By: Luna Li
Overview
1. Safely Removing Data from Disk
2. Levels of a Traditional Unix File System
3. Inodes
4. Hard Links
5. Disk Formats
Safely Removing Data from Disk
Let's go back to our paranoid professor example. The professor now wants you to come up with a way
to safely remove sensitive data from file system so that it cannot be restored by malicious attackers.
Problem: How do we safety remove data so that the data cannot be restored?
Here are some ideas:
1. $rm file
Why does this not work? It does not work if some process calls open("file", ...) during the rm
call because the process still has the file descriptor for that file.
2. $reboot
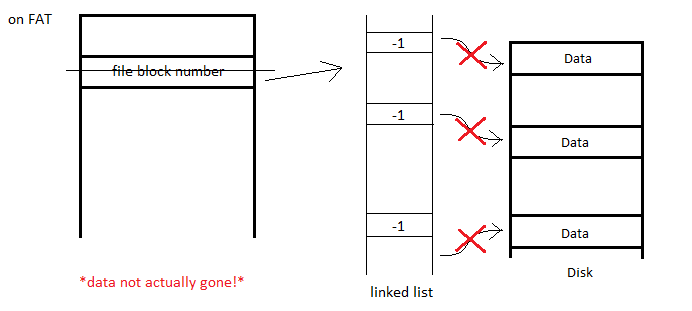
We can try to reboot to get rid of the previous problem but since rm only unlinks the file entries from the
inodes (performance reasons), it does not actually remove the data and therefore the data still exists on disk
(and can be recovered).
3. $shred file
This command overwrites the contents of the file with random data. This raises the question: "why not just
overwrite with zeros?" To answer this question, we must understand the low level structure of the disk.
Let's assume we have a classic hard drive where the disk head does
not write perfectly on the disk tracks. If the person trying to retrieve the data knows that all bit being written
are zeros, it makes it easier to read the ghost of the old data. If random data is written instead, it will be
harder to decipher the old data.
So we want to write random data to overwrite the old data but where does the random data come from? There are several
options:
a. /dev/random
This method gets random data from an entropy pool (shared system-wide random buffer). The entropy pool is filled from "random" external events like keystrokes of the time of day. Because this makes it a limited resource, it is very slow (a demanding process like shred could use up all the data from the pool very quickly).
b. /dev/urandom
This method is basically /dev/random but has a limitless entropy pool (i.e. Pseudo-Random).
Side Note: There is a relatively new architecture on x86 (Haswell) that has the RDRAND instruction that utilizes low level methods like thermal energy and noise to get random bits. This method is fast but can still fail (still limited).
In the end shred still finds /dev/urandom slow so what it actually does is it seeds its own pseudo-random number
(a high performance user space pseudo-random number specifically written for shred) with /dev/urandom.
Shred traditionally repeats the process of overwriting 3 times to unsure that the data cannot be read.
There is a standard for deleting data called US FIPS (United States Federal Information Processing Standards).
The following are some of the methods of deleting data starting from the highest (safest) level:
1. melt hard driveDamaging the drive will indeed remove that data but we still want to use the disk after removal. (The professor does not have the money to buy a new disk each time he wants to remove data safely).
2. physically shred drive (using special hard drive shredders)
3. degauss the drive (de-magnetize) - this damages servo control data (needed to move read/write head). The servo control data is written once by the manufacturer and never overwritten. Degaussing removes this, rendering the hard drive unusable.
4. overwrite with random data (typically 3 times)
*the top three in the list break the hard drive permanently.
So does overwriting with random data 3 times enough? No.
Why? Let's suppose we have a log-based file system. This means that when you do a write, you don't actually modify that data, you log the changes somewhere else (for performance reasons). This means that shred will not work since the write will just be logged. The actual data will not be overwritten.
How do we solve this? We can erase the whole file system:
$su // become superuser#shred /dev/rst0 // shred file system
Is this completely safe? Surprisingly, still no.
Why? Let's suppose we have bad blocks. The file system keeps track of these bad blocks as they become bad. It typically allocates a space at the beginning of the disk sectors to store the information of which sectors are bad and redirects it to a location at the end of the disk specifically allocated for bad block redirects.
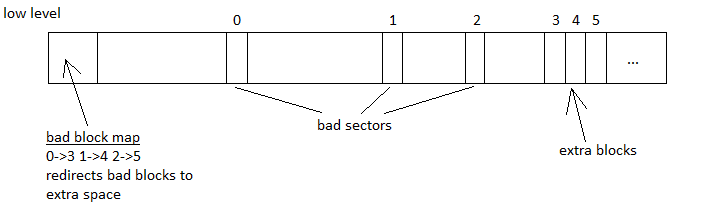
This means that data could still be located in the bad blocks (before they became bad) and could potentially be recovered by malicious attackers since our file system redirects bad blocks to the extra spaces.
What is illustrated here is that it is very hard to completely remove data (without damaging the disk). For most general purposes, overwriting three times with random data is sufficient.
Levels of a Traditional Unix File System
How can we free space in the Unix file system?
If we left information on each block, we would need to compute which blocks are in use and which are not. This would be expensive.
A way to make performance better is to use a free space table that stores whether or not the block is free. This can easily be done with FAT but what about Unix??
To solve this, there is what is called the Berkeley Fast File System: or the BSD Fast File System that is used by Unix. The structure is shown in the following image:

So the free block bitmap will take care of keeping track of free blocks but how much additional overhead does storing this table require?
Let's assume our disk is 4GB. This means 232 bytes. If each block is 8KB (213 bytes) that means we have 232/213 = 219 blocks on the disk.
Since we keep track of each block using a single bit, we divide this number by 8 (since there are 8 bits per byte) to find how many bytes it takes to keep track of 219 blocks.
219/23 = 216
So it takes 216 bytes to keep track of all the blocks in a 4GB disk. This is 216/232 or 1/216 of the disk, a very small amount.
Side Note: the bitmap is cached which introduces the cache coherence problem: making sure all copies of the data are synced within the system.
What are the advantages and disadvantages to this approach?
+ cheap to find free blocks
+ fast to allocate storage
- I/O is required to alloc or free
Minimizing seek time
Typical disk: average seek time = 10ms + rotational latency = 1/120 = 8ms.
When growing a file, we want contiguous data (speeds sequential I/O if there is no other activity).
Inodes
|
What's in an inode
- size - type (e.g. directory, regular file) - number of links - date - permissions - address of data blocks |
What's not in an inode
- filename - parent directory - which processes have the file open Why not? performance and security. If the system crashes the tables will not be accurate and reboot clears all data anyway. |
Hard Links
Argument against hard links
- complicates user modelQ. So why have hard links in the first place?
- inconsistency on parent directory name
- can only be created on files on the same volume (symlinks don't have this limitation)
- loops are possible? (not in Unix)
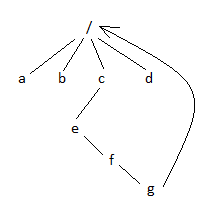
A. Renaming is hard; let's stop it.
Renaming is vulnerable to crashes:
rename("d/a", "e/b"); // modifies both "d/a" and "e/b"
If the system crashes, there is likely chance for lost or partial data (something the user does not ever want) since we are modifying our original file while we are renaming.
Linking is less vulnerable since it only modifies one copy at a time:
link("d/a", "e/b"); // modifies "e/b"unlink("d/a"); // modifies "d/a"
Let's go over this code briefly.
link("d/a", "e/b");
This creates a hard link (directory entry) "e/b" that links to the same inode as "d/a". It increases the link count of the file's inode so that we know there are two files with the same inode.
unlink("d/a");
This decrements the link count on the inode and removes only the directory entry for "d/a" from the file system.
So if the system crashes, there will still be a complete copy (either old or new copy) and the system can recover.
Q. How do we avoid hard link loops?
A. Prohibit hard links to directories.
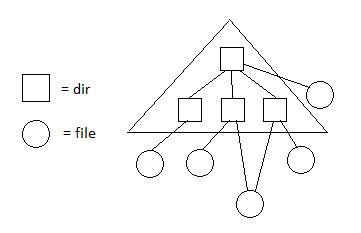
Fun stuff with hard links
With hard links we can do stuff like create copies of data like when we clone in git.
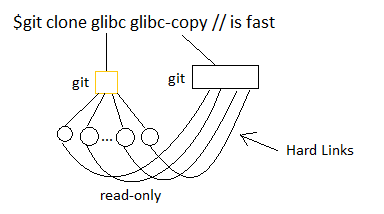
*FAT does not support hard links
Because the clone is made up of hard links, the copy is not a backup.
Disk Formats
ext2 directory entry
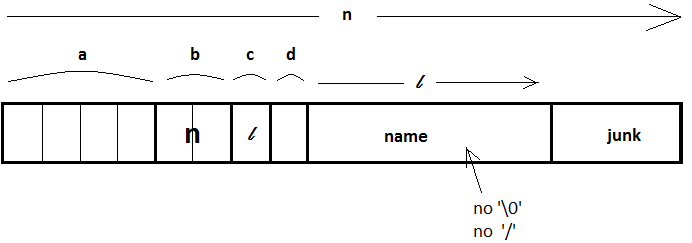 The separate portions of an ext2 directory from the above diagram are explained below:
The separate portions of an ext2 directory from the above diagram are explained below:
a. 32-bit inode (4 million files)
b. 16-bit directory entry length
Why do we need this if we can use the other parameters to calculate the sizes of the important bits?c. 8-bit name length, l <= 255
In other words, why do we need to know the size of the junk bits?
Let's assume we have the following array of varying length directory entries.

To simplify the unlinking process for a directory entry, we simply specify that the directory entry being removed is junk for the previous directory entry. To do this, we simply change the 16-bit directory entry length to encompass this additional junk. This is why the total length of the directory entry must be known.
d. 8-bit file type <-- also in inode (cached inode data) This is ok since file_type is immutable-directory
-regular file
-symbolic link
-device
...