CS111 - Lecture #12 - File System Implementation Issues
May 12, 2014 (Spring 2014) - Prashanth Swaminathan
Topics covered in this lecture:
- Levels of a File System - Exploring By Application
- File System Levels - Overview
- Determining Free Space In File Systems
- Inode Structure
- Arguments Against Hard Links
- Directory Entry Structure (in ext2)
File System Levels - Exploring by Application
Recall the paranoid professor introduced a few lectures ago? Now suppose that his newest problem is to remove data from a filesystem, so no one can recover and read it. We will explore each possible solution and note its problems:
$rm file- While this might delete the file eventually, what if another process was already holding the file descriptor?
On FAT systems and systems that utilize free block bitmaps, a file is removed by setting all blocks it was using to
'free' in the free block bitmap. (This is what was done in Lab 3 in
free_blockfunction.) But we have a security flaw here. When the file is removed, we modify only the bitmap and not the data block itself! This means that even if we removed the file, a process with a file descriptor could still access the block and read whatever content remains. The only way to prevent this process from hanging onto the file is to$rebootimmediately, assuming that the process has not already written a copy of the file's data somewhere. In any case, this is too drastic and cannot practically be done every time a file needs to be removed. $shred file- The UNIX/LINUX solution to this problem is the shred command. Shred rewrites the contents of the file with
random bytes. After we delete the file, even if a process is holding onto a file descriptor for that file, it will
only be able to access garbage data.
Aside #1: Why does shred overwrite with random bytes, instead of zero bytes, which is much faster?
Some storage media can leave traces of information about the original contents of a sector. When a disk head writes on a sector it first attempts to center on the track, but can be slightly off. Peter Gutmann, who presented a paper entitled "Secure Deletion of Data from Magnetic and Solid-State Memory" at the 1996 Usenix conference, explained that the "actual effect is closer to obtaining a .95 when a zero is overwritten with a one, and a 1.05 when a one is overwritten with a one". Given some information about which bits were overwritten, and a sensitive disk head, we could theoretically reconstruct what data existed in the sector.
- If the data is overwritten with zeros alone, it would be a perfect signpost for a forensic scientist who could then examine that area of the track. Looking at the bits that show signs of not being 'fully' overwritten, the original sector can be read. This trail is sometimes referred to as the 'ghost track'.
- If the data is overwritten with random bytes, we cannot use the same logic to reconstruct the sector. While a few traces of the original data might be left, it is much more difficult to analyze. However, since shred cannot guarantee that expensive hardware probing will not be able to identify a 'ghost track', it shreds 3 times by default for increased security.
Most applications get random data from the system-wide entropy pool,/dev/random. In the Linux kernel this is a 'device file' that generates its data by looking at the keyboard, mouse, network, and disc activities, with a cryptographic algorithm (SHA1). Since it's purpose is to provide cryptographically secure pseudorandom numbers, /dev/random is a limited buffer. If too many random bytes are requested, /dev/random will exhaust and block until more entropy can be gathered. This makes it inefficient for use with shred. Instead, we use the limitless entropy pool,/dev/urandom. This is a pseudo-random number generator (PRNG) that seeds with a value from/dev/random. Here is one suggested way to get randomness for a PRNG, the RDRAND operation:
- RDRAND is an instruction available on the Intel x86 and x86-64 architectures to acquire randomness from the chip's thermal energy.
- Thermal energy is translated into random bits that are then passed through an AES conditioner (encryption) to create secure random numbers for applications. This is not the primary way by which /dev/random acquires its entropy, and it might have been a smart design choice; many critics suggest that the NSA might have inserted backdoors.
- Additional randomness can be attained by taking and XOR of /dev/random and RDRAND output.
Aside #3: What are United States policies for secure file deletion?
We refer to the US Federal Information Processing Standards (FIPS) on file deletion:- Security Level 1 (Lowest): Delete files by overwriting with random data (default 3 times).
- Security Level 2: Delete files by 'degaussing' the drive, basically bathing it in a strong magnetic field.
- Security Level 3: Delete files by physically shredding the hard drive.
- Security Level 4 (Highest): Delete files by melting the hard drive.
Log Based File Systems and Bad Blocks - Why Shred Isn't Enough To Delete Data
In a log based file system, data is not modified immediately; rather, a 'log' is posted and the update is done later as necessary.
A separate section of the partition holds a record of logs containing the differences between the old and new versions of the file.
Shred now no longer works! While it will overwrite the contents of the original file, the log containing the file differences
can still be read. So we propose to do this:
$su
#shred /dev/rst/0 // Shred the entire disk!
Now that we've shredded everything, are we safe? Nope. The reason is because of 'bad blocks' in a partition. Occasionally,
certain sectors of a disk will go bad; either permanent damage to the disk or failed transistors in flash memory render these
sectors unusable. To counteract this, whenever a bad block is detected, it is recorded in the 'bad block map'. This map redirects
the file system to a different block whenever it tries to access a bad block. Extra space is pre-approportioned on the disk to allow
recovery from bad blocks. The problem: these bad blocks are often stuck in their magnetic or digital state. Shredding is an overwrite
operation, and thus will have no effect on a sector that is already dead. All the data contained within these bad blocks can still
be read after a shred.
File System Levels - Overview
The main file system abstractions are (from coarse to fine):
- Sectors - 512 bytes
- Subdivision of a track on a magnetic disk
- Writes to disk must be at least 1 sector long
- Blocks - 8192 bytes (16 sectors)
- Larger block sizes are efficient for sequential calculations
- Smaller block sizes waste less space (when file sizes are smaller)
- Smaller block sizes also reduces the amount of disk fragmentation
- Partitions
- Disks might contain a boot, swap, /usr and unused partition, for instance.
- There is no requirement that partitions share the same file system type.
- Inodes
- File Name Components
- All parts of a file name except the slashes.
- e.g The file name components of /usr/bin/grep are "usr", "bin", and "grep"
- File Names (Path Names)
- The full path name of a file.
- e.g The file name of /usr/bin/grep is "/usr/bin/grep"
- Do not confuse this with the PATH environment variable.
- Symbolic Links
Determining Free Space In File Systems
In FAT file systems, free space is determined using the file allocation table which marks all free clusters with a -1. In Version 7 UNIX, no such table existed. To determine how much free space exists, you would have to check how many blocks are in use and then subtract from the total block count, which is an incredibly expensive operation. The solution that was created to solve this is the BSD file system created by UC Berkeley.
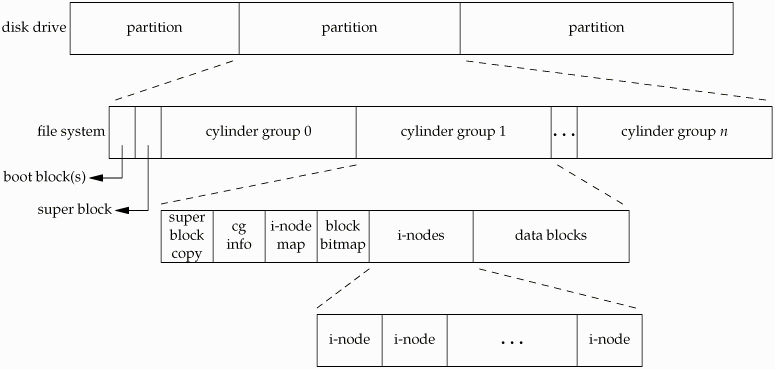
In the BSD file system, each individual cylinder group (part of the larger filesystem) contains a superblock, 'cg info' which contains file system descriptors, an inode-bitmap, a free-block bitmap, the inodes, and the data blocks. Specifically, the free block bitmap contains one bit per data block, with 0 indicating that block is free and 1 indicating that the block is in use. The existence of a free block bitmap and the inode bitmap gives us an relatively fast way to determine which blocks are free. Otherwise, we would have to parse through each inode and construct a bitmap each time we want to allocate a file.
Pros and Cons
+ Only 1/216 of the disk is used by adding the free block bitmap.
+ It is relatively fast to determine free blocks and allocate a file appropriately.
- I/O is required to know where to allocate the file.
- If a free block bitmap is cached in memory:
- We could get cache coherency issues; blocks that are marked as free might be in use, and vice versa.
- We would have to keep verifying the correctness of the free block bitmap.
However, building a file system this way allows us to more quickly determine how many blocks are free to write into continguously. The primary goal is to minimize seek time for the disk head. A typical disk takes about 10 ms to rotate into the right position and has to wait for the data to arrive for about 8 ms (rotational latency). If a file is written continguously, I/O is a lot faster because there is less rotation required by the disk head to read sequential data. (Assuming of course, no other activities, like other I/O operations, are requested by the file system.)
Inode Structure
| What's in an Inode? | What isn't in an Inode? |
|---|---|
|
|
Arguments Against Hard Links
Hard links can seem to be more trouble than they're worth sometimes:
- they complicate the user model
- if files are hard linked, removing one file will not reclaim the space allocated to it
- user has to keep track of which files are linked together in order to free data
- there would be no need for directory entries
- the purpose of the directory entry is to store the file name and directory separately from the inode
- if files could only have one name, that information can be stored directly in the inode
- they create the possibility for looping
- directories that circularly link to each other would be impossible to follow (see diagram on right)
- Unix prevents looping by not allowing you to hard link to directories.
So why keep around hard links:
- because renaming is problematic
- To rename we call
rename("d/a","e/b")- Modifies two files at once, what if the system crashes?
- Both files could be corrupted, rename is vulnerable to crashing
- Instead we use
link("d/a","e/b")and thenunlink("e/b")- This way only modifies 'e', if system crash occurs then you may at worst have two copies.
- Less vulnerable to crashing
- To rename we call
- because it makes certain operations faster
- If you do
git clone glibc glibc-copy, it copies all source files and commit history- Creating a series of directory entries that are hard linked to the original files is much less work than copying data blocks
- Does not serve as a backup, because the clone refers to the same blocks of data
- If two directory entries are linked and one is removed, FAT file systems would mark the data blocks as free; so FAT file systems do not support hard linking.
- If you do
Directory Entry Structure (in ext2)
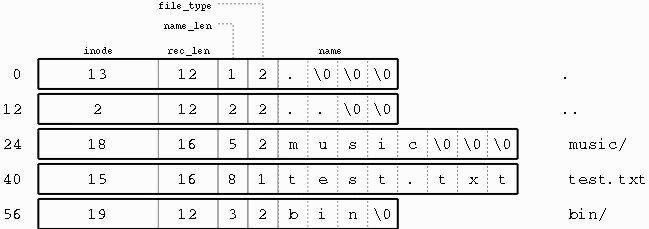
A ext2 directory entry contains the following fields in order:
- 32-bit inode # (up to 4 billion files)
- 16-bit directory entry length
- 8-bit file name length
- 8-bit file type
- (size defined by name length) file name that does not contain '/0' or '/'
- junk space (length can be calculated using directory entry length)
In the example diagram, note that some entries have extra zero bytes. These form the aforementioned junk space. The reason junk space exists is to make entry allocation and deallocation easier. Suppose we wanted to remove the fourth directory entry, test.txt. The method by which we deallocate this space is to look at the previous directory entry, music/ and increase its directory entry length by 16 (the size of the test.txt directory entry). This masks the test.txt directory entry as the junk space for the music/ directory entry. If instead we wished to add a directory entry, we would first find a directory entry with a large enough junk space and then shrink it to get the space we need.
Note that the directory entry and the inode both contain file type information. We have an inherent coherency problem; what if there are inconsistencies between the file type recorded in the inode and the file type recorded in the directory entry? Linux prevents this issue by making the inode's file type immutable. You cannot change an inode's file type and so at the very least, the file cannot be used by the file system incorrectly.