CS111 Lecture 12: File System Implementation Issues
by Gagik Movsisyan, Simon Liang, and Ming Wei Lim | Spring 2014 UCLA
Table of Contents
- Securely Deleting a File
- Why not overwrite with zeroes?
- Where does the random data come from?
- Data Deletion Standards
- Things that can go wrong
- Levels of a Unix File System
- More on Unix File System
- Computing Free Space
- Inodes
- What is in an inode?
- What is not in an inode?
- Hard Links
- Arguments against hard links
- Why do hard links exist?
- Fun stuff with hard links
We want rm to be fast on a FAT file system
FAT file system
$ rm file
$ reboot
One option is the following:
set free block flag = -1
However, the data remains. The question is: how do we securely remove a file?
We can use the shred command which overwrites the contents of a file with random data.
$ shred file
By default, shred overwrites the file three times. The idea is that the contents of a file can potentially survive a single overwrite but have a very low chance of surviving three.
Aside: Why not overwrite with zeroes?
In a classic hard drive, the disk arm attempts to write to the center of each track but varies slightly depending on the data written. If a file is overwritten with zeroes, it is possible to read the "ghost" of the previous writes to the track by examining these variations. However, if we overwrite the file with random data, the track will be much harder to read and obtain useful information from.
Analogy: To cover up graffiti, it's better to cover it up with more graffiti than with white paint. With white paint, you'll still be able to see traces of the graffiti under it. With new graffiti, it will be much harder to identify or find traces of the old graffiti.
Aside: Where does the random data come from?
/dev/random: system-wide random buffer, entropy pool, from "random" external events (type a keystroke, move mouse, etc)
Downside: limited resource (waits for random user input if the buffer runs out) so shred will be slow if /dev/random is used
/dev/urandom: magic random entropy pool that never runs dry = LIMITLESS!
Uses a psuedo-random number generator (hopefully you can't tell)
RDRAND: newer Intel chips have this instruction that uses thermal energy/entropy/noise to fill registers with random bits.
...and if you're super paranoid, you can xor the result of RDRAND with /dev/random
Note: shred has its own psuedo-random generator because /dev/urandom is
still too slow
Data Deletion Standards
U.S. Federal Information Processing Standards (FIPS) provide us with a way to classify levels of secure data deletion.
The Highest Levels:
1. melt the drive (e.g. in a blast furnace)
2. physically shred the drive (with a literal hard drive shredder)
3. degauss the drive (wipe it with a really strong magnet)
The downside to these deletion methods is, of course, the inability to reuse the drive after securely deleting the drive's data.
For less sensitive data deletion, overwriting the drive with random data will suffice. The exact number of overwrites required, however, is still unclear. There has been little research regarding this topic though many standards seem to suggest around three overwrites. For now, let us assume that overwriting three times is sufficient.
Things that can go wrong
Log-based file systems log the changes to files instead of immediately writing to the file. This method of batching generally increases the throughput of writes, though reads might take a little longer though since the system has to check the log first before the actual file.
This also means shred doesn't work! Shredding means nothing when the log can still have bits and pieces of the file still hanging around.
Solution: Shred the entire partition:
$ su
$ shred /dev/rst/0
BUT there's still a problem!
Disks are inherently flaky and contain a number of bad blocks (they also accumulate bad blocks over time simply due to use). For each one of our bad blocks, the disk has a bad block map/table which will tell us where the good block with the data you want is. The good blocks are simply extra blocks the system reserves for the purpose of replacing bad blocks. When the partition is shredded, it is possible to actually read the data stored in the "bad blocks" simply by looking in the extra blocks.

Each bad block will point to a block in the reserved extra blocks.
Symbolic Links
|
File ids
(aka pathids) "/path/to/example"
|
File id Components
For the path /path/to/example,
the file id components are "path", "to", and "example"
|
| Inodes |
----------------------file system boundary------------------------------
|
Partitions
e.g. boot partition, swap partition, /usr/disk; each partition is
treated independently and each one can have a different file
system or no file system at all |
Blocks
e.g. 8192 byte blocks |
Sectors
e.g. 512 byte sectors
|
Computing Free Space in a Unix File System
 Solution 1:
Solution 1:
One way to compute this is to compute the number of blocks in use and calculate the difference of {All_Blocks} - {Blocks_In_Use}. However, it is very expensive to compute the number of blocks in use. We need a more efficient way.
Solution 2:
Use a free space table! With a FAT file system, this is easy. We just need to check if an entry in the table is -1. If it is, then the block is free.
How is this done for the Unix file system? Use a free block bitmap! (refer to the figure on the right)
A free block bitmap is a storage-efficient way to manage blocks of storage on a disk as it only takes up 1/2^16 of disk space. Each bit in the bitmap corresponds to a block of data. Depending on how the bitmap is implemented, the bit's value will indicate whether the corresponding block is free or in use which makes it very cheap to determine the availability of a block. With the bitmap, it is also very fast to allocate or free storage as it is as simple as flipping the value of the bit. One disadvantage of using a bitmap is that I/O is required to access the free block. For a typical disk, the average seek time is around 10 milliseconds and rotational latency is around 8 milliseconds. This means that a seek takes roughly 18 milliseconds which is quite slow! The best way to improve on this is to reduce fragmentation.
Inodes
 What is in an inode?
What is in an inode?
An inode stores metadata information about a file.
This includes the size of the file, the type of the file (directory, regular, or symbolic link), the number of hard links to the file, the timestamp of the file, any permissions granted to the file, and the block numbers of the data blocks corresponding to the file.
The block numbers are stored in an array inside the inode structure. Typically, an inode can directly store 10 different block numbers (10 slots of the array) which is sufficient for small files. However, for larger files that use up a lot of blocks, more space is required to store their block numbers.
To do this, an additional disk block can be allocated for the sole purpose of holding block numbers. In the inode, the 11th slot of the array will point to the first slot in the newly allocated block. This is called a doubly-indirect block. For even larger files, a triply indirect block can be used.
What is not in an inode?
The fileid is not stored in the inode. Why?
A file with multiple hard links can mean that there are multiple ids to the file. Every file corresponds to exactly one inode, so it wouldn't make sense to store the file id inside the inode.
Instead, the fileid is stored in a directory entry which also stores the inode number of the corresponding file. The parent directory is also not stored in the inode for the same reasoning. Lastly, a record of which processes have the file open is also not stored in an inode. This is because it will lead to bad performance since a process will have to write to disk each time a file is opened, and a reboot will clear all the processes anyway which makes the procedure impractical. Having a record of which processes are using the file also makes the file less secure.
Hard Links
Hard links are a mechanism that allow a single file to have multiple ids.
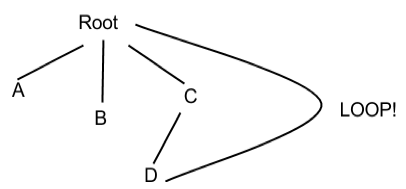
Prohibit hard links to directories in order to avoid loops!
Arguments against hard links
Critics of hard links will say that it complicates the user model. Users will need to be aware of hard links which causes overhead. Without hard links, it would be easy to compute the fileid and its parent directory since one file can have one and only one fileid. Lastly, hard links introduce the possibility of loops (refer to the example on the right) which can lead to all sorts of trouble.
Why do hard links exist in the first place?
Renaming files!
Without hard links, renaming files is difficult. Consider the following example.
reid("d/a","e/b"); //without using hard links
This modifies both the "d" directory and the "e" directory which makes it vulnerable to crash!
Now, let's reid using hard links:
link("d/a","e/b"); This only modifies the "e" directory.
unlink("d/a"); This only modifies the "d" directory.
The advantage of using link and unlink with hard links is that it only modifies one file per command so it is less vulnerable to crashes.
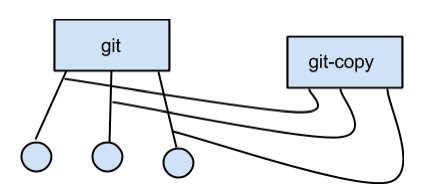 Note that the clone is hard linked and does not act as a back up!
Note that the clone is hard linked and does not act as a back up!
Fun stuff with hard links
Suppose you have a copy of the GNU C Library.
$ git clone glibc glibc-copy //very fast!