|
We want to have good performance from our file systems, but how do we measure how "good" our performance is? Metrics for Performance: Our Example Device: Assume we have a device with the following characteristics: The "Naive" Method Now, let's consider trying to run the following code on this device.
for(;;) Latency (microseconds) = time to send command (5) + device time (50) + read time (40) + time to compute (5) = 100 microseconds Throughput = 1 / Latency = 10,000 requests/second CPU Utilization = time to compute / Latency = 5 / 100 = 0.05 = 5% Batching The naive method above is simple, but performance is slow. Rather than reading in one byte at a time, we can read and compute them in batches. This increases our utilization.
for(;;) -Though, the actual latency here is staggered. -Actual Latency = first buffer (950) + ... + last buffer (5) Throughput = 1 / Latency = 50 / 1000 (40-bit requests/s) = 21,000 40-bit requests/s -This is because each request has a size of 20. CPU Utilization = 105 / 1000 = .105 = 10.5% Interrupts We can further increase performance by using an interrupt handler with our batching process such that the IO access and computation runs in parallel.
for(;;) Throughput = 1 / 56 (microseconds) = 17,857 requests/s CPU Utilization = 1/56 (microseconds) = 8.9% Direct Memory Access (DMA) Using interrupts leads to some improvement, but can create a bottleneck. We can avoid this bottleneck using direct memory access. Direct memory access allows the file system to perform computations while the controller accesses the memory directly.
for(;;) Throughput = 1 / 11 (microseconds) = 91,000 requests/s CPU Utilization = 5/11 (microseconds) = 45% Direct Memory Access with Polling (DMA) Now, rather than blocking, we implement DMA using polling. This allows us to avoid the overhead from blocking interrupts. Polling, however, eats up more resources than blocking.
for(;;) Throughput = 1 / 6 (microseconds) = 166,666 requests/s CPU Utilization = 5/6 (microseconds) = 84%
Disk Latency comes from:
b.Decelerating the read head as it gets close to the target track 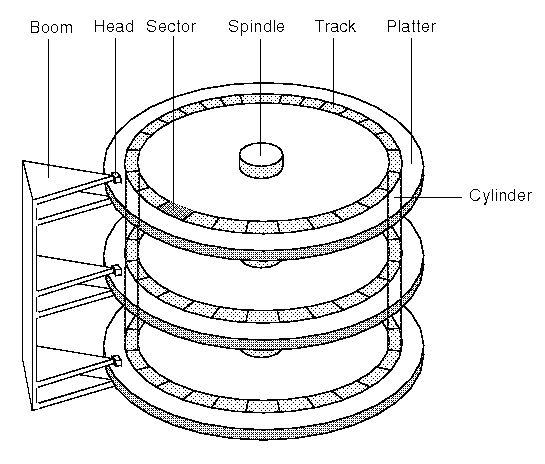 Seagate Barracuda ES2 1TB ("nearline storage")
Basic Ideas for Improving Performance Prefetching: This requires acquiring data from the device and placing it into RAM cache before an application requests it. This can be done within the application itself (such as in the batching example), within the OS, or in the disk controller. Speculation:Preemptively do work in hopes that it'll improve performance later -eg.Move the disk arm to the middle of an idle drive Batching: (for Reads) Batching: (for Writes) Cache information we want to write into the kernel. Then, fill up the buffer until it is entirely full before sending it to the disk. -Downside: Data is not actually on persistent storage Dallying: Rather than writing imeediately, wait a certain period of time first.This can save work when the file system is doing work for multiplie applications. By grouping related tasks together, we can avoid excessively moving the disk arm. While each method benefits performance in some way, they do have their own disadvantages. Speculation can hurt performance if, for example, it moves the arm to a spot that is actually further from the desired location. Prefetching can waste RAM or tie up the disk unnecessarily. Locality of Reference Locality of Reference deals with the patterns within data requests, which can be used to predict future requests. We can utilize these localities to increase efficiency. Spatial Locality: Predicts data access based on where they are located in memory. For instance, if we access the ith block, it means it is very likely that we will next access the i + delta block. 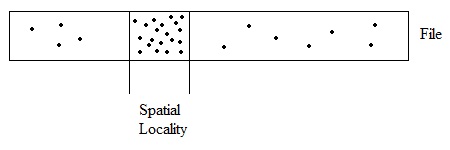
There is a key assumption that we are making here. Cache Coherence: We assume our caches of disk data are accurate. However, this gets increasingly difficult as the number of CPUs grows. SOURCE: Image 1 SOURCE: Image 2 |
||
{kind=link}