CS 111 Lecture 10 Scribe Notes
by Gagik Matevosyan and Rossen Chemelekov
Deadlocks and File System Performance:
Overview: Enter some cute overview here, explaining what we did last lecture, etc...
More on deadlocks:
A deadlock has 4 conditions:
- Circular wait: a process holding a resource is waiting on another resource which is held by a process waiting on the first process's resource.
- Mutual Exclusion: no two concurrent processes execute their critical section at the same time.
- No preemtion of locks: a lock on resource can only be released by locking process, cannot be pre-empted by OS
- Hold & wait: a process holding a resource waiting for resource(s) held by another process.
Circular wait is the most popular condition tackled in system design. One way this is done is having
the resource manager look for cycles on each wait.
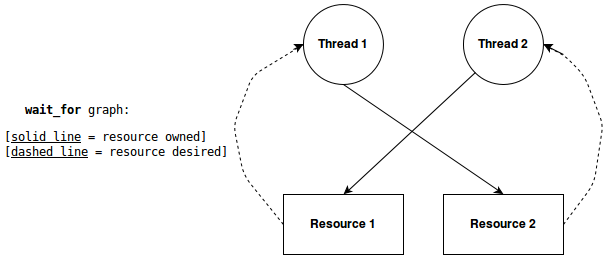
What is the cost? Given P processes and R resources, the cost of checking for loops is: O(PR) (?).
Can be improved to O(1) by Lock Ordering:
Assumption: cooperative application.
i) Process lock of resources in increasing order (of machine address).
ii) If you find a lock busy, give up all your locks and start over.
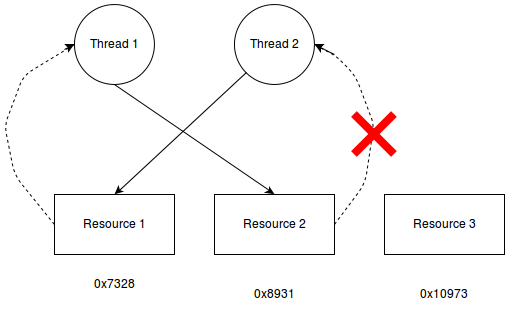
* After i) & ii), deadlock is broken because step 4 of deadlock conditions (Hold & wait) never happens.
Problem: Lock ordering assumes (relies on) your applications being cooperative!
Solution: OS can enforce ordering. Downside is larger overhead.
(Quasi-)deadlock: Priority Inversion (killed off Mars Pathfinder rover in 1997)
Assumption: A preemptive scheduler with priorities.
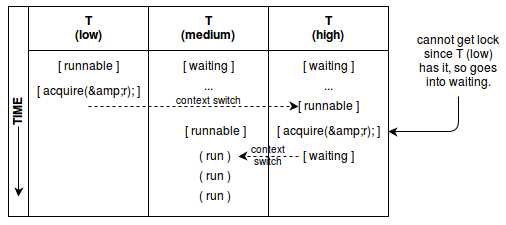
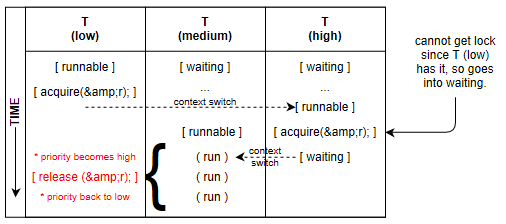
Solutions to Priority Inversion: (Eggert: "Don't allow 3 levels of priority. Duh.")
- Low-prioirity process holding lock required by a high-priority process is temporarily given the priority
of the highest prioirity process requiring the lock to avoid being preempted by another process, then
releases the lock returning to its low prioirity.
Recursive Livelock:
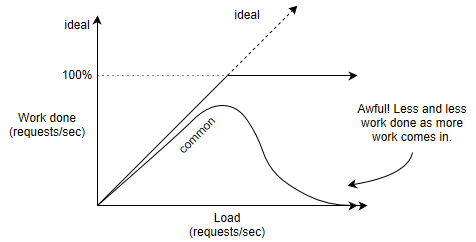
High priority tasks swamp the CPU and low priority tasks take a long time to get (or are never) done.

Solution to Recursive Livelock: Work routine can check buffer fullness. If buffer is full, disable
interrupts temporarily, allowing the CPU to get work done before processing new requests.
[Obvious Conclusion] Data races are evil! If not for data races, we wouldn't need locks, mutes, etc. Problems with data races arise because we have 2 or more threads.
Alternative: Use just one thread. Of course, we still want to be able to wait for events.
- Event-driven Programming: Single thread only.
while (true) {
wait(e); // wait for some event e to happen
e -> handler(e); // and handle it
}
* Handlers themselves never wait, they try to acquire/release a lock. Thus, they must finish fast, otherwise they may lead to stalls.
- Pros:
- no locks
- no deadlocks
- no bugs due to forgotten locking
- Cons:
- handlers are resticted - for bigger tasks, need to break into smaller pieces
- can't scale via multithreading (SMP) + shared memory
Problem: Too much time spent waiting for locks.
Solution: Get hardware support. Hardware Lock Elision: Pretend to have a locka and act accordingly.
Hardware Lock Elision (HLE):
Example (Haswell instruction set):
lock:
movl $1, %eax
try: // trade register with memory
xacquire lock xchgl %eax, lock
cmp %0, %eax // if 0: lock acquired successfully
jnz try // otherwise, try again
ret // if lock not acquired, return
unlock:
xrelease movl $0, lock // release lock
ret
* On older systems this would still work without the xacquire and xrelease commands.
How can a CPU determnine if instruction never happened? Through the cache.
If you wish to know more, look into Transactional Memory.
File System Performance:
Example File System:
- 120 PB
- 200,000 hard drives (600 GB each)
General Parallel File System (GPFS)
Performane ideas:
1. Striping - Split file into multiple pieces and put on different disks (all can be read simultaneously).
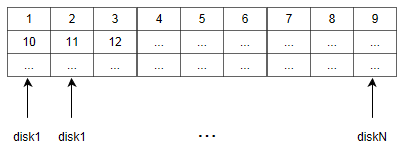
2. Distributed Metadata: - Tells you information about location, ownership, timestamp, etc. (kept in a cluster of nodes, rather than a single location). In the cluster of notes everything is a data note, potentially a master node.
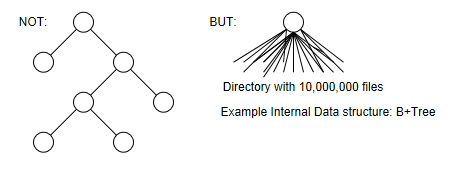
3. Efficient Directory Indexing:
4. Partition Awareness: - Largest partition stays alive.
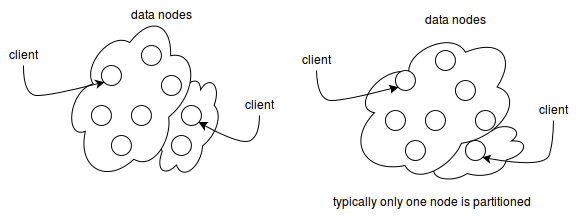
5. File system stays alive during maintenance
How do we measure File System Performance?
Performance Metrics:
- Latency - delay from request to response (similar to turnaround time of processes)
- Throughput - rate of request completion
- Utilization - the capacity of CPU (and/or bus bandwidth) to do useful work
As previously done, we want to minimize latency and maximize Throughput and Utilization.
Example with a file system having the following characteristics:
- CPU cycle time = 1 ns
- PIO (Programmed I/O) instruction = 1000 cycles = 1 micro second
- Send command to SSD (secondary storage device) = 5 PIOs = 5 micro sec
- SSD latency = 50 micro sec
- Computation (per buffer) = 5 micro sec
- Read 40 bytes from SSD = 40 PIOs = 40 micro sec
- Block interrupts = 50 micro sec
Using same algorithm as we did with booting:
Busy wait + polling:
for(;;) {
char buf[40];
read(fd, buf...); //read 40 bytes from SSD into buf;
compute(buf);
}
For each buffer:
Latency (micro seconds) = (sending command to SSD) + (SSD latency) + (read latency) + (compute) =
= 5 + 50 + 40 + 5 = 100 micro sec
Throughput = 1/latency = 1/(100 micro seconds) = 10,000 requests/second
Utilization = (50,000 requests)/(1,000,000 sec) = 5%
Ideas for speedup:
- Batching - get a big block, rather than a few bytes. First answer will be slower
because of the bigger batch. Overall, throughput and utilization will go up.
changed code:
for(;;) {
char buf[840];
read 840 bytes;
for (i=0; i<21; i++)
compute(buf + i*40);
}
Latency (micro seconds) = (sending command to SSD) + (disk latency) + (read latency) + (compute) =
= 5 + 50 + 840 + 105 = 1000 micro sec
Throughput = 21,000 requests/second
Utilization = (105 requests)/(1,000 sec) = 10.5%
- Interrupts:
for(;;) {
block until there's an interrupt
do
handle interrupt
while(!ready);
}
Latency (micro seconds) = (send) + (block int.) + (handle int.) + (check ready) + (read latency) + (compute) =
= 5 + 50 + 5 + 1 + 40 + 5 = 106 micro sec
Throughput = 1/(56 micro seconds) = 17,857 requests/second
Utilization = (5 requests)/(56 sec) = 8.99%
- Direct Memory Access (DMA):
while(1) {
write command to disk
block until interrupt
check if disk is ready
compute
}
Latency (micro seconds) = (block int.) + (handle int.) + (check ready) + (compute) =
= 50 + 5 + 1 + 5 = 61 micro sec
Throughput = 1/(11 micro seconds) = 91,000 requests/second
Utilization = (5 requests)/(11 sec) = 45%
- DMA + Polling: Rather than blocking until interrupt, you let someone else do useful work.
while(DMA slots not ready)
schedule();
Latency (micro seconds) = (waiting) + (check disk) + (compute) =
= 50 + 1 + 5 = 56 micro sec
Throughput = 1/(6 micro seconds) = 166,667 requests/second
Utilization = (5 requests)/(6 sec) = 84%