By Hongxiang Gu and Libo Wang
A system is formed by a number of components, and these lower level subsystems may be reliable or not. We have two ways to make a system reliable at our level:
There are many events that can crash a system, and they can be categorized into external events and internal events. For a very simple desktop system (with single disk, CPU, RAM, network, etc.), the bad events are:
Imagine we have a simple file "cs111grade.txt". For simplicity, its size is always 20,000 bytes.
read(fd, but, 20000); // LOAD operation. easy to implement from user's viewpoint write(fd, but, 20000); // SAVE operation
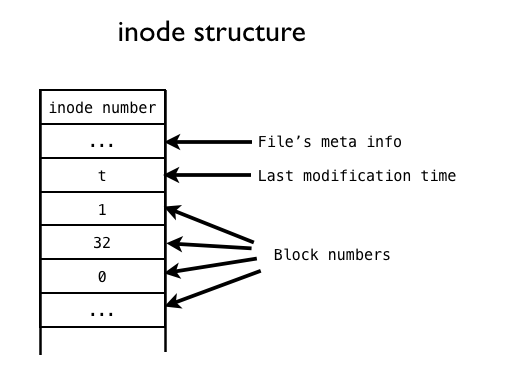
And the file's inode data structure looks like this:
This call to write requires us to update both the metadata and the data.
And this leads to the Golden Rule of Atomicity:
The Golden Rule of AtomicityNever overwrite your only copy, unless your underlying write operation is known to be atomic. |
Clearly if we have the copy of the original file, then we can fix the inconsistency problem in writes. This method keeps one more copy of the file we are writing, and nothing else. Here's how it works. Let's call the old version A and new version B. The modification is made in the file called TMP, and we try to copy TMP to another file MAIN. The high level representation of the whole process is:
| Content | |||
|---|---|---|---|
| Phase | 1 | 2 | 3 |
| MAIN | A | A | B |
| TMP | ? | B | B |
However, this approach doesn't work. The low level implementation of this write is:
| Content | |||||
|---|---|---|---|---|---|
| Phase | 1 | 2 | 3 | 4 | 5 |
| MAIN | A | A | A | ? | B |
| TMP | ? | ? | B | B | B |
Notice in the first four phases, the two files are different. After a power failure and reboot, if we find MAIN is different from TMP, we can't tell which phase we are in, so the data recovery is still impossible.
Here is how this method works. The three files are called MAIN, TMP1, TMP2. The user makes modifications in TMP1, and later MAIN is updated with the aid of TMP2.
| Content | |||||||
|---|---|---|---|---|---|---|---|
| Phase | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| MAIN | A | A | A | A | A | ? | B |
| TMP1 | A | ? | B | B | B | B | B |
| TMP2 | A | A | A | ? | B | B | B |
The recover procedure after reboot is "majority rules": when there are two identical copies, take the majority. Otherwise (phase 4), take TMP1. This will guarantee we get "A" or "B", never "?". All-or-nothing atomicity is achieved.
The downside: this procedure is not ideal for large files: get 3 copies of a large file will be 3 times slower and more expensive.
Keep a COMMIT record of size 512 bytes (the size of a disk sector), and we assume writing to a single sector is atomic. The COMMIT holds only 0 and 1. Then the phase table looks like:
| Content | |||||||
|---|---|---|---|---|---|---|---|
| Phase | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| MAIN | A | A | A | A | ? | B | B |
| TMP | A | ? | B | B | B | B | B |
| COMMIT | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
If COMMIT==0, then MAIN contains the consistent data; if COMMIT==1, then TMP contains the consistent data. We can see the actual COMMIT action is in phase 4. Also phase 7 is optional, and it's no longer important to distinguish between MAIN and TMP, since COMMIT tells us about which file to look at.
Here we made an assumption that "COMMIT" (small write) is atomic. This, actually, is part of what's known as "Lampson - Sturgis assumptions", a good set of assumptions when designing a file system:
Lampson - Sturgis assumptions
|
This approach is an application of the general pattern for implementing a high level all-or-nothing operation(write), atop a system in which only some ops are atomic(sector writes):
Algorithm atomic-do:
BEGIN (conceptual)
Pre-commit actions (not permanent: can back out, leaving no trace) // phase 1-3
Commit action: atomic at lower level, make the higher level action happen // phase 4
Post commit phase (we can't change our mind here, // phase 5-7
but may improve performance by setting things up for
the next operation, etc.)
DONE (conceptual)
The idea of this type of methods are taken from double-entry bookkeeping: never erase anything from your ledger. The journal storage is append-only and we don't need to put cell and journal on the same drive. Also the cell storage can be cached into RAM to improve performance. Here's one picture showing that a file system divided into two parts: journal and cell storage.
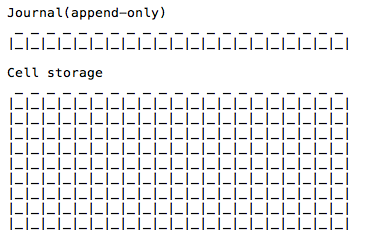
Say we want to change block 27's content from A to B. Here is one simple logging protocol: (write-ahead log)
Recovery procedure after power failure:
Here is an alternate logging protocol: (write-behind log)
Recovery procedure after power failure:
Protocol 2 is faster because in recovery, we start reading from the newest entries, and start fixing damages immediately. This is especially good for long journals. The downside is: the individual operation is slower, since we must store the old value into the journal every time for the rare recovery.
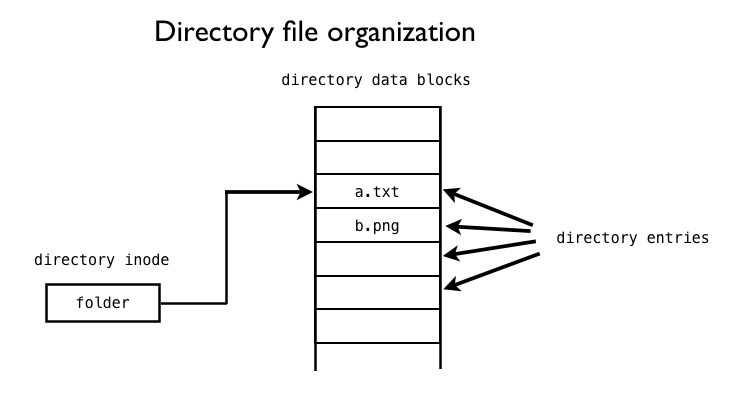
This picture shows the inode and data blocks of a directory file. (Regular files are organized in a similar way, but their data blocks contains other things than directory entries)
Changing file names also involves writing. If we the new filename is still in the original directory, we only have to modify one directory file, and this can be solved using the atomic write mentioned above.
Otherwise, we must write to two files. Here is one method to write, but this method is subject to data loss, which is considered a disastrous consequence. Suppose the high level operation is:
rename("d/f","e/g"); // change the file name from "d/f" to "e/g"
Here's the algorithm:
Algorithm RENAME_1 1 get d's inode into RAM 2 get d's data 3 get e's inode into RAM 4 get e's data 5 update d's data in RAM 6 update e's data in RAM 7 write d's data (f is officially removed) 8 write e's data (g is officially created)
However, if the power is down right after step 7, before g is created, then the file is missing after reboot! We must invert these two steps.
7 write e's data (g is officially created) 8 write d's data (f is officially removed)
Now if the power is down after step 7, f and g both exist in the file system after reboot. However, the link count of the file is only 1: after the user removes either one of them, opening the other will cause disaster. Therefore we must also update link count of the file. This method will prevent the above-mentioned situations from happening:
Algorithm RENAME_2 1 get f's inode into RAM 2 get d's inode into RAM 3 get d's data 4 get e's inode into RAM 5 get e's data 6 update d's data in RAM 7 update e's data in RAM 8 change f's link count to 2 9 write e's data (g is officially created) 10 write d's data (f is officially removed) 11 change f(g)'s link count to 1
We can see that before step 8, everything is in RAM and not commited. If system creashes between 9 and 10, then we hold two hardlinks to one file with link count 2, and this is valid; if system crashes between 8,9 or between 10,11, then we have a file with link count 2 and one hardlink pointing to it. If later a user try to remove this file, then the inode has link count 1 but user can't see it anymore: we have a storage leak! However, compared to data loss, storage leak is not a very serious problem, and can be fixed with a file system checker program (fsck). See lecture 14 for details.