CS 111: Operating Systems - Lecture 2
April 5, 2012
Scribe notes by Komei Nakamoto, Eric Sun, and Armando De los Santos
Issues with Computer System Cont'd
Last Lecture
The definition of an operating system was discussed and refined as an introduction to this course and the major aspects of operating system were listed and described. With every operating system there are tradeoffs and issues arise with incommensurate scaling.
Today
Continued discussion of operating system issues:
- incommensurate scaling
- emergent properties ( related to scaling but qualitatively different )
- propagation of effects
For more information on incommensurate scaling please read Charles Coffing's article, "Effects of Incommensurate Scaling on File System Design".
- http://web.mit.edu/6.033/1997/reports/r08-kiowa.html
FTP
Development on File Transfer Protocol ( FTP ) in 1976 hadn't yet fully grasped the significance and complexity of scaling a network to achieve far greater levels of network throughput. It wasn't until the 1990s as the number of users on Napster required more file servers than the original network system could support that new system problems arose.
Network Size - As the number of users increases, file servers have grown to support greater network output. With the advent of applications requiring high network throughput, new jobs were created in qualitatively different fields such as network policy.
Facebook, for instance, is running into emergent properties that were difficult to anticipate. These properties can be likened to "surprises" in the system. As they make their changes to address these glitches they may notice that a minute modification to their system could produce unexpected behavior that significantly deviates from their original design. The effects manifest themselves only after a system has been scaled up beyond the size for which it had originally been intended and are a result of the propagation of effects.
For more information on problems with computer systems please refer to the work by Frans Kaashoek and Nickolai Zeldovich at MIT, "Intro to Computer Systems: Complexity".
- http://web.mit.edu/6.033/www/lec/l1.pdf
GNU tar archiving
Backups are now commonly done on virtual machines. However, creating an archive of a file system is computationally expensive and extraction of these files runs on a live file system. The file system lives inside of the system adminstrator's file system. An attacker can use a backup to change files as the archive is extracted.
The tar utility will scan through a directory hierarchy to detect files. It will realize that it needs to copy them into the archive. However, it is possible for an attacker to replace a directory with a symbolic link by the same name that pointed to a different file. When the system arminstrator restores this backup, files that the attacker couldn't have gotten in with his credentials are extracted onto the system.
Pseudocode:
tar read_dir /vf/sys1/usr/apache/conf
tar read_file /vf/sys1/usr/apache/conf/xyz
// Here, the attacker replaces the Apache directory and replaces it with a symbolic link
// Symbolic link points to /vf/sys2/ect/passwd
The archive is extracted and the attacker now has a copy of the user's password.
How to fix this problem?
- Never pass a string like that.
- Alternative: Run tar seperately in each system; open directories individually.
Solution No. 2
Use a special flag named, "O_NOFOLLOW" when opening a directory. For example,
open("apache", O_RDONLY | ... | O_NOFOLLOW) // This command says not to follow links.
For more information on issues with archiving virtual machines, please read the article by Mark Davis, The Virtual Machine Backup-and-Recovery Conundrum". It can be found here:
http://www.technewsworld.com/story/69975.html
Complexity
How to manage it? Different systems manage complexity in different ways. The more thorough developers are in managing complexity, the more useful and efficient the system will be. Likewise, a superior management of complexity can deploy more complicated systems than the competitor.
Precisely what level of complexity does this discussion allude to? The smallest hardware component of a computer system, the transistor. The more tighly packed transistors can operate, the more computational resources are available to the user per PC. From 1970 to the present, the number of transistors per chip at minimum cost has doubled approximately every eighteen months. The number of transistors on a chip has increased from twenty thousand or so in the 1970s to three billion in 2012.
For more information on Moore's Law please read the report by Intel Corporation or the more detailed online Intel Museum.
- ftp://download.intel.com/museum/Moores_Law/Printed_Materials/Moores_Law_2pg.pdf
- http://www.intel.com/about/companyinfo/museum/exhibits/moore.htm
The complexity of a computer isn't entirely dictated by the density at which transistors are integrated. The system can not complete all of its instructions without accessing necessary data from memory. One aspect of efficient computer systems is how fast it can process data and the other aspect is how quickly it can retrieve the data on which it operates. Disk drive capacity is increasing at a rate considerably faster than the number of transistors per integrated circuit can double, from 0.1TBytes in 1990 to 1TByte in 2012. Disk drive capacity was researched by Mark Kryder and his findings were published in an article titled, "Kryder's Law".
The capacity to which information can be stored in secondary memory is increasing exponentially but speed is improving at a rate much slower. This is a problem of incommensurate scaling because the speed with which problems can be solved is not increasing exponentially. The Big Picture is fundamentally about complexity.
Sample Problem - if without Operation System
A paranoid professor wants a "Stand Alone Program" that counts words in a file.
Requirements and Specifications
- as fast as possible.
- as simple as possible. (e.g. Turn on the machine, and it displays the words count.
- Machine Specs:
- PC: x86 single core CPU, 1GB RAM, 200GB hard disk.
- VGA monitor.
- Run in text mode.
- File format:
- Assume the file is already in the disk.
- ASCII text file.
- Words are in form of [A-Za-z]+.
- '\n' separates lines.
- '\0' represents end of file.
- Problems we have to deal with.
- How to boot the machine?
- How to read input from disk?
- How to output to screen?
Boot Strapping
To make the machine running our own program when turned on, we have to make the machine load our program into memory and set the instruction pointer (IP) to the start address of our program.
BIOS
The contents of RAM do not preserve data without power supply except the part called PROM (programmable read-only memory). When we turn on our machine, it starts with the instruction pointer (IP) set to the boot PROM, and run the program stored there, which is BIOS (basic input/output system).
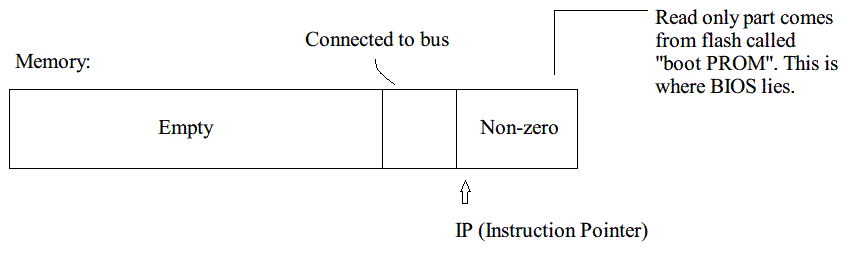
The BIOS performs the following tasks:
- Tests the system. (eg. Memory test)
- Looks for devices connected to bus.
- Finds a device that has MBR (Master Boot Record), which means it's
bootable.
BIOS finds MBR by identifying if its last two bytes are 0x55 and 0xAA (little endian). This is called "MBR signiture". - When found the MBR, it loads MBR to 0x7c00 of RAM, and set the instruction pointer to 0x7c00.
MBR
MBR is a 512 byte record that located in the beginning of a disk. The first 446 bytes are x86 code that MBR runs. The next 64 bytes are partition table describing 4 partitions (status/type, start address, size). We only have 4 partitions because of the room limit.
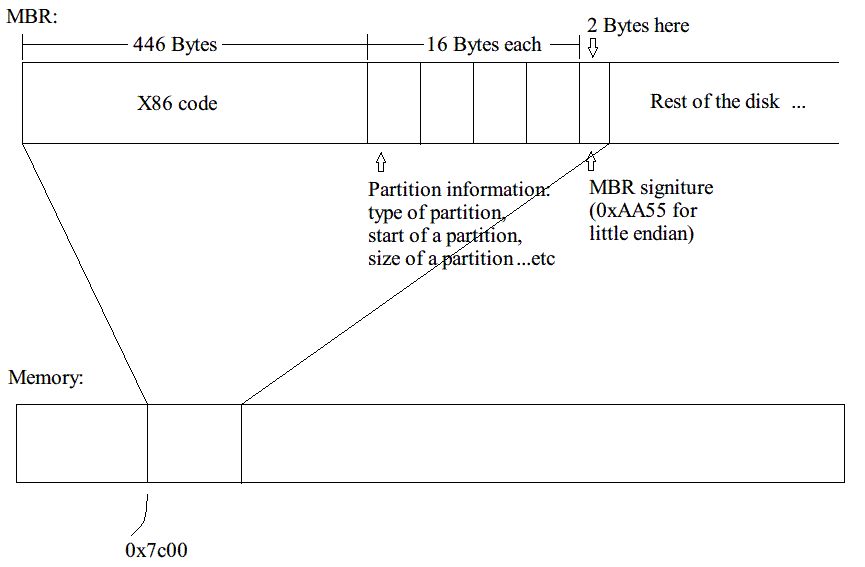
what does MBR do?
- checks the partition table and looks for a bootable disk partition.
- when found bootable partition, loads first sector of the partition, VBR (Volume Boot Record), into RAM.
Finally VBR can read any program we want into memory. Normally, it loads
boot program of particular OS.
(e.g. VBR runs GRUB, and GRUB runs Linux kernel.)
The difference between MBR and VBR is that MBR is OS agnostic, meaning it's
independent of OS that is booting.
"Chain Loading": in summary, the boot process is in a chain. BIOS loads MBR, MBR loads VBR, and VBR loads boot program of OS.
Read from Disk
CPU, RAM, disk are all connected to data bus and communicate with each other through data bus. Disk is connected to disk controller, which communicates with data bus to performe reads and seeks on disk.
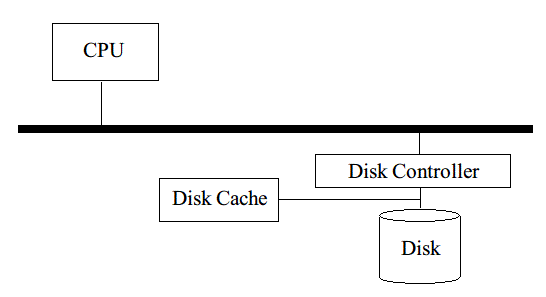
To get a random data from disk (7200rpm, or 120Hz for a regular disk):
- Seek (move disk-arm to the track we want) 8ms (average).
- Wait rotational delay 4 and 1/6 ms (1/240 s).
- The total waiting time is 12 and 1/6 ms because the disk is keeping on spinning.
Suppose a computer can excute 10^9 instructions per second, then in the waiting time (12 and 1/6 ms) there can be 12166666 instructions in that time.
Programmed I/O: a method of transferring data between CPU and other I/O devices by accessing I/O address (bus address).
CPU can load and store from:
- 0x1f7: 8 bits register that stores status and data read from disk.
- 0x1f2: 8 bits register that stores number of sectors.
- 0x1f3~0x1f6: 32 bits sector offset.
How to read a sector into RAM?
Sample Code:
// s is the sector number, and a is the memory address we want to write
void read_ide.sector(int s, char *a)
{
// wait until device is ready
while((inb(0x1f7)&0xc0) != 0x40) // inb instruction reads address 0x1f7 in bus
continue;
outb(0x1f2, 1); // set the number of sectors to read to 1
outb(0x1f3, s&0xff); // outputs all the 4 bytes of the sector number
outb(0x1f4, (s>>8)&0xff);
outb(0x1f5, (s>>16)&0xff);
outb(0x1f6, (s>>24)&0xff);
outb(0x1f7, 0x20); // READ_SECTORS inscturction is given here
while((inb(0x1f7)&0xc0) != 0x40) // wait until the disk is ready to issue command again
continue;
insl(0x1f0, a, 128); // copies data out of disk cache into RAM, in size of 4-byte words for 128 times
}
Put the above codes into C compiler, we will get the machine code for read_ide_sector, and then we can put the machine code into MBR.