File System Robustness & Virtual Memory Introduction
Scribe notes from May 19th, 2014
File System Robustness
When we update a file, we want this update to be atomic. For example, if we update block 4 from A to B we want to see either A or B, not a mix of both. We also want to be able to recover from interrupted operations. If our system crashes half way through updating a file, we want to be able to restore the file system to its original state.
Improving File System Robustness
1. Commit Records
2. Journaling
Commit Records
Commit records are used to tracks operations done to a file system. Each commit record has details describing the operations of the commit. If the system crashes half through a write, these records can be used to restore the file system to its original state.
Journaling
A file system journal is a separate portion of the disk (or a different disk) that is used to record changes made to the file system. It can be thought of as an infinitely long array of records of what has been done to the file system. These records can be simple or complex. For example, an update of location (2, 4) to B, or 4 changes to 4 different locations.
In practice, journals are circular buffers. A record only exists in the journal until its operations have successfully made it to disk - after that, the entry in the journal becomes garbage (free space). If the journal fills up, the system will be throttled until space becomes available.
Figure 1: A diagram describing how a file system journal is used
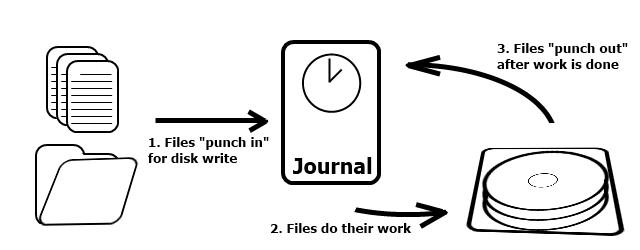
source: http://itsitrc.blogspot.com/2013/02/the-linux-file-system-one-must-opt.html
Logging in Journals
Logging Protocol 1
1. Log update before installing it in cell memory
2. Commit in log
3. Install changes into cell memory
Recovery Phase:
1. Scan through the log and look for actions that have been committed but have not yet ended.
2. Complete these actions one by one.
3. Once all actions have been completed, resume normal operation.
Advantages
If we don’t need the old values, logging protocol 1 saves a read operation. For instance, if we are about to write to some disk area and we don’t care about the current (old) values stored there, logging protocol 1 doesn’t require us to read.
Logging Protocol 2
1. Save old values in the log.
2. Write new values in cell storage.
3. Write a commit.
Recovery Phase:
1. Scan through the log backwards and undo actions that have not been committed. These are actions that have a “begin” record but don’t have a “commit” record.
Advantages
Recovery is often faster and simpler because it is easier to scan backwards and undo than it is to scan forwards and redo. This is because:
1. Logging Protocol 2 allows us to scan from right to left until the point at which all further records to the left have already been committed. As a result, we can stop the recovery process here.
2. On the other hand, Logging Protocol 1 requires us to scan all records from left to right regardless of whether or not the actions have been committed. Even if we were to scan from right to left in order to find the starting point, we still need to scan from left to right in order to complete the actions in order.
Performance improvements for a log-structured File System
1. Put the journal on a separate disk (device). Since the journal is append only, this minimizes unnecessary disk movements.
2. Don’t put the entire cell storage on disk. Instead simply cache the parts that are needed in RAM. This helps avoid seeks. However, there will be an expensive reboot phase if the system were to crash.
Interaction between Disk Scheduling and Robustness
The disk controller often reorders writes in order to group them based on their physical proximity to one another. This increases efficiency by reducing disk arm movement (thus increasing throughput etc.) However, it will interfere with our logging algorithms. As a result, we need our commit records to constrain disk scheduling. One possible approach is to store dependencies in both the operating system and the disk controller.
Virtual Memory Introduction
Problem: unreliable processes with bad memory references
Example 1 (dereferencing a null pointer)
char *p = 0;
printf(“%c”, *p);
Example 2 (out of bounds array access)
char buf[BUFSIZE];
print(buf[BUFSIZE]);
Ineffective solutions
1. Hire better programmers
- Problem: Too idealistic
- Problem: Too slow
- Problem: Also too slow
Simple Hardware Solution: Base and bounds register pair
1. The base register specifies a lower bound for the location of a memory access and the bounds register specifies an upper bound2. Accessing memory location A in process P's memory must satisfy: base <= A < bounds
Problems with this approach
1. Slow down due to runtime checking
- Nowadays, this will not cost CPU time but may cost some transistors and power
- We cannot grow memory flexibly
- The code cannot have absolute jumps; all jumps must be relative. Suppose that a program is allowed to access RAM in the OK1 region below and has an absolute jump to location 1000. This will work fine because location 1000 is within OK1. The problem can occur if another instance of the same program runs. The memory accesses for this second instance will be limited to a separate region of RAM (OK2). However, since this program is running the same code, it will also have an absolute jump to location 1000, which for this instance of the program is not a valid memory access.

A Better Solution: Segmentation
In this approach, instead of having 1 contiguous block of memory, a process has multiple segments, each with their own base and bounds register pair.
Example
If there are 8 segments per process, the upper 3 bits of a 32-bit memory address would be used to specify the segment number while the lower 29 bits would be used to specify the offset within the segment as shown below:

The segment number is used to get the base address of the segment from the process’s segment table (which stores other information such as the bounds address and permissions as well).The offset is added to the base address obtained from the segment table.
Some examples of segments an application might have
1. Text segment (read-only program)
2. Data segment (read-write data)
3. Stack segment (read-write data)
4. DB segment
Advantages of segmentation
Because memory is split into segments and does not need to be contiguous, it can be grown more flexibly. Segments can be grown independent of one another, without the need to move the entire process’s memory.
Segmentation also removes the requirement for programs to use only relative jumps in their code. Since each memory address now represents a segment number and segment offset, programs are free to jump to absolute addresses. Two instances of the same program which jumps to 0x1000 would not be jumping to the actual address 0x1000, but 0x1000 bytes into the 0th segment belonging to each process.
Disadvantage of segmentation
If a segment is too small, it needs to be grown. This requires runtime checking to determine if the bounds address can simply be incremented by the desired amount. If not, the segment must be moved to a continuous chunk of available memory that is big enough. Runtime checking and moving segments around are expensive.
An Even Better Solution: Paging and Virtual Memory
The problem with segmentation resulted from the variable size of the segments. A solution to this is to have fixed-size “segments” called pages. In general, these fixed-size pages are smaller than segments. Also, because the page size is fixed, a bounds register is unnecessary.
Example
A 32-bit memory address could be divided up as shown below:
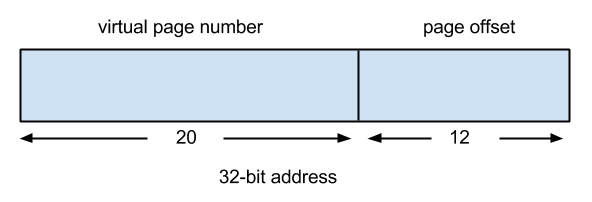
In this approach, each process has its own set of virtual page numbers. The virtual page number (VPN) is mapped to a physical page number (PPN) by the page table (discussed below). From the physical page number and page offset we can determine the physical address. From the process’s point of view, it has 232 bytes of virtual address space to work with, even if that much physical memory is not available.
Advantages
This approach is more flexible. Instead of growing a page as was necessary in the segmentation approach, memory can be added to a program in fixed-sized pages. It is no longer necessary to move things around. There are no problems with external fragmentation since pages are fixed-size.
Page Tables
Page tables are data structures that are used to map addresses from the virtual memory of each process to the physical memory stored in hardware. Each process has its own page table.
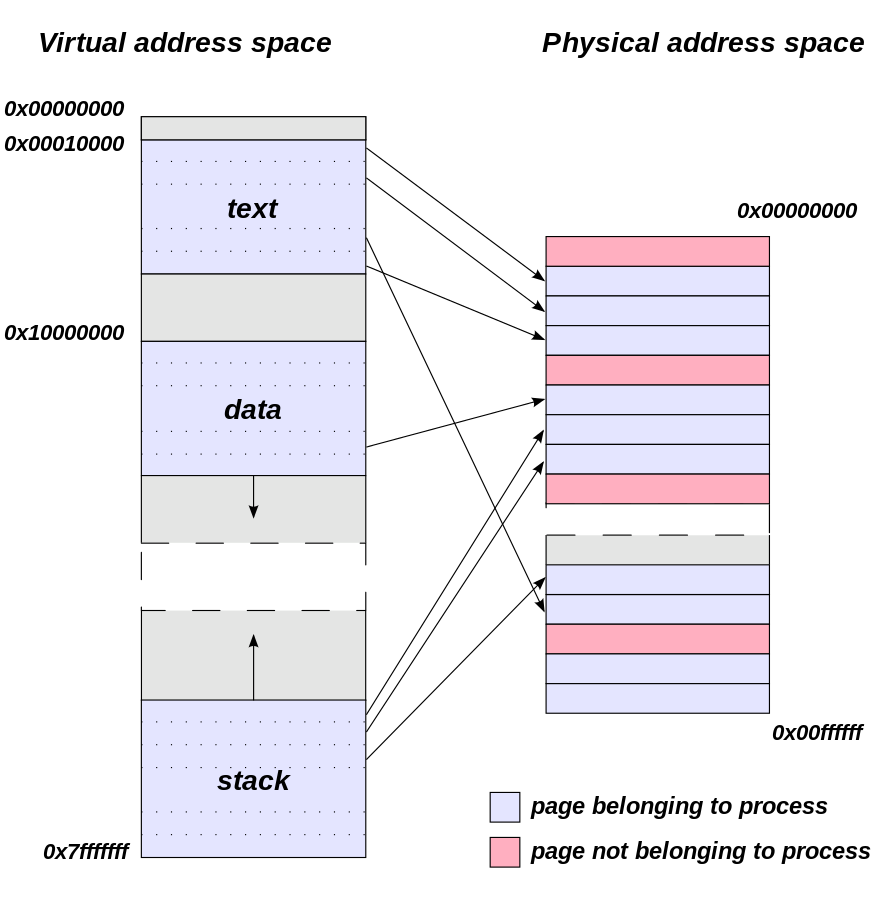
A simple page table in the x86 architecture could be modeled in software as follows:
int pmap(int vpn) {
return PAGE_TABLE[vpn];
}
If the hardware supports it, paging can be enabled by setting bit 31 of the %cr0 register to 1. Though each process has its own page table, from the hardware’s point of view there is only a single page table. The %cr3 register holds the address of the current process’s page table. It is the kernel’s responsibility to set this register properly when the address space changes (for example, after a context switch).
Page and Page Table Sizes
With a 32 bit virtual address (as shown above), the size of each page is 4KB (12 offset bits -> 212 bytes -> 4KB). Each entry in the page table is made up of a PPN (20 bits in this case) and flags (12 bits). These flags include read/write permissions, among other things. Since each page is 4KB, the number of pages in a 32 bit address space would be 232/212 = 220 pages. Each page table entry is 32 bits, or 4 bytes, so the size of a page table is 4 * 220 bytes, or 4MB.
Modifying a Process’s Page Table
A process can modify its page table using the mmap system call. Allowing modification of a process’s page table could lead to security issues, but since mmap is a system call, control is transferred to the kernel which prevents dangerous or invalid values from being stored. Thus, processes may modify their page table but only in the ways allowed by the kernel.
Multilevel Page Tables
Since each process has a 4MB page table, a system with many processes would waste lots of memory space just on page tables. For processes with very little memory usage, loading the entire 4MB page table into memory is especially a waste, since most of the table’s entries would be unused. A solution to this problem is multilevel page tables. By dividing page tables into pages, much like memory is divided into pages, we avoid the problem of loading unused or unnecessary portions of a process’s page table into memory. For example, programs often access the lowest and highest addressed portions of virtual address space (text and data segments are at low addresses, while the stack is at high addresses). With multilevel page tables, the page table entries that represent the free, unused, space (holes) in between the low and high portions of the program’s virtual address space would not need to be loaded into physical memory. This concept is illustrated below.
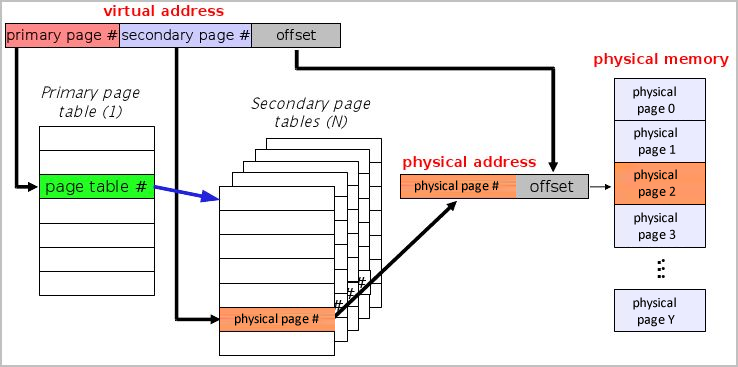
A simple multilevel page table in the x86 architecture modeled in software as follows:
int pmap(int vpn) { int lo = vpn & (1 << 10) - 1; int hi = vpn >> 10; int pte1 = PAGE_TABLE[hi]; //this gives us the address of the second level page table if (!pte1) return OUCH; int pte2 = (int*)pte1[lo]; if (!pte2) return OUCH; return pte2; }
A technical term for “OUCH” is page fault.
Page Faults
A page fault occurs when a process tries to access memory that it doesn’t have the rights to. For example, trying to access a page that doesn’t exist (or is on disk), or trying to write to a page it doesn’t have permission to write to. When this happens, the hardware traps, much like the INT instruction.
Once the trap occurs, the kernel decides what to do with the program. It may:
1. Load the desired page from disk into memory
2. Terminate the program
3. Send SIGSEGV to the program
By default, programs will terminate if they receive SIGSEGV. However, a signal handler can be provided which will catch this signal and do something else. The program cannot simply do whatever it wants in the signal handler. The handler will go through the same virtual memory checking that the original code did, so any invalid memory accesses in the signal handler will trap again.
Handlers for SIGSEGV must do something reasonable. Options may include:1. Print out an error message and die
- SIGSEGV handlers should avoid unsafe operations like memory allocation (malloc, calloc). The cause of the SIGSEGV could have been a memory allocation error, so attempting to allocate additional memory will create more problems. Signal handlers should use only async-signal-safe functions as specified by POSIX.
- if a SIGSEGV occurs when running off the end of an array, just make the array bigger and keep going. The Bourne Shell used this approach.
The reason behind the Bourne Shell taking approach 2 is performance. When this approach is used, there is no need for the software to repeatedly check if it needs to allocate more memory - the hardware catches it and the signal handler allocates more memory. This approach however is considered bad style, and is very hard to debug: when a segmentation violation occurs in a program, it is difficult to tell the cause (buggy program, out of bounds array access, etc.).
Though allocating memory with malloc and calloc is not signal safe, the Bourne Shell used the sbrk system call (which modifies the end of a program’s data segment), which is signal safe. In fact, on many systems, malloc is written atop the sbrk system call.
Swap SpaceIn Linux, when memory is full, a swap space is used to “increase memory size.” A swap space is placed on disk and uses RAM as its cache. In theory, using a swap space works well, but the problem is that disk access is slow. In practice, there will be too much thrashing (when pages get swapped out too often) and performance will decrease dramatically.
References
http://en.wikipedia.org/wiki/Page_tablehttp://en.wikipedia.org/wiki/Control_register
http://www.eecs.harvard.edu/~mdw/course/cs161/notes/paging.pdf
http://itsitrc.blogspot.com/2013/02/the-linux-file-system-one-must-opt.html