Cloud Computing is more of a marketing term; a more preferable name would be Utility Computing since we want to share computing capabilities just like we share power and water because it is more efficient.
Cloud computing is based on the commoditization of computing.
One of the things we want is to be able to do is run in low power mode. That is, we want to be able to power down when not in use and power up quickly as needed. To achieve fast power-up’s you want to stay away from rotating disk, but replacing al these with flash memory is too expensive. Instead, only use flash as a cache to rotating disks when reboot/power-up quickly.
Looking at the bigger system, one must ask the question: Is there an opportunity for a Cloud O.S.? If there is there is a problem, it’s messy!
Looking back at the marketing aspect, we can take a deeper look as some of the advantages and disadvantages of Cloud Computing. We cover the advantages first.
Some of the disadvantages are that Cloud Computing is actually not that new. In the 1960s 2-million-dollar mainframe computers allowed many users to timeshare it’s resources. Fast forwarding to the 1990s, expensive mainframe computers were replaces with clusters of thousands of cheap computers.
These clusters, however, bring up problems of control. For example, as shown below, different clusters have different system administrators and these administrators don’t always see eye-to-eye. The question then becomes: How can I do a computation using multiple clusters? Trying to do this can become a system administrator nightmare. It is this usage of multiple clusters that is know as the Cloud where the cloud manager is the one that deals with all the idiosyncrasies.
To help cope with the complex duties with managing clusters, Virtual Machines (VMs) are installed on each clusters’ computer so that the OS of choice could be run. VMs are slower but in recent years CPUs have have begun to be designed in ways that get VMs running more efficiently.
Another disadvantage is one involving management and accounting. Specifically, as far as management is concerned, who controls the cloud? Cloud administers or users? For example users might want to login, run gdb, and attach to a process. For security reasons this capability is disabled by default since a hacker would then be able to break in and attach the debugger to the log-in authentication programs and get passwords as you type them in. For the accounting side of things, who pays and how is resource usage accounted for. Is is said that more than half of a phone companies’ expenses come from billing and Cloud Computing Service providers can be having the same issues collecting.
To add to the disadvantages mentioned above is the issue of software licensing. First of, software licensing of commercial software can be a big impediment. For example, some licenses charge per number of cores the software will run on. This becomes more difficult to assess when resources change all the time; one day you are using twenty cores, the next day you need a hundred cores. Another downside is that you can fall into the licensing trap, that is, the code you write to build up or around the software you licensed becomes a commitment.
On top of all the issues mentioned, comes the question of data confidentiality. Do you trust your cloud venter to keep your secrets?
As an example, suppose you are in charged of all patient data at Ronald Reagan UCLA Medical Center, one way you can improve on confidentiality is to split up your data. On the cloud you keep all the low-level pixels such as x-ray images on the cloud and in your computers you keep all the private data such as patient name and patient id numbers with reference of where in the cloud other information can be found.
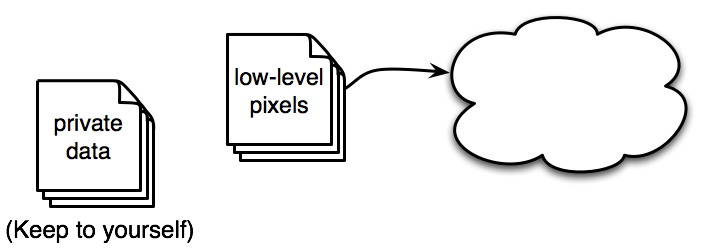
This is not bullet proof since a hacker can hack into the cloud and be able to pick out images of say a celebrity. To improve on this you can encrypt data before sending it off to the cloud. The down side of this is that it defeats the purpose of Cloud Computing since you are doing all the computations on your computers and only sending off the data for storage. An ideal solution to this downside is to have computations that work on encrypted data and its results are more encrypted data which you can then download and decrypt on your computers. The image below show’s an illustration of such functionality.
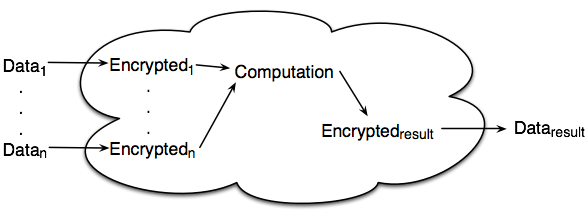
The functionality above currently lends itself well to few kinds of problems, but even if you were to get that to work you run into the problem of bottlenecks and sending confidential data over untrusted network.

Bottlenecks can be so bad that it might be cheaper and faster to go the “Sneaker-Net” route.
Now, suppose your cloud service provider is busy. You can use multiple Cloud Service Providers however this will increase complexity. Even with this added complexity a global meltdown is still possible due to a Distributed Denial of Service attack (DDoS). Even worse, somebody can run a denial of service attack on your application which then causes your application to request more resources from your service provider which then might think you are part of the attack. Attacks aside, data access overload is usually the biggest problem. Overall Cloud Computing is a scalable service but unsolved problems remain.
Lastly, adding to the difficulty is having bugs that only happen as you scale up. How do you test and debug large production applications in which many bugs are race! This is the main reason why there is a lot of conservatism in deployment; major changes are far and few between.
The consistency, availability, and partition tolerance theorem is broken down in the the following way: Consistency is having the client seeing a single consistent state. Availability is having data and or applications always available. Lastly, partition tolerance is the ability to do even when the cloud is partitioned. The limiting factor is that you can choose any two of these goals but you can’t have all three at once.
To compare to other other computing scenarios you could say CAP is to clouds as ACID/BASE is to DBs. Acid is traditional databases designed for transactions, banks with the following properties Atomicity, Consistency Isolation (serializability), and Durability. A classic example of a acid databases is PostgreSQL. On the other hand BASE doesn’t want all these properties, they want data fast! An example of a BASE database is NoSQL. BASE databases are not used for banks because they can be inconsistent. Instead these databases are used in data mining. This is because these applications do not need databases to be consistent at every moment. BASE databases available and eventually become consistent and stabilize when no changes are made to them.
Some of the consequences are that full partitions are rare and tiny partitions are more common. Other consequences are as follows: When it’s just the client, they can be in “disconnected mode” and run off browser cache and downloads. When it’s just the edge server, it’s often the case that the connection is overloaded, not down. Latency issues often predominate. For example, you issue a request but you receive no response. In this case you have three choices. First you retry by sending the request again, typically after a timeout. Retrying says you want consistency; you can retry as much as you want. Second you can cancel the operation. Third, you proceed with the operation, this creates a partition. These three choices are divided into two phases, the first is the delay phase since you can choose to retry as much as you want; steps two and three are the decide phase because you choose to cancel of go ahead assuming the operation went through but a response is just delayed.
When partition created by going with option three mentioned about ends, partition recovery needs to merge inconsistent states. Your first thought might be to use timestamps when deciding how to merge, however just using timestamps wont work because you run into the problem where the “last writer wins”. What you really want is a setup where during a partition you can’t cause trouble. One way to do this is that during a partition you do only commutative operations.
For example:
p1: A, B, C
p2: M, N, O, P, Q
are merged to
A, M, N, B, P, C, Q
Ken Thompson from Bell Labs wrote the kernel, debugger, c compiler, login (setuid root) to name a few. He produced Unix v7 in which he distributed all the source, all binaries (compiled PDP-11) and boot program on a tape. He realized that maintaining the distribution would be a big hassle so he installed a back door using code such as:
if (strcmp(user, "ken") == 0 && strcmp(password, "unixisgreat") {
uid = 0;
return ok; // now has control of the computer through "back door"
}
However, since he was distributing all the source code he realized people could look at the source code and the hole so he changed the c compiler to include something like the following:
if (strcmp(sourcefile, "login.c") == 0) {
generate_this_code("some_binary_file");
// the binary file has the bug
}
However, now the debugger can be used to disassemble the code. Did he change the debugger to hide this as well?…