^ ^ ^
CS111 Lecture 10:
File System Performance
UCLA Spring 2014
Professor Paul Eggert
May 5, 2014
Scribed by Andrew Wong & Eddie Yan
Deadlock
While the general idea of deadlock has already been established (i.e. a state in a program at which nothing can happen), a more formalized list of conditions required for deadlock is as follows:
1. Circular waiting: If one process is waiting for a second process that is waiting for the first process, the result will be a circular wait loop in which no process can move forward.
2. Mutual exclusion: While one process is running
with its resource, another process cannot be running with that same resource.
Without mutual exclusion, there would be no deadlocks.
3. No preemption of locks: If a process has a lock,
it cannot be forcibly revoked from the process, otherwise a deadlock would be
easily avoided just by revoking the lock held by the problematic process.
4. Hold and wait: A process must be able to hold a
lock and be in a waiting state for deadlock to occur. Deadlock will occur if a process is locking some resource while waiting for another condition that will never come true.
Every one of these conditions must be true for deadlock to occur.
Thus, to avoid deadlock, just one of these conditions needs to be guaranteed
false. Attacking the first condition, circular waiting, is a popular choice.
Wait-For Graph Solution
A method of avoiding circular waits involves maintaining a
"Wait-For-Graph."
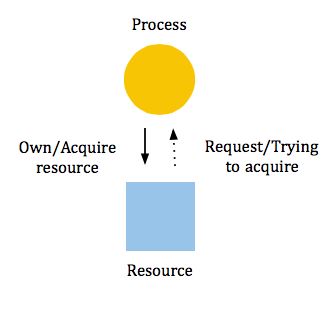 If a cycle were to appear in the graph, it would be possible for deadlock to occur. If, however, we check for loops in our graph before trying to acquire a resource, as shown below, there would be no way for a circular wait to happen.
If a cycle were to appear in the graph, it would be possible for deadlock to occur. If, however, we check for loops in our graph before trying to acquire a resource, as shown below, there would be no way for a circular wait to happen.
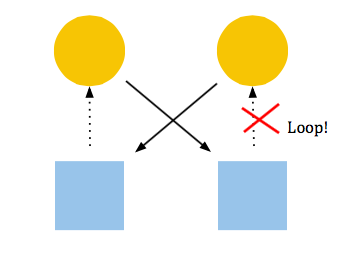 This is a valid solution, and it will work, but what is its runtime? Every time we want to acquire something, we would have to check through the entire graph to see if the request would add a cycle, and with a large number of process and resources, this could be costly, depending on the size of the graph, perhaps reaching O(P * R). If possible, we would want something to run much faster, O(1) if possible, especially if we're doing something as trivial as adding one to a bank account (See Lecture 8).
This is a valid solution, and it will work, but what is its runtime? Every time we want to acquire something, we would have to check through the entire graph to see if the request would add a cycle, and with a large number of process and resources, this could be costly, depending on the size of the graph, perhaps reaching O(P * R). If possible, we would want something to run much faster, O(1) if possible, especially if we're doing something as trivial as adding one to a bank account (See Lecture 8).
Lock Ordering Solution
Another possible solution will grant us this desired speed: lock
ordering. The idea is to impose an order of locking (e.g. ordered based on
machine address of locked resource). A process that locks more than one
resource must lock the resources in a fixed order. The process will keep
locking the resources until one of them is busy, at which point, it will give
up all of the locks and start over. The benefit to this is that it
eliminates the possibility of the "hold and wait" condition necessary for
deadlock to occur, in O(1) time, just by checking if the resource was available
or not.
But this runtime comes at a price. This method depends on all of the processes behaving
properly e.g. only obtaining locks in the specified order. Thus, this approach is
much less convenient than our original, slower, Wait-For Graph method, for
developers who might want to use the resources.
Quasi-Deadlock
Quasi-deadlock is like deadlock, but instead of hanging and doing
nothing, the CPU is doing nothing useful, or not performing the intended
task.
Priority Inversion
One type of quasi-deadlock is priority inversion, which killed off the Mars Pathfinder in 1997.
Fundamentally, priority inversion is problematic because it prevents
critical processes i.e. those with high priority from acquiring the CPU.
It is tricky to debug because the parts, when examined individually, are fine, but once they are put together, there is a small chance for failure.
Priority inversion can only occur in a system that uses a
preemptive scheduler with priority. Additional conditions must also be met
(everything must go wrong in precisely the right way) for priority inversion to
occur. For example, say we have three priorities: low, medium, and high, where the low priority task is runnable and the other two are waiting. The low priority task, since it currently has the highest priority among runnable tasks, will run and acquire some resource.
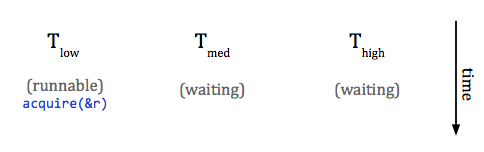 Next, something causes the high priority task to become runnable. This will cause a context switch to the high priority task, but since the desired resource is locked, it will wait and return control to the highest-priority runnable task.
Next, something causes the high priority task to become runnable. This will cause a context switch to the high priority task, but since the desired resource is locked, it will wait and return control to the highest-priority runnable task.
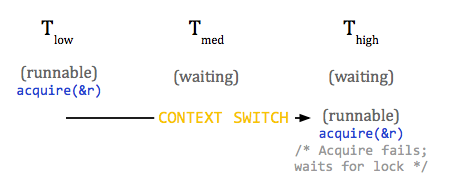 If, immediately after the context switch, the medium priority task
switches to the runnable state, it will be next in line to run. The high
priority task will hand control to the medium priority task and be stuck waiting
for the resource used by the low priority task. However, since the high priority
task is waiting on a resource held by Tlow, whatever important task Thigh needs to accomplish is stuck waiting, even though things are still happening (Tmed is running).
If, immediately after the context switch, the medium priority task
switches to the runnable state, it will be next in line to run. The high
priority task will hand control to the medium priority task and be stuck waiting
for the resource used by the low priority task. However, since the high priority
task is waiting on a resource held by Tlow, whatever important task Thigh needs to accomplish is stuck waiting, even though things are still happening (Tmed is running).
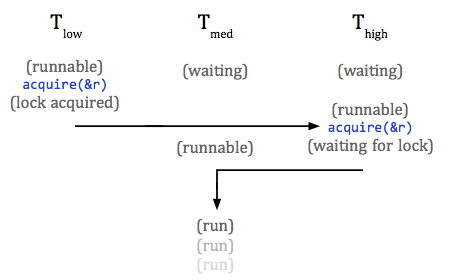
The solution: when a high priority task is waiting for a
lower priority task, lend the high priority to the low priority task, so the low
priority task is guaranteed to finish and grant the high priority task control
of the resource.
More info on the Mars Pathfinder incident
Receive Livelock
Another case of quasi-deadlock is called receive livelock and it works as follows. Suppose we have a bounded buffer of requests. When a request is received, the CPU has to stop its activity, follow an interrupt service routine to put the request into the buffer. This task of handling requests is high priority, so the CPU will stop its normal work routine to acknowledge these requests. This can lead to some strange behavior when processing a large number of requests, as illustrated in the figure below.
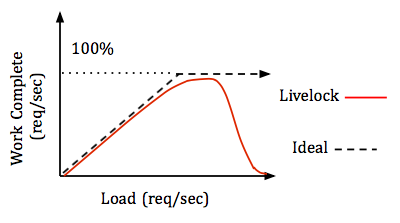
Ideally, the performance curve would asymptotically approach 100%
CPU capacity. The problem occurs when the bounded buffer is full and requests keep
coming in. This will happen when there is a large load of requests coming in at
once. The CPU will spend all of its time handling interrupts without actually
adding requests to the buffer, preventing the CPU from doing anything useful.
The solution: if the buffer is say 95-100% full, disable
interrupts until it's at a more passable capacity (say 50%). This will allow the CPU to focus on actual work when the request buffer is too full.
Aside: Hardware Lock Elision (HLE)
Another problem we encounter when we deal with locking is that a
lot of time is spent busy-waiting. So, as we've done throughout the course, we
can try calling the hardware guys at AMD. Their solution: Hardware Lock Elision.
The idea is to give users the effect of having the lock without actually getting it. The CPU charges ahead without acquiring the lock, and only at the very end does it commit to memory. An example of this functionality is shown:
Locking:
movl $1, %eax
try: xacquire lock xchgl %eax, global_lock
cmp $0, %eax
jmp try
ret
Unlocking:
xrelease movl $0, global_lock
ret
The xacquire keyword tells the CPU to go ahead and execute commands, but to not write anything to memory just yet. Only at xrelease does the CPU try to commit its data. This frees the CPU from all the busy-waiting it would do otherwise if it were locking as usual.
More info on how Intel does HLE
Hardware Lock Elision is an example of speculation,
whereby instructions are executed without confirming that a task should or need
to be performed. If the prediction was correct, then speculation can improve
performance.
Aside: Event-Driven Programming
"Data races are evil."
With this entire discussion of locking, the fundamental problem
is that we want 2+ threads running at any time. If we could find a way to not
use multiple threads, all of these problems caused by races would vanish. So a
natural thought might be to just use one thread. We still want to be able to
wait for events, as long we don't have the data races. To accomplish this, we
use something called event-driven programming, which has a general
single-threaded structure as follows:
while(true) {
wait_for_some_event e;
/* Note that this is the only wait that happens */
e->handler(e);
}
From this general framework, it is clear to see that there are no
locks, and therefore, no bugs due to locking, and therefore, no deadlock. On the
other hand, handlers are restricted to being fast in order to prevent any CPU
hold-up. Thus, large jobs may need to be broken into multiple handlers.
Additionally, things cannot be scaled via multithreading since there is no way
to manage critical sections. However, it can be argued that it is
inevitable that some applications need to scale using multiple processes
anyway, so we can just cut out the middleman and scale using multiprocessing,
keeping things simple for software engineers.
Node.js is an example of a software framework designed
with Event-Driven Programming principles.
File System Considerations
Performance Ideas
Let us just consider an example file system with the given specifications:
- 120 PB on 200,000 hard drives (each 600GB)
- General Parallel File System
Given this, let us come up with some performance ideas.
1. Striping: If we're trying to get a lot of data
very quickly, we can cut it into pieces and put each piece on a separate disk.
With this, we will be able to read and write in parallel, and our reads of a large amount of data spread over N disks will be N times faster.
2. Distributed metadata: Say we have some
metadata that stores important file information like location, ownership,
and timestamp. Rather than having a single master data node that has access to
this metadata, we distribute this metadata so that requests for metadata do not
need to be handled by a single node.
3. Efficient directory indexing: Suppose we have a
directory that has 10,000,000 files in it and we want it to work efficiently. If
we were to represent this as 10,000,000 child nodes of the parent directory
node, something as simple as 'ls' might take a while. Instead, it would be smart
to have another internal data structure, perhaps a B+ tree, so we can cut down the runtime of such operations.
4. Partition awareness: Imagine a scenario where we
have our cloud of nodes, but somebody tripped over a wire and now one of the
client nodes is partitioned from the rest. Since each node has metadata, it
would be problematic if both partitions acted independently from one another and
became desynchronized. Thus, by convention, in these
cases, the largest partition stays live, with full read/write support, and the
smaller partitions can only read.
5. Online maintenance: It would be very annoying
if, during file system maintenance, clients were not able to access their files. Staying online during maintenance would be a very nice feature to have.
It should be noted that essentially all of these issues deal with performance. Therefore, it would be helpful if we had some performance metrics to measure the quality of our file system.
Example Device
Suppose we have a system with the given specifications:
- CPU cycle time = 1 ns
- Programmed I/O (PIO): 1000 cycles = 1 µs
- Send command to secondary storage device (SSD): 5 PIOs = 5 µs
- SSD latency = 50 µs
- Computation per buffer = 5 µs
- Read 40 bytes from SSD: 40 PIOs = 40 µs
- Blocking interrupts/Scheduling = 50 µs
>> A simple implementation to read from our files and do something interesting with the data is as follows:
for(;;) {
char buf[40];
[read 40 bytes from SSD into buf]
compute(buf);
}
Given this, we can calculate some metrics as defined in the previous section.
Latency: 5 µs (send cmd to SSD) + 50 µs (SSD latency) + 40 µs (read latency) + 5 µs (compute) = 100 µs
Throughput: 1 request / total latency = 10,000 requests/sec
CPU Utilization: 5000 cycles / 100000 cycles = 5%
>> To improve throughput and utilization, we might want to try to maximize our time spent doing useful things by batching our reads, getting many blocks of data per a one request.
for(;;) {
char buf[840];
[read 840 bytes]
for(i = 0; i < 21; i++)
compute(buf + i*40)
}
Latency: 5 µs (send cmd) + 50 µs (SSD latency) + 840 µs (read latency) + 105 µs (compute * 21) = 1000 µs
Throughput: 21 requests / latency = 21,000 requests/sec
CPU Utilization: 105 µs / 1000 µs = 10.5%
>> Another thing we might want to try is using interrupts. If we let our CPU do some other work while we wait for an interrupt, we can still see a similar improvement as with before, but without the cost of increased latency.
for(;;) {
[block until interrupt]
do {
[handle interrupt]
} while(!disk_is_ready)
}
Latency: 5 µs (send cmd) + 50 µs (block) + 5 µs (handle interrupt) + 1 µs (check ready [PIO]) + 40 µs (read latency) + 5 µs (compute) = 106 µs
Throughput: 1 request / non-parallel latency = 1 req / 56 µs = 17,857 requests/sec
CPU Utilization: 5 µs / 56 µs = 8.9%
>> Going even further, we could take this idea, but only do direct memory accesses (DMAs). There is no need for PIOs if we only want to do some computation with our data since it is still on disk.
while(1) {
[write command to disk]
[block until interrupt]
do {
[handle interrupt] /* Put data into buffer and compute */
} while(!disk_is_ready)
}
Latency: 50 µs (block) + 5 µs (handle interrupt) + 1 µs (check ready) + 5 µs (compute) = 61 µs
Throughput: 1 request / non-parallel latency = 1 req /11 µs = 91,000 requests/sec
CPU Utilization: 5 µs / 11 µs = 45%
>> If we take the previous method and, instead of interrupts, we use polling, we can free the CPU so it does not have to handle interrupts.
while(1) {
[write command to disk]
while(DMA slots are not ready)
schedule();
compute();
}
Latency: 50 µs (schedule) + 1 µs (check ready) + 5 µs (compute) = 56 µs
Throughput: 1 request / non-parallel latency = 1 req / 6 µs = 166,667 requests/sec
CPU Utilization: 5 µs / 6 µs = 84%
These are just a few ideas to improve file system performance. Lecture 11 will cover actual implementations of file systems.
UCLA, Spring 2014