CS111 SPRING 2010Lecture 7: Signals, Threads, and Scheduling (4/20/2010)Table of ContentsReview: Possible Problems With PipesRecall that pipes provide useful functionality for transferring data between processes. However, there are several things that can go wrong when implementing a pipe. Firstly, if there is a pipe with a reader but no writer, the reader will encounter an EOF. If there is a pipe with a writer but no reader, the writer will receive the SIGPIPE signal. One can also create a pipe and never use it, resulting in wasted memory and the possibility of leaked open file descriptors. Furthermore, if a process on the receiving end of a pipe forgets to close its read file descriptor when it is done receiving data, a deadlock will occur, in which the receiving process waits for itself. In another scenario, suppose that both the send and receive processes for a pipe exit before the parent process can wait on them. An arbitrary freshly forked process could then use one of the newly available process IDs. When the parent eventually waits on that process ID, it will be waiting on an arbitrary process, one that it did not originally intend to wait on! The solution to this scenario is referred to as a zombie process. When a process exits, it enters the zombie process state. When this happens, it cannot be reclaimed (or "reaped") until the parent process waits on it, after which the process ID becomes available for reallocation to other processes. What if a parent process dies before its children? When this occurs in Unix, process 1 "adopts" these orphaned children. Note that in general, a process can only wait on its own children, with the exception of this special case. Here is a basic outline of what the parent process does: 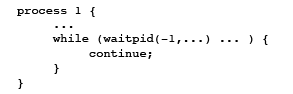
SignalsImagine that one of the processes running on a system goes haywire, and starts deleting files at random in the user's home directory. How does one stop such a rogue process? The answer lies with signals. While pipes can be used as a communication medium between processes, the hard modularity that is characteristic of a send & receive approach makes this method unsuitable for absolute control. For example, one could send a message telling a rogue process to exit, but control still lies entirely with the receiving process. A signal does not have this limitation. When the kernel reschedules an application, it can:
With a signal, the kernel can send various types of messages to any process,
which must handle the signal. Most signals allow the receiving process some flexibility in its response
to a given signal, with a few exceptions (such as SIGKILL). If a process does not implement specific signal handlers, the kernel's default
actions will be used. Some examples of common signals are listed in the table below. All signals can be found in the header file
A user can invoke a signal on a process using the Let's return back to the mention of signals being "asynchronous." This means that a signal can arrive at any point in a process, even between individual instructions, and it must be handled immediately by that process. Signal handlers should be written as simply as possible with minimal functionality, in order to mitigate any impact on the receiving process. They should also never introduce race conditions. One can think of signals as a user analog to hardware traps, with a higher degree of abstraction. Much like a hardware trap that hands control to the kernel when a process attempts to execute a privileged instruction, a signal forces a process to give control to an appropriate signal handler. A trap is defined by the hardware (in our case, the x86 machine); a signal is defined in software.
Let's run through signal processing in a simple program. Take the terminal command 
This code seems very straightforward and simple, but if we look a little closer with signals in mind, there are a few very critical bugs in this code. What happens if the process is killed by a (CTRL-C) by the user? What could go wrong? The implementation of gzip we are assuming requires that the input file be deleted after the archive is created (we are assuming the user wants to save as much space as possible). What if the user kills the process right after everything is done but the input file has not been removed with 
Now the interrupt signal is ignored around special areas of code. But this isn't the best way to do this. We should use the 
ThreadsBoth processes and threads are ways to run programs. The major difference between them is the fact that processes each have their own memory; threads, however, share memory within a process. This makes inter-thread communication very fast, but also very dangerous, as it is very easy to trample over another thread's data. The biggest trouble with threads is synchronization, or how to maintain the correct flow of data and information without introducing race conditions. Basic alternatives to threads include the use of processes, or the use of event-based programming. Event-based programming divides a program into a set of event handlers. Handlers never block, they instead use a call-back method to another handler. This programming style removes many dangerous race conditions, but is not viable on a multiprocessor machine. Here is a representation of event-based programming, Where A, B, and C represent different sections of the code, referred to as event handlers. C's only event is when it is reached, and its default operation is to load the A handler. 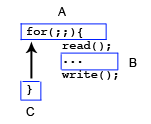
Similar to processes, threads compete for processors. If there are more threads than processors, then we need to implement a scheduler. Introduction to Scheduling
There are two basic types of scheduling: cooperative and preemptive. In a cooperative scheduling setup, all threads should be nice and decide to
As stated above, cooperative scheduling relies on the threads themselves to 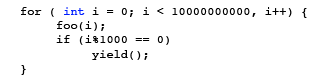
Yielding can also be done with:
Preemptive basically adds a timer interrupt to cooperative scheduling. The kernel should be able to take control by detecting a hardware trap and should call schedule to let another thread have a chance at the CPU. From an application's point of view,
Here is a basic implementation of 
The "choosing of a process that isn't blocked" part of this code must be fast. If it isn't, it will be felt by the user over and over again. The scheduler can choose the next running thread or process by a policy implemented by the designer. Some sample policies are First Come First Serve (a.k.a. First In First Out), and
| ||||||||||||||||||||||||||||||||