
debug time ![]()
In the modular system we have N bugs and M modules
![]()
Thus, modularization shrinks debug time. This assumes that it is easy to identify that module that contains the bug. There is a clear maintenance advantage of using modularity.
Modularity can be good or bad, i.e. each line of code is a module (N = M)
We can assess modularization strategy using certain metrics:
A. Performance – as compared to the unitary (non-modular) application
Unitary application is faster because the boundaries between modules can be tweaked.
Modulation costs performance, our goal is to minimize this cost.
I.e. syscalls create a boundary between the kernel and OS which hurts performance
B. Robustness – (tolerance of faults, failures, etc)
The system must tolerate faults better than the unitary case
Well designed modules should work better in harsh environments.
C. Simplicity – easy to learn system, easy to use, small manual
The reference manual should be shorter than all the comments needed to explain the unitary code
D. Portability, Neutrality, Flexibility, Lack of Assumptions –
Individual components should not rely on the environment they are called in
Pieces can be plugged into other systems
Let components be used in many ways
I.e. the file component should work with bytes in any medium, rather than insisting it be a file on disk.
Applying these criteria to our read_sector function which is originally very unmodular:
The original from lecture 2 : void read_sector(int s, char *a) { while …. }
1) void ==> int
Change return type to int to represent a success indicator . If an error occurs typically return -1.
2) int s ==> longlong s ==> secno_t s
Original int type for sector number only allows for 2^31 sectors, each 2^9 bytes, for a total of 1 terabyte range that can be accessed. What happens if our drive Is bigger than that? The longlong type is 64 bits wide and makes the code more portable for use with larger drives. Using secno_t creates a layer of abstraction because it is an abstract system type. All the programmer needs to know is that its an integer type. It looks something like this:
Typedef longlong secno_t;
3) int nbytes ==> size_t nbytes
Additional parameter: int nbytes, to indicate how many bytes should be read. What if the type int isn’t what we expect? Size_t allows the optimal width to be chosen for the processor and is big enough to hold any buffer size.
4) Unsigned secoff_t sector_offset
Additional parameter to indicate offset from the start of a sector, the secoff_t type is 9 bytes to reflect the size of sectors (512 bytes). This layer of abstraction prevents attempts to use offsets outside the bounds of a sector.
At this point we have:
int read_sector(secno_t s, unsigned
secoff_t sector_offset, char* a, size_t bytes) { … }
What if we didn’t want to read from a sector, or a device other than the random access type?
Let’s look at: int read(off_t b, char *a, size_t nbytes)
1) Return type: int ==> ssize_t. This type is a signed version of size_t we saw before. This change is made to allow us to show how many bytes were successfully read, in case an error occurs while reading. We need to it be at least big enough to hold any buffer size, and also allow negative numbers for error codes. Note: if we try to read 3 GB, the leading bit will be turned on, indicating a negative quantity, or an error code. This bug is avoided by disallowing that much to be read at a time.
2) Off_t b è int fd: Off_t is a 64-bit signed type which still assumes we are using a random access device. Stream devices don’t have offsets. In its place we use a file descriptor which can be anything readable. Examples of stream devices include: sockets, pipes, tape devices. This change allows for a better interface to abstract out the location we are reading from.
This is POSIX read (used by UNIX):
Ssize_t read(int fd, char *a, size_t nbytes);
However, there’s a problem in that we can’t choose an offset to read from. We solve this using a function called lseek which looks like this:
Off_t lseek(int fd, off_t b,int flag); This function modifies the file descriptor to start at b and returns how much the fd was successfully moved.
Some values of the flag are:
0 – start of file
1 – current read pointer
2 – end of file
Note: the l in lseek comes from the type long. The original seek call used an int type, but the implementers wanted people to migrate to a version using long, so it was called lseek. The name was never changed back.
An alternative solution incorporates the offset into the read call:
Reade(int fd, off_t b, char *a, size_t nbytes)
Properties of the read function:
Virtualization: There is a virtual machine controlled by read which is not the real machine
Abstraction: Using the read machine is simpler than the underlying machine because there’s no yucky hardware, and shows what we want out of an API
How to enforce modularity:
1) The simplest approach – don’t
2) Function calls and C modules - forces us to trust the C compiler and Operating System
CS33 summary function calls:
Simple example in C, factorial function:
Int fact (int n) { if (n == 0) return 1; else return n*fact(n-1);}
We have to compile it with gcc –o0 to prevent gcc from optimizing the code into a loop.
Here it is in x86 assembly:
Fact: pushl %ebp save the frame pointer, subtract 4 and push on stack
Notes: e in ebp means extended (32 bits instead of 16 in original x86),
the l in pushl means 32 bits
Movl $1,%eax ax = 1 default prepare to return 1
Movl %esp,%ebp fp = sp established our own frame
Subl $8, %esp sp -= 8 move the stack pointer
Movl %ebx, -4(%ebp) save bx
Movl 8(%ebp),%ebx bx = n
Testl %ebx, %ebx is n 0?
Jne .L5 if nonzero goto label 5
.L1 movl -4(%ebp),%ebx restore bx
Movl %ebp,%esp restore sp
Popl %ebp restore fp (undoing the pushl)
Ret pop stack top, go there,
.L5 leal -1(%ebx),%eax load effective address long, just compute address
ax=bx-1
movl %eax,(%esp) *sp = ax store indirect
call fact push return address then jump to fact
imull %ebx,%eax result *= n answer in ax register
Note: imull stands for integer multiply long
j .L1
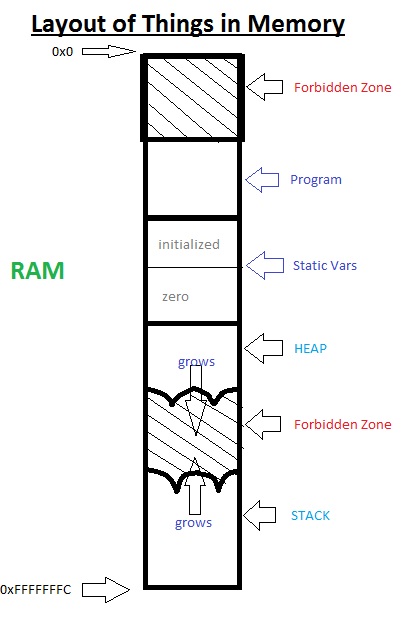 The forbidden zones add some safety because they
are blocked using memory virtualization. The virtual memory unit controls these
zones.
The forbidden zones add some safety because they
are blocked using memory virtualization. The virtual memory unit controls these
zones.
Consider the case where the initial forbidden zone does not exit. This means the address of main is zero. If we do something like (main == NULL) it will be true, because the null pointer points to 0x0.
Typically, if any part of an object lies in a forbidden zone, the application crashes.
The way we are currently doing things has some inherent problems. One of these problems is soft modularity. This means that the caller and callee are free to do whatever they want with eachother's memory. Clearly this is bad for robustness, since if either the callee or caller screws up, the other fails as well. What we want is hard modularity, where no matter what happens to one module, the other module can keep functioning normally, or recover.
Please see Lecture 4 for more notes on hard modularity.